
What's new?
Recently, a new set of REST APIs for HPE GreenLake for Backup and Recovery Service was introduced in the HPE GreenLake Developer website. This is the third blog post from the series of blog postings (Data-Services, Virtualization, Backup and Recovery) that introduce some useful tips and best practices about using this new set of APIs given a specific use case.
This set of APIs provides the capability for manipulating resources made available by HPE GreenLake for Backup and Recovery services. Consequently, any customer can use these APIs to protect their data in a hybrid cloud in the same manner as using the user interface for HPE GreenLake for Backup and Recovery in the HPE GreenLake console. This set of APIs provides user capabilities to perform any of Create, Read, Update and Delete (CRUD) operations against HPE GreenLake Backup and Recovery resources such as: data-orchestrator, protection store gateway, StoreOnce, protection-stores, protection-policies, snapshots, backups, on-premises assets (VM, DataStore, MSSQL, Storage Volumes).
There will be more resources added into this set of APIs in the future releases that will cover cloud service providers, and cloud assets. For more information on how to use this HPE GreenLake for Backup and Recovery service, please visit the website and the getting started guide.
The specification of this API is publicized as an OpenAPI specification in JSON format, and the specification is available for download from this section of the documentation (shown below). The specification follows the OpenAPI Standard v3.1, and it contains all required information so that this JSON file can be consumed by any OpenAPI tools to provide client library, server mock, or documentation as described in this OpenAPI Initiative.
NOTE: There are two different sets of OpenAPI specs that are downloadable from the documentation page of the Backup and Recovery in the March 2024 release. The two sets represent the two versions of Backup and Recovery APIs that were made available for separate resources, namely hypervisor-managers and the rest of other resources as shown in this picture below. To get into the page for downloading each of the OpenAPI specification file, scroll through the left windows and select the appropriate API version page.

The Backup and Recovery API specification files contain information that describes the set of REST APIs for HPE GreenLake for Backup and Recovery, such as the endpoints, authentication, syntax of parameters, expected response, and many other objects.

The above figure shows the example of the downloaded backup-and-recovery v1beta1.json file from the Backup and Recovery API documentation guide.
API versioning
This set of APIs is released with two different specifications which are identified as revision V1 Alpha 1 and V1 Beta 1 at the time of its release in March 2024. The short-term plan is to publish version 1 of the HPE GreenLake APIs for Backup and Recovery Service to replace the V1 Alpha 1 and V1 Beta 1 versions. Once the API is at version 1, the intent is to keep changes to the minimum required and publicly announce changes as they are made. As each individual API is updated, there will also be more capabilities added to any of the resources identified under this set of APIs. For information regarding updates and deprecation, please refer the HPE GreenLake Developer Portal Versioning guide. You can expect that the API categorized as V1 Alpha 1 will be updated within a short time; hence, I recommend you monitor for any announcement of the next revision of APIs for Backup and Recovery in this documentation guide.
NOTE: At the time of its release in March 2024, all of resources for HPE GreenLake API for Backup and Recovery are limited to data protection of on-premises assets. The manipulation of the cloud assets will be made available in the next release.
What are Backup and Recovery API resources?
There are a lot of resources that are part of this set of APIs . Therefore, I like to break them down into two parts so that I can present the familiar view of the components that correspond to the resources.
The below diagram displays components in the first part of the HPE GreenLake API for Backup and Recovery. These components consist of resources considered to be part of the infrastructure for HPE GreenLake for Backup and Recovery on-premises and in the cloud. These components must be deployed prior to operation of the HPE GreenLake for Backup and Recovery. The on-premises components consist of Data Orchestrator VM, Protection Store Gateway VM or HPE StoreOnce (purpose-built backup appliance). Additionally, the cloud components consist of the data services instance deployed at HPE GreenLake workspace and the cloud protection store to contain the cloud recovery points (backups). The information on how to get started with HPE GreenLake for Backup and Recovery is available in the support website.
