
Integrating K8sGPT to empower Kubernetes with AI in HPE GreenLake for Private Cloud Enterprise
July 9, 2024This blog post describes the process to integrate K8sGPT serving a local large language model (LLM) as an artificial intelligence (AI) backend to Kubernetes (K8s) in HPE GreenLake for Private Cloud Enterprise. It explores the convergence of K8s and AI for diagnosing and triaging issues in K8s clusters and providing actionable insights and recommendations from AI for K8s management.
Overview
HPE GreenLake for Private Cloud Enterprise: Containers, one of the HPE GreenLake cloud services available on the HPE GreenLake for Private Cloud Enterprise, allows customers to create a K8s cluster and deploy containerized applications to the cluster. It provides an enterprise-grade container management service using open source K8s.
K8s is celebrated for its scalability, self-healing capabilities and compatibility, which make it a preferred choice for developers and organizations. Though K8s dramatically simplifies application deployment in containers, it adds a new set of complexities for managing, securing and troubleshooting applications. Operating K8s clusters and managing the deployed applications can present challenges.
AI is a technological innovation that equips computers and machines with the ability to mimic human intelligence and problem-solving skills. These AI systems are trained on vast volumes of data, enabling them to recognize patterns and perform tasks such as solving problems in a human-like manner. The evolution of AI, especially the advent of extensive LLM models, has expanded possibilities in many sectors, including K8s. The application of AI in enhancing diagnostics and troubleshooting workflows in K8s clusters has grown considerably.
This blog post explores the convergence of K8s and AI through K8sGPT, a tool for scanning the K8s cluster, diagnosing and triaging K8s issues using AI. It describes the detailed process to integrate K8sGPT with local LLM models to empower K8s in HPE GreenLake for Private Cloud Enterprise.
Prerequisites
Before starting, make sure you have the following:
- A K8s cluster being provisioned, using HPE GreenLake Terraform provider for example, in HPE GreenLake for Private Cloud Enterprise
The kubectl CLI tool, together with the kubeconfig file for accessing the K8s cluster
Python 3.8 or higher, and pip that’s included by default in Python
K8sGPT and LocalAI
K8sGPT is an open source project designed to address common and complex issues within K8s cluster using AI. It leverages large language models (LLMs) to enhance troubleshooting, streamline processes, and improve K8s management. K8sGPT supports various AI backends (also called providers), including OpenAI, Amazon Bedrock, Azure OpenAI, Google Gemini as well as LocalAI.
LocalAI is an open source project that provides an alternative to OpenAI’s offerings for local inferencing. It does not require a GPU and can run on consumer-grade hardware without high-end computing resources. By deploying AI solutions within the local infrastructure and keeping all processes in-house, it avoids the costs associated with external AI services and ensures better data sovereignty and privacy.
The following sections describe the process to deploy K8sGPT using LocalAI as its backend to empower K8s cluster with AI capabilities in HPE GreenLake for Private Cloud Enterprise.
Install K8sGPT
There are two options to install K8sGPT, as a CLI tool or as a K8s Operator in the K8s cluster. This section takes the CLI option to install K8sGPT to the Linux workstation in my local environment that's used to manage the K8s clusters. You can refer to the K8sGPT Github for additional information to install the K8sGPT as a K8s Operator or as a CLI tool on Windows or Mac. With the CLI option, the K8sGPT setup will be independent of any specific K8s cluster and it can be used for working on any existing K8s clusters. This is helpful, especially when multiple K8s clusters are created and managed in your environment. They can all work with the same K8sGPT installation.