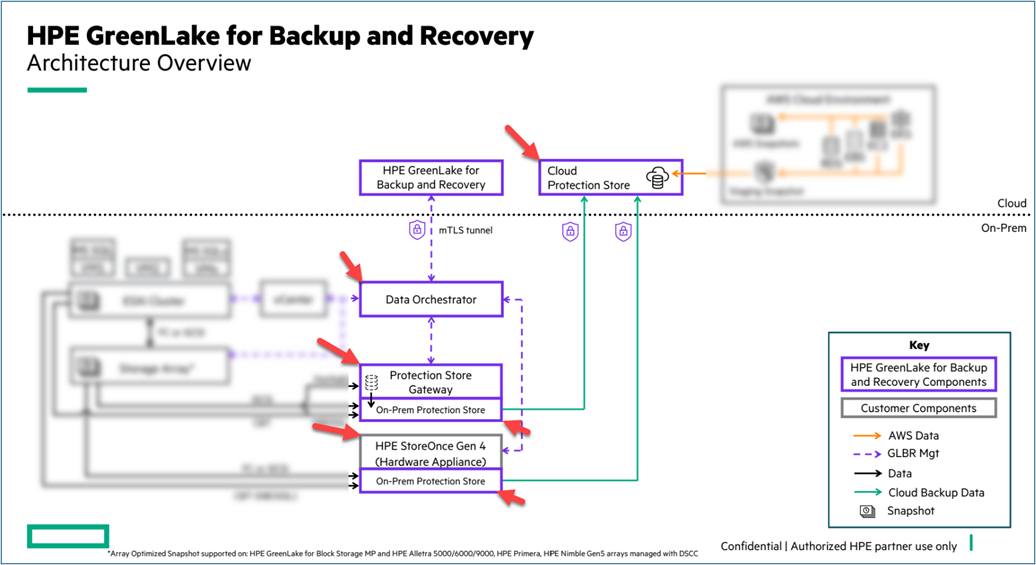
The above figure shows the resources that are part of the infrastructure used to accommodate the data protection for HPE GreenLake for Backup and Recovery.
The second part of the HPE GreenLake API for Backup and Recovery resources is the resources from which HPE GreenLake for Backup and Recovery provides protection from data loss. In below diagram, you will see those assets which contains the components that need to be protected and the components which the assets are allocated at. Those components, such as virtual machine, datastore, or SQL database application, storage volumes, or physical hosts, are the assets that need to be protected. Nevertheless, other assets in this category include the components for the hypervisor, compute servers, storage array, networking, and the VMware vCenter that manage the hypervisor components. This HPE GreenLake API must maintain the inventory of all the on-premises assets that are protected by querying the VMware vCenter.
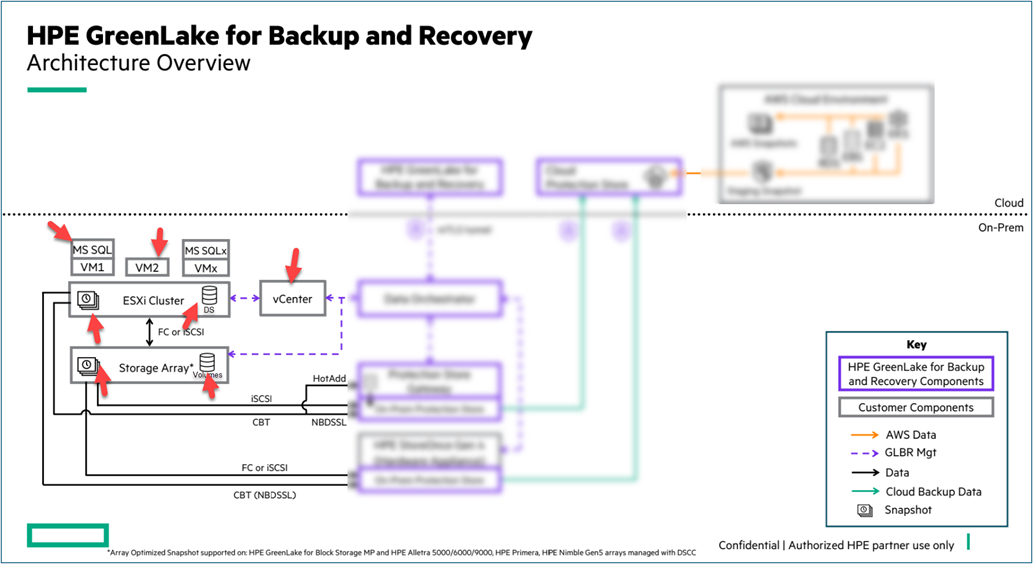
The above figure displays resources that are parts of the hypervisor and on-premises components that can be protected.
NOTE: In the current HPE GreenLake Developer website, there is a single resource categorized as V1 Alpha 1 that will be used to register, unregister, and update the hypervisor-manager to an instance of HPE GreenLake Backup and Recovery. The current supported on-premises hypervisor-manager is VMware vCenter version 7.0 or later. The HPE GreenLake API to discover the already onboarded hypervisor-manager is available from the virtualization API set.
What about the components in HPE GreenLake Backup and Recovery that are not mentioned above?
There are other resources that exist in the HPE GreenLake for Backup and Recovery that are not mentioned above; however, they are available in the user-interface for HPE GreenLake for Backup and Recovery. A couple of those resources are protection policy and protection group. The protection group is used to consolidate a multiple number of assets with a particular protection policy. On the other hand, the protection-policy is a resource to consolidate the schedule of protection-jobs and the flow of the recovery points at different tiers of protection-store. Together, both protection policy and protection group deliver the management of the Recovery Point Objective for data protection using HPE GreenLake for Backup and Recovery.
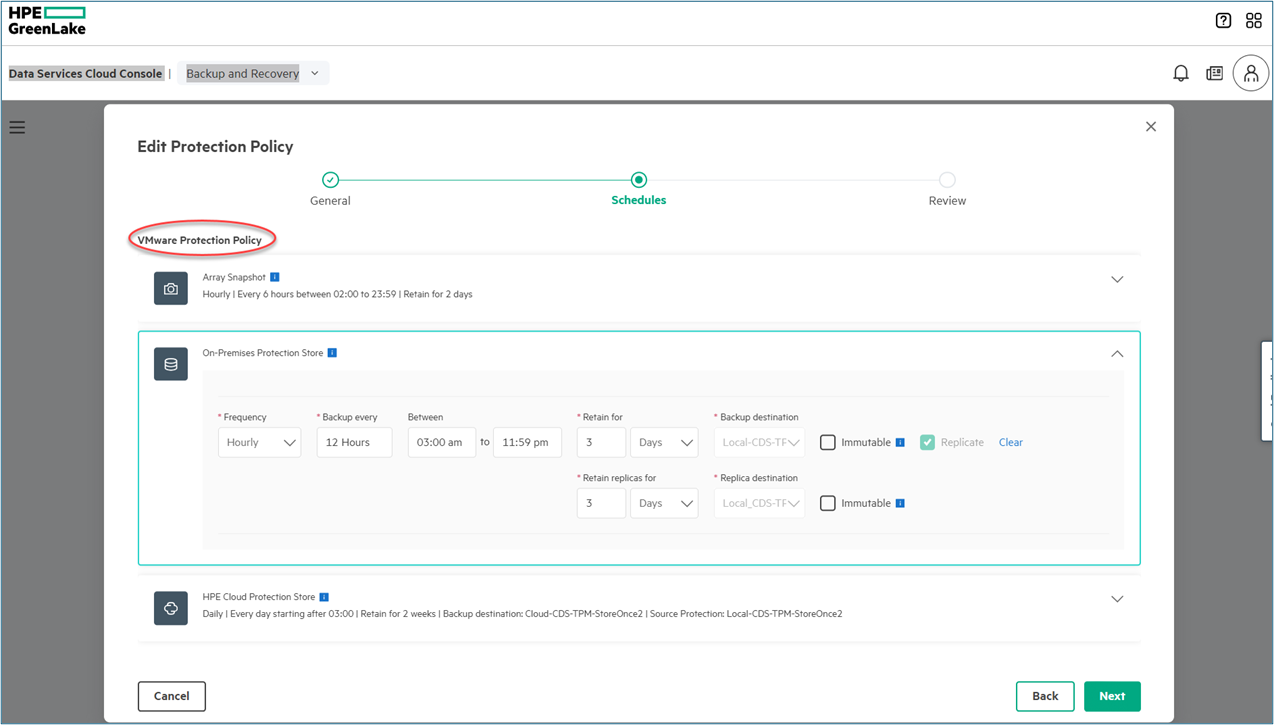
The above figure displays resources for schedule and the flow of the recovery-points part of the protection policy.
Additionally, there is also a resource known as protection job that is obscurely shown in the user-interface; however, it is required to perform the operation of data protection. You will need to manipulate protection jobs to create a protection or to recover an existing recovery point. Additionally, the protection-job is the resource that can be manipulated to suspend or to resume a protection schedule.