Follow these instructions to install K8sGPT as a CLI tool on the Linux workstation:
$ curl -LO https://github.com/k8sgpt-ai/k8sgpt/releases/download/v0.3.24/k8sgpt_386.deb $ sudo dpkg -i k8sgpt_386.deb
Type the following command to verify the K8sGPT installation:
$ k8sgpt version k8sgpt: 0.3.24 (eac9f07), built at: unknown $ k8sgpt -h Kubernetes debugging powered by AI Usage: k8sgpt [command] Available Commands: analyze This command will find problems within your Kubernetes cluster auth Authenticate with your chosen backend cache For working with the cache the results of an analysis completion Generate the autocompletion script for the specified shell filters Manage filters for analyzing Kubernetes resources generate Generate Key for your chosen backend (opens browser) help Help about any command integration Integrate another tool into K8sGPT serve Runs k8sgpt as a server version Print the version number of k8sgpt Flags: --config string Default config file (/home/guoping/.config/k8sgpt/k8sgpt.yaml) -h, --help help for k8sgpt --kubeconfig string Path to a kubeconfig. Only required if out-of-cluster. --kubecontext string Kubernetes context to use. Only required if out-of-cluster. Use "k8sgpt [command] --help" for more information about a command.
K8sGPT comes with a list of built-in analyzers, which is essentially a series of rules/checks that can be used to diagnose issues in various K8s API resources, such as Pod crashes, Service failures, etc.
K8sGPT provides a list of filters that can be used together with K8sGPT analyzer to scan issues for any specific K8s API resources:
$ k8sgpt filters list Active: > Node > Pod > Deployment > ReplicaSet > PersistentVolumeClaim > Service > Ingress > StatefulSet > ValidatingWebhookConfiguration > MutatingWebhookConfiguration > CronJob Unused: > HorizontalPodAutoScaler > PodDisruptionBudget > NetworkPolicy > Log > GatewayClass > Gateway > HTTPRoute
You can add any other unused filters, e.g., HorizontalPodAutoScaler or NetworkPolicy, by typing the command 'k8sgpt filter add [filter(s)]'.
Set up LocalAI backend
This section will focus on setting up and utilizing LocalAI with a supported LLM model in the local environment. This LocalAI setup in the workstation will be integrated with K8sGPT.
Download a LLM model
LocalAI supports a list of LLM models, such as LLama, GPT4ALL, Alpaca and koala, etc. In this blog post, the LLM model Llama-2–13b-chat-hf from Hugging Face will be downloaded and used as the local AI backend for K8sGPT.
After you create an account in Hugging Face, log in to the site and share your contact information. You will then be granted access to this model.
Type the following command to clone the LLM model. Make sure you have git-lfs installed.
$ git-lfs clone https://huggingface.co/meta-llama/Llama-2-13b-chat-hf $ tree Llama-2-13b-chat-hf/ Llama-2-13b-chat-hf/ ├── config.json ├── generation_config.json ├── LICENSE.txt ├── model-00001-of-00003.safetensors ├── model-00002-of-00003.safetensors ├── model-00003-of-00003.safetensors ├── model.safetensors.index.json ├── pytorch_model-00001-of-00003.bin ├── pytorch_model-00002-of-00003.bin ├── pytorch_model-00003-of-00003.bin ├── pytorch_model.bin.index.json ├── README.md ├── Responsible-Use-Guide.pdf ├── special_tokens_map.json ├── tokenizer_config.json ├── tokenizer.json ├── tokenizer.model └── USE_POLICY.md 0 directories, 18 files
Install Text Generation Web UI
There are many LLM serving framework and tools that support various LLM models and provide a way to interact with those models with OpenAI compatible API endpoints.
This section introduces the Text Generation Web UI (TGW) tool and shows how to set up this tool to support the locally downloaded LLM model as the AI backend. The TGW is a Gradio based tool that builds a web UI and supports many large language model formats with OpenAI compatible APIs.
Type the following commands to clone the TGW repo and install it in the workstation:
git clone https://github.com/oobabooga/text-generation-webui cd text-generation-webui pip install -r requirements.txt
Serve local LLM model
Type the following command to start serving the downloaded LLM model in your workstation. The option '--extensions openai' specifies to use the OpenAI extension to provide OpenAI format API. The options '--cpu' & '--load-in-4bit' to load model in 4-bit precision and use the model performed on a CPU to make predictions. This is more cost-effective for inference, and it’s helpful in case you don’t have GPU's installed in your environment.