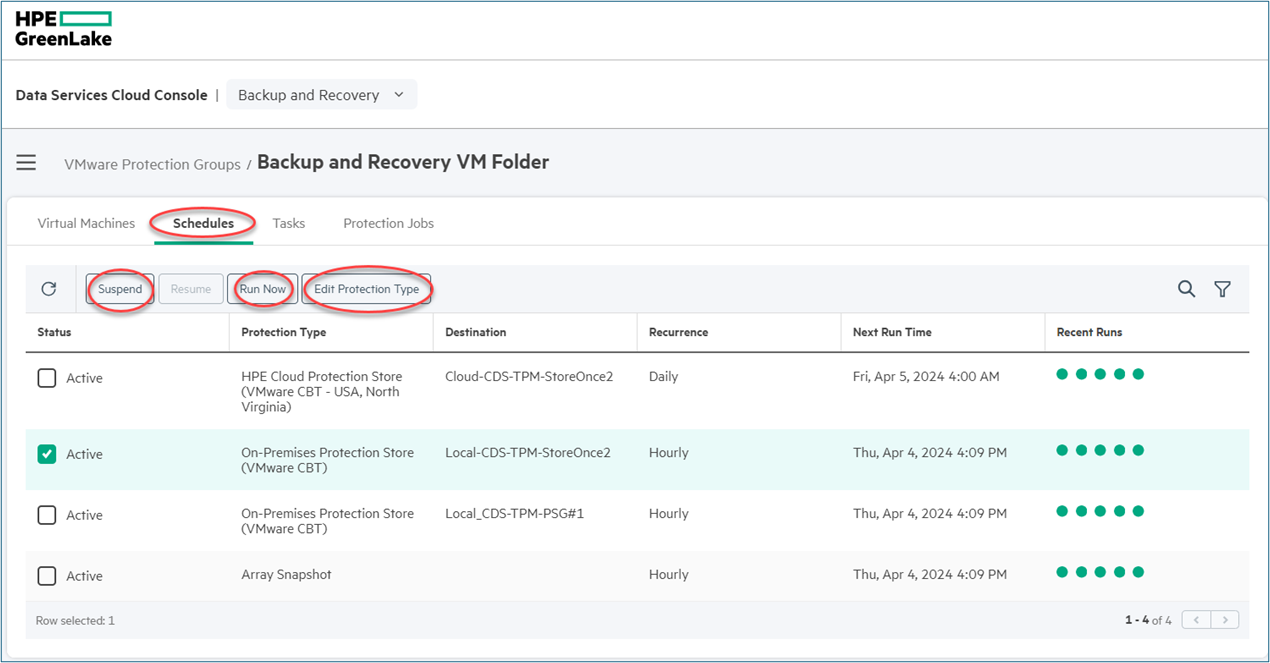
The above figure displays the representation of protection jobs for the protected assets. The protection jobs are available after a protection policy applied to an asset or a protection groups for multiple assets.
Beyond protection-jobs, there are recovery points (also known as copies). These are resources that are used to represent that recovery points inside the protection store, and they are used to perform the recovery of assets.
Note that even though there are three different categories of recovery-points that are available in the protection policy, there are only two different resources.
The first resource is called snapshots to represent copies that exist inside the storage array. The second resource is called backups to represent copies that exist inside the on-premises protection store such as Protection Store Gateway, and copies that exist inside the cloud protection store.
The cloud protection store is a repository that sits in the cloud public providers that are managed by HPE, and these can exist either in AWS or Microsoft Azure. All of these recovery points exist in relation to the assets, where the recovery can be initiated using the HPE GreenLake API.
Using the Backup and Recovery APIs
This set of Backup and Recovery APIs use the same authorization and permission as the rest of the family of HPE GreenLake API for data services. To ensure that all programmatic interaction with the HPE GreenLake platform services and resources is secure and authenticated, these APIs require an access token. The token is generated using the client ID and client Secret you acquired during the creation of the client API credentials.
Documentation concerning getting started with the HPE GreenLake API is provided on the HPE Developer Community website and on the HPE GreenLake Developer portal website. There is also blog post that describes how to use publicly available tool to manipulate this API without a programming language, such as Postman. An additional blog post that describes using Postman for this API is also available in this link.
Lastly, anyone can follow the examples provided by each API reference in the documentation page, such as the GET /backup-recovery/v1beta1/protection-jobs, which is shown in the figure below. The documentation provides detail on the API syntax for a particular method, arguments used for the API, expected successful and failed responses, and several examples of creating the automation script using cURL, JavaScript, Python, and Go. The documentation page also provides the ability to execute the API directly on the documentation page as explained in the previous blog post (Getting started with HP GreenLake Data Services API).