$ python3 server.py --listen-host 0.0.0.0 --listen --model Llama-2-13b-chat-hf --model-dir /home/guoping/CFE/AI/models --extensions openai --cpu --load-in-4bit 20:32:39-883617 INFO Starting Text generation web UI 20:32:39-887086 WARNING You are potentially exposing the web UI to the entire internet without any access password. You can create one with the "--gradio-auth" flag like this: --gradio-auth username:password Make sure to replace username:password with your own. 20:32:39-889820 INFO Loading "Llama-2-13b-chat-hf" 20:32:39-923551 INFO TRANSFORMERS_PARAMS= {'low_cpu_mem_usage': True, 'torch_dtype': torch.float32} Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████�███| 3/3 [00:47<00:00, 15.91s/it] 20:33:27-988083 INFO LOADER: "Transformers" 20:33:27-989519 INFO TRUNCATION LENGTH: 4096 20:33:27-990434 INFO INSTRUCTION TEMPLATE: "Custom (obtained from model metadata)" 20:33:27-991414 INFO Loaded the model in 48.10 seconds. 20:33:27-992350 INFO Loading the extension "openai" 20:33:28-164441 INFO OpenAI-compatible API URL: http://0.0.0.0:5000 Running on local URL: http://0.0.0.0:7860
The OpenAI compatible API endpoint is hosted on 'http://0.0.0.0.5000'.
Apart from this API endpoint URL, the TGW starts running another local web URL, i.e., at 'http://0.0.0.0:7860', providing 3 interface modes, chat, default & notebook, for text generation with the local LLM model backend.
You can start the browser and type this local URL 'http://0.0.0.0:7860'. You then land on the Chat page. Ask a question in the Chat page by typing some text and clicking Generate button. You may notice it’s a bit slower if you serve the model using CPU inference. But everything should work and you will get the response to your question by AI.
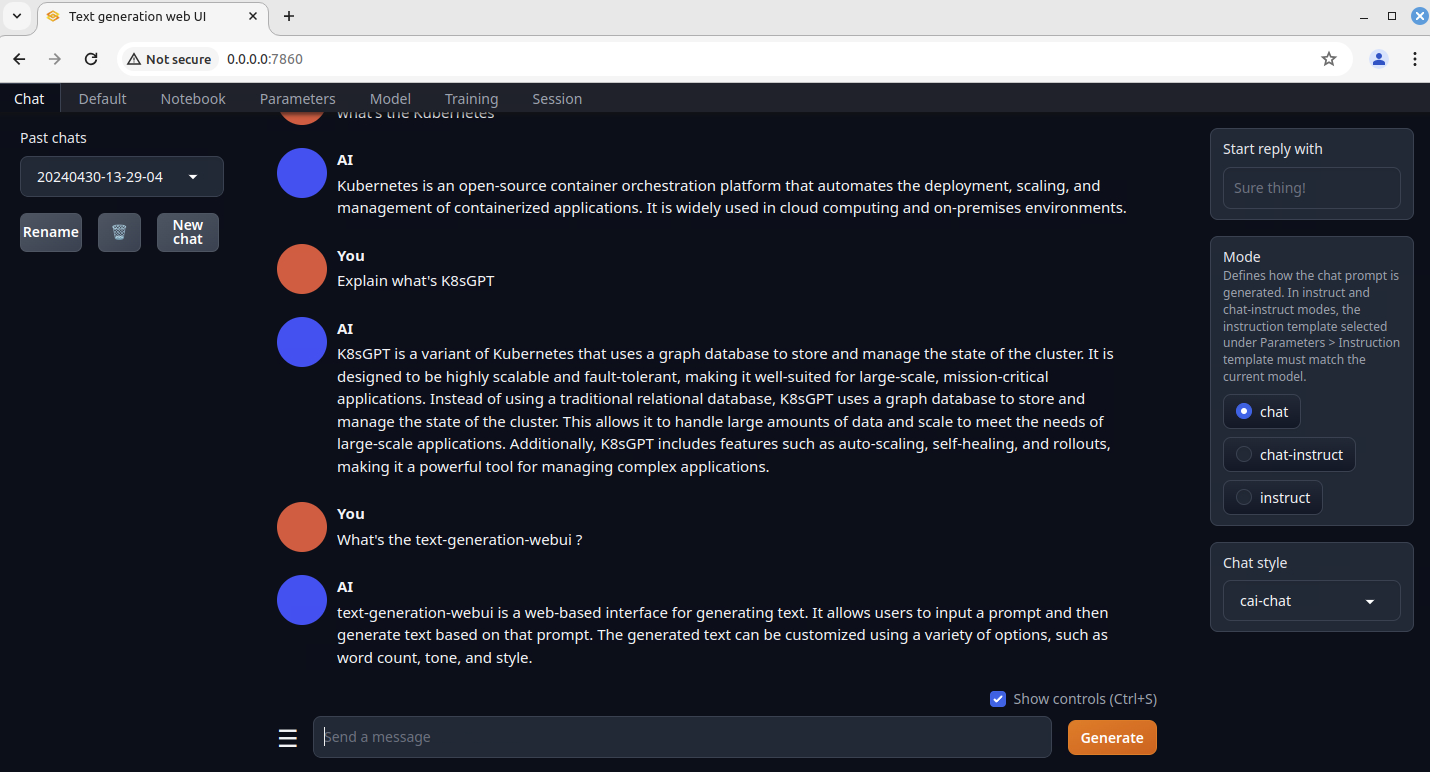
Integrate K8sGPT with LocalAI
Type the following command to configure K8sGPT to use the local API endpoint. Don’t forget to add the “/v1” to the API URL.