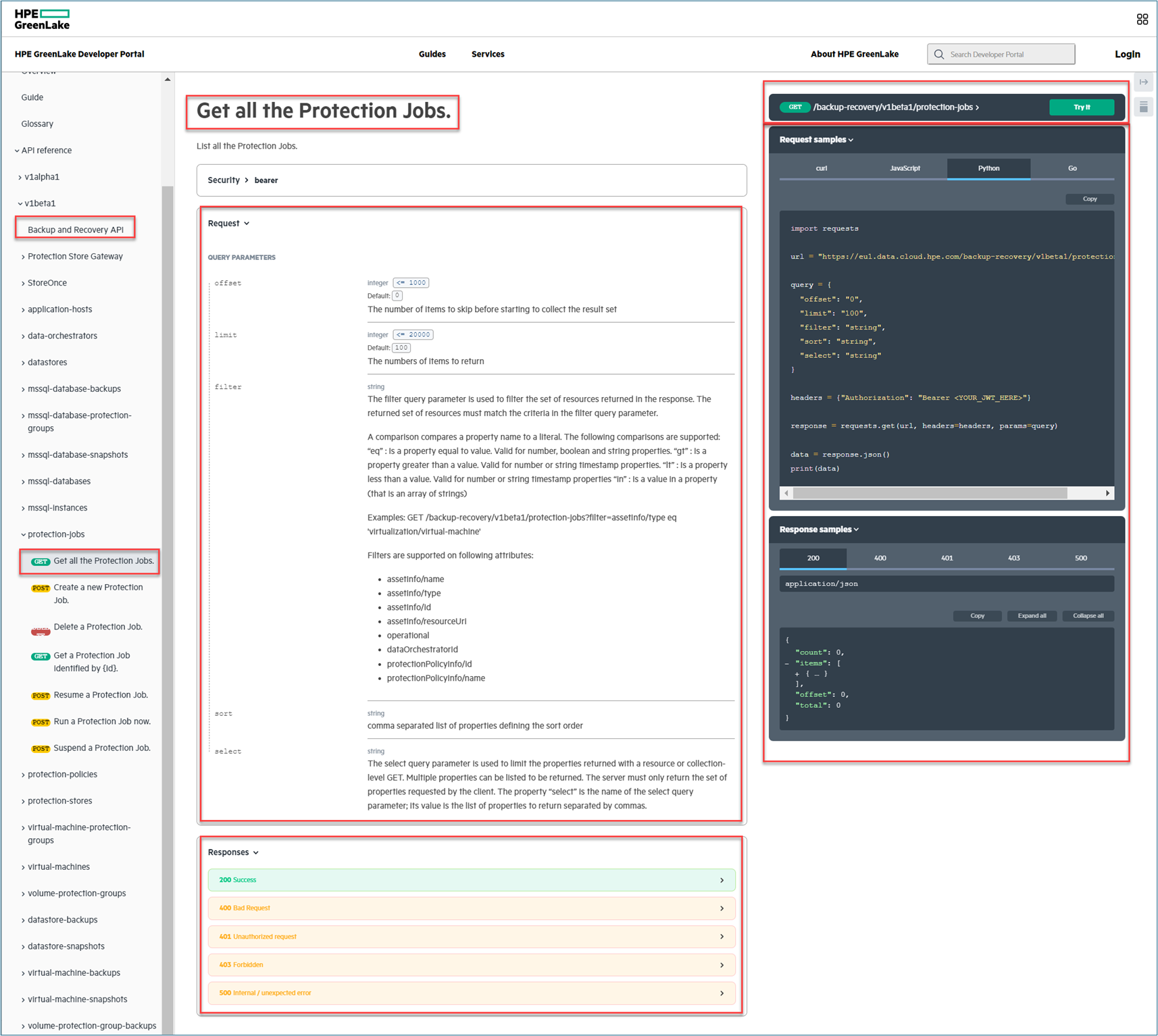
The above figure shows the three-panel of the interactive API reference documentation for one of HPE GreenLake APIs for Backup and Recovery.
Some tips and examples
The interactive API reference documentation guide provides information about the parameters and request payload (body) key-pair values required for every available HPE GreenLake API for Backup and Recovery. Additionally, I am presenting some use cases with detailed information on providing the correct parameters or building the correct request payload (body) key-pairs JSON structure required to achieve the use case.
NOTE: The below examples assume that HPE GreenLake Backup and Recovery had been deployed, it was connected to an HPE array onboarded to HPE GreenLake, a VMware vCenter had been discovered, and some virtual machines had been deployed and discovered by HPE GreenLake Backup and Recovery. For more information on getting started with HPE GreenLake Backup and Recovery, please visit the Getting Started guide on HPE support website.
Creating a cloud protection store
A protection store is the critical resource that is required to store the recovery points on-premises and in the cloud. The cloud protection stores are created on top of either the Protection Store Gateway or HPE StoreOnce, because either one is required for connections to cloud protection-stores. To perform this use case in the below example, we will need to discover the StoreOnce and the storage location of the cloud protection store.
NOTE: You will see in this blog post that I used a combination of both HPE GreenLake APIs from data services and virtualization to accomplish the below examples.
The example below displays the creation of the cloud protection store in the HPE GreenLake protection store at Microsoft Azure cloud storage.
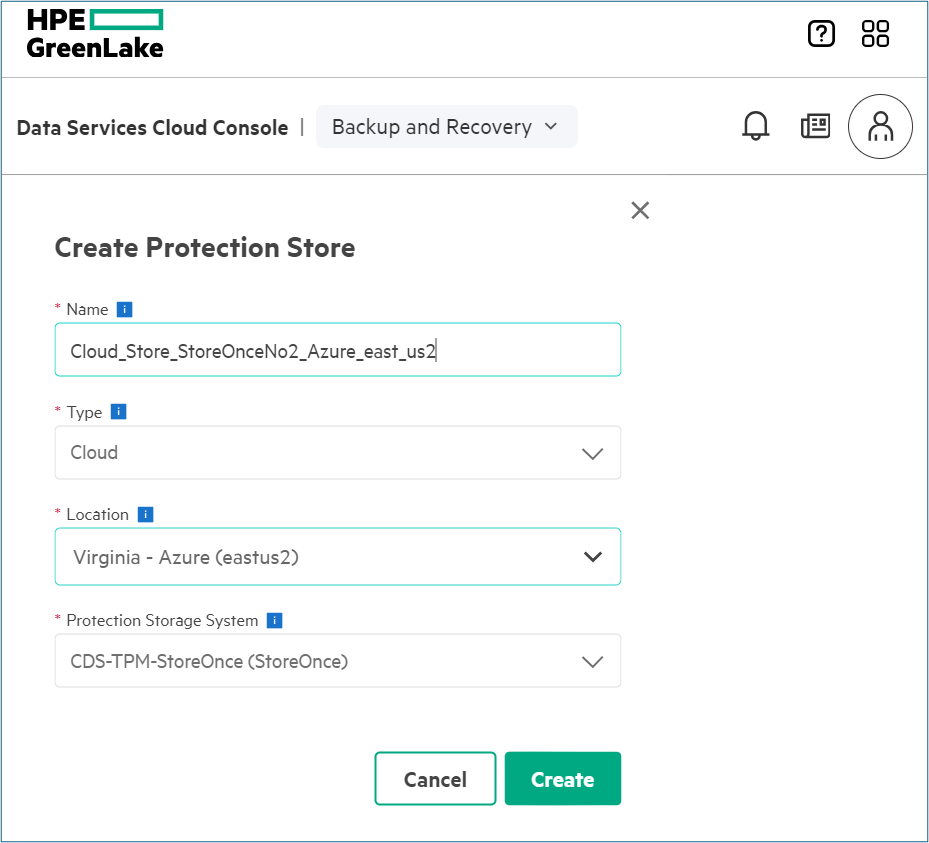
The figure above shows the user interface used to create a cloud store protection at Microsoft Azure in eastus2 storage location using the user interface.