$ k8sgpt auth add --backend localai --model Llama-2-13b-chat-hf --baseurl http://localhost:5000/v1 localai added to the AI backend provider list $ k8sgpt auth list Default: > openai Active: > localai Unused: > openai > azureopenai > noopai > cohere > amazonbedrock > amazonsagemaker
In case the LocalAI API endpoint has been already added to K8sGPT, type the command below to remove it. Then re-run the k8sgpt auth add to add it again with the new LLM model and its API endpoint.
$ k8sgpt auth remove --backends localai
Detect K8s issues using K8sGPT
With all components being installed and configured, it's time to detect K8s issues in the K8s cluster.
Deploy a sample application
This section will deploy a sample application using kubectl CLI.
Type below commands to deploy such a sample application to the namespace 'cfe-apps':
$ kubectl create ns cfe-apps namespace/cfe-apps created $ kubectl create deployment app-with-no-image --image=cfe-image-not-exist -n cfe-apps deployment.apps/app-with-no-image created
Check the deployed application using the following command:
$ kubectl get all -n cfe-apps NAME READY STATUS RESTARTS AGE pod/app-with-no-image-7ff65f5484-9bt4z 0/1 ImagePullBackOff 0 2m NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/app-with-no-image 0/1 1 0 2m NAME DESIRED CURRENT READY AGE replicaset.apps/app-with-no-image-7ff65f5484 1 1 0 2m
The output shows some issues in the K8s Pod 'app-with-no-image-7ff65f5484-9bt4z'. The K8s Deployment keeps showing as '0/1 READY'.
Run k8sgpt analyze
To start K8s issue detection, type the following k8sgpt analyze command:
$ k8sgpt analyze --backend localai --filter=Pod --namespace cfe-apps --no-cache AI Provider: localai 0 cfe-apps/app-with-no-image-7ff65f5484-9bt4z(Deployment/app-with-no-image) - Error: Back-off pulling image "cfe-image-not-exist"
Instead of running a scan with all the default analyzers, the above command uses the filter Pod to detect K8s Pod issue in the namespace 'cfe-apps'. It detects the error of back-off pulling image "cfe-image-not-exist" in the Pod.
Execute again the K8sGPT analyze with the option '--explain' this time:
$ k8sgpt analyze --backend localai --filter=Pod --namespace cfe-apps --explain --no-cache 100% |█████████████████████████████████████████████████████████████████████████████████████████████████| (1/1, 25 it/hr) AI Provider: localai 0 cfe-apps/app-with-no-image-7ff65f5484-9bt4z(Deployment/app-with-no-image) - Error: Back-off pulling image "cfe-image-not-exist" Error: Back-off pulling image "cfe-image-not-exist" Solution: 1. Check the image name and ensure it exists in the registry. 2. Verify the image tag and ensure it matches the expected tag. 3. Try pulling the image again using the correct name and tag. 4. If the image still does not exist, check the spelling and ensure the name is correct. 5. If all else fails, try using the "docker pull" command to download the image locally and then push it to the registry.
The option '--explain' in the above command enables the AI backend. The analyze establishes a connection to the AI backend and provides it with the error message it detected in K8s. When the option '--explain' is used, K8sGPT not only executes the requested action to detect the K8s issue but also provides the step-by-step solutions. The solutions provided by K8sGPT can be used as actionable insights to fix the K8s issues.
Apart from the default English, K8sGPT supports getting the response in other languages. Here is an example of getting a response in K8sGPT in French:
$ k8sgpt analyze --backend localai --filter=Pod --namespace cfe-apps --language french --explain --no-cache 100% |█████████████████████████████████████████████████████████████████████████████████████████████████| (1/1, 16 it/hr) AI Provider: localai 0 cfe-apps/app-with-no-image-7ff65f5484-9bt4z(Deployment/app-with-no-image) - Error: Back-off pulling image "cfe-image-not-exist" Sure! Here's the simplified error message and solution in French, within the 280 character limit: Error: Impossible de tirer l'image "cfe-image-not-exist". Solution: 1. Vérifiez si l'image est disponible dans le registre de conteneurs. 2. Si l'image n'existe pas, créez-la manuellement en utilisant le commandes `docker pull` ou `docker build`. 3. Essayez à nouveau de tirer l'image en utilisant la commande `kubectl apply`.
Conclusion
This blog post explores the integration of K8s with AI to address the complexities for managing, securing and troubleshooting K8s cluster and its applications. By integrating K8sGPT with LocalAI to K8s in HPE GreenLake for Private Cloud Enterprise, it eliminates the need for external AI services, leading to cost reductions and enhanced data sovereignty and privacy by preventing data transmission to external AI providers.
K8sGPT proves to be a valuable asset in diagnosing issues in K8s cluster and enhancing operational efficiency. This tool can be further integrated with other organizational tools like Slack and Microsoft Teams to dispatch notifications and alerts, accompanied by suggested solutions as remediation steps. This futher amplifies the practical value of K8sGPT within the organization.
Please keep coming back to the HPE Developer Community blog to learn more about HPE GreenLake for Private Cloud Enterprise and get more ideas on how you can use it in your everyday operations.
Tags
Related
A guide to enabling a managed Istio service mesh in a Kubernetes cluster on HPE GreenLake for Private Cloud Enterprise
Feb 16, 2023
Bare metal provisioning on HPE GreenLake using Terraform
Mar 20, 2023Configuring Azure Active Directory with long-lived tokens for user provisioning
Jul 16, 2024Create a General-Purpose Kubeconfig File in HPE GreenLake for Private Cloud Enterprise
May 20, 2022Curate and Expose Service Catalog Items using HPE GreenLake for Private Cloud Enterprise
Feb 16, 2022Deploy stateful MongoDB applications on Kubernetes clusters in HPE GreenLake for Private Cloud Enterprise
Aug 16, 2022A guide to deploying MongoDB applications using HPE GreenLake for Private Cloud Enterprise
Dec 1, 2022