Here is the list of the steps required to perform this use case using HPE GreenLake API:
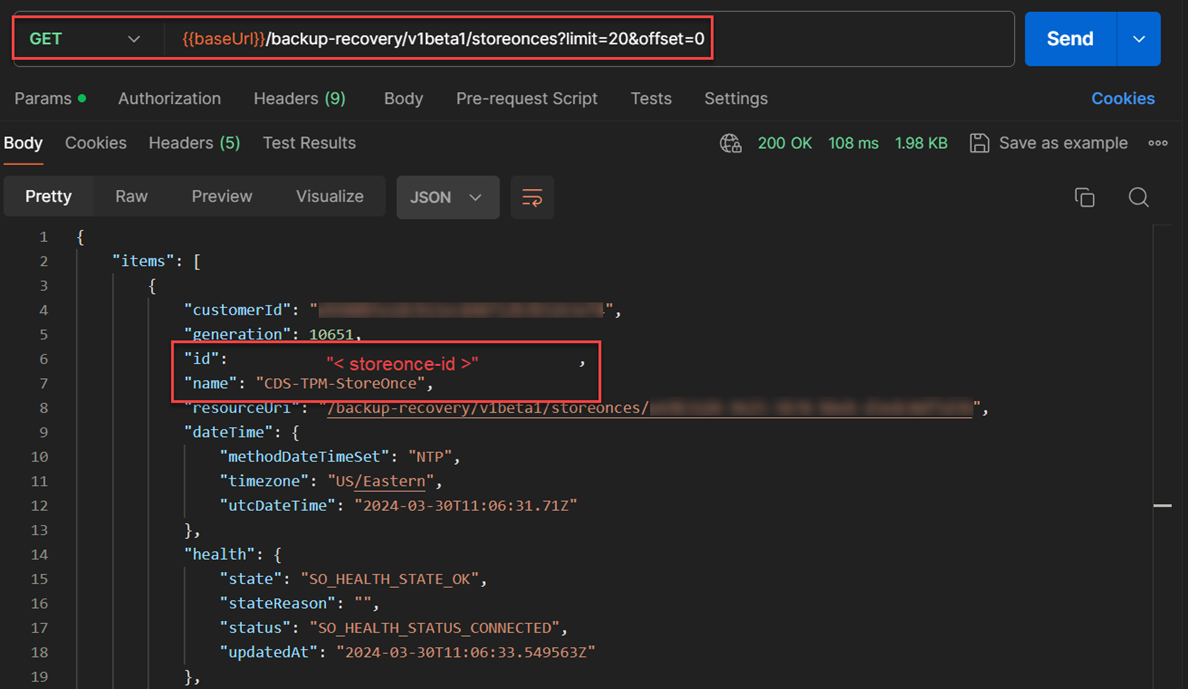
- I used the API to discover the StoreOnce instance that can connect to the cloud protection store and copied the id which will be used as the value for storageSystemId as shown in below JSON request body. The API used for this is:
GET /backup-recovery/v1beta1/storonces?limit=20&offset=0.
- Next, I discovered the cloud storage at the correct location from the list of the available storage location and copy the
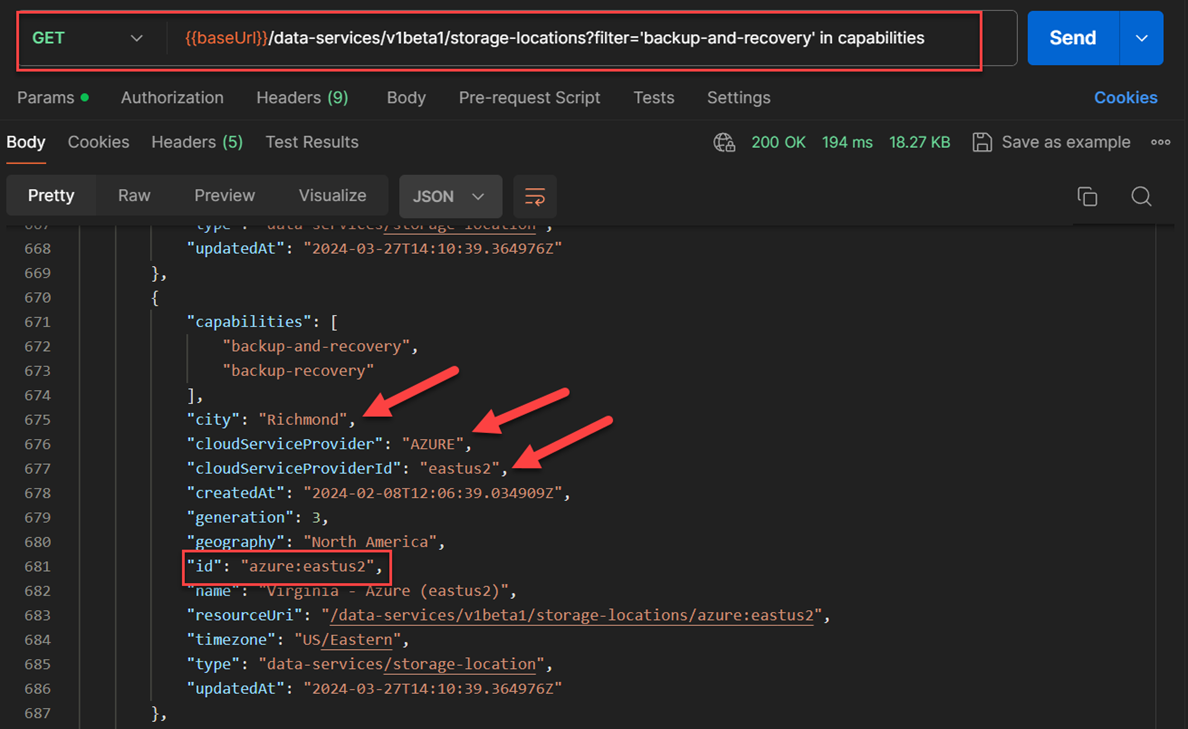
storageLocationIdas shown in below JSON response body. The discovery was done by using the HPE GreenLake API for Data Services API set. Note from the below figure that I used filter“backup-and-recovery”in capabilities to capture selected storage locations with the correct capability. The below figure shows information about the location (region) where the data will be stored; conversely, it’s located at“Richmond”, cloud service provide was“AZURE”, and cloud services provider identification is“eastus2”. I the copied value"azure:eastus2"from the keyidof this API's response body as thestorageLocationIDvalue. The API used for this:GET /data-services/v1beta1/storage-locations?filter=”backup-and-recovery” in capabilities.
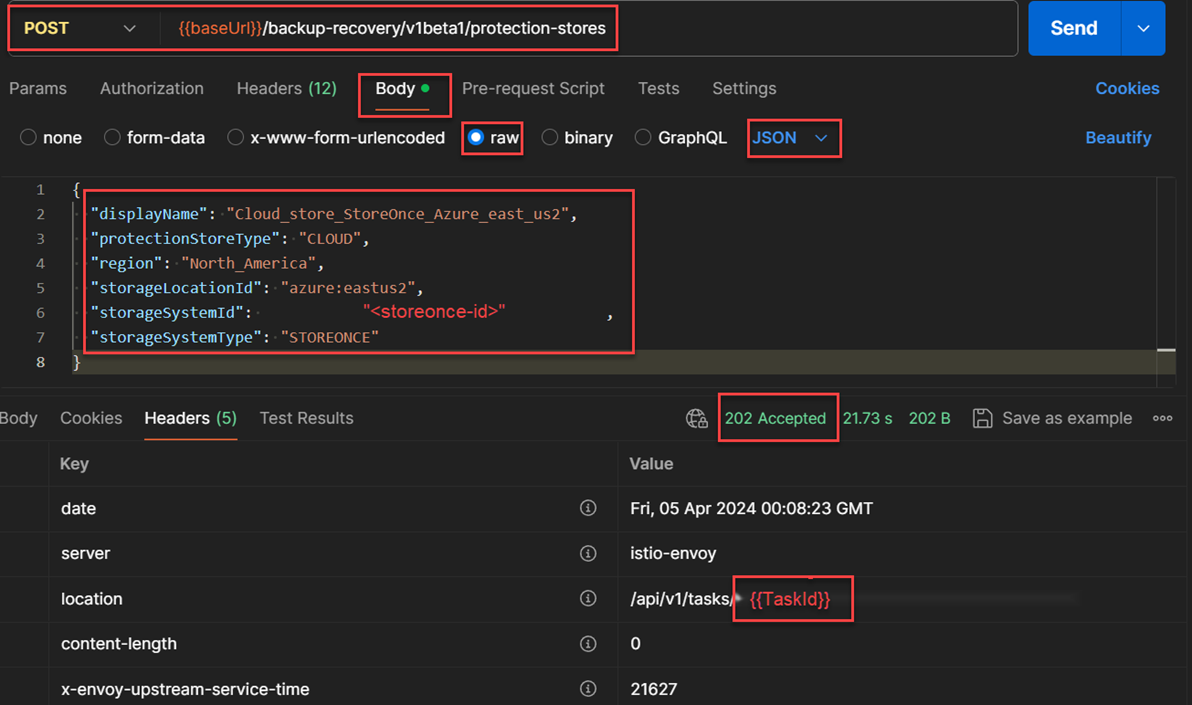
- Moving forward, I composed the cloud protection store at the storage location using values from the previous both API responses. For this API execution, I created a request JSON body structure for
POST /backup-recovery/v1beta1/protection-storesthat contains some of the key-pair values from the previous API response. The below figure shows that the creation of protection stores using the JSON body structure to compose the cloud protection store that was connected to the HPE StoreOnce.
The below REST API will be executed asynchronously, and I recognized from the Response status that this API was properly executed as shown by the
Status 0x202 Accepted. From the Header's location field part of the response body, I copied the task Id and stored that id into variable{{TaskId}}so that I could track the completion of this REST API.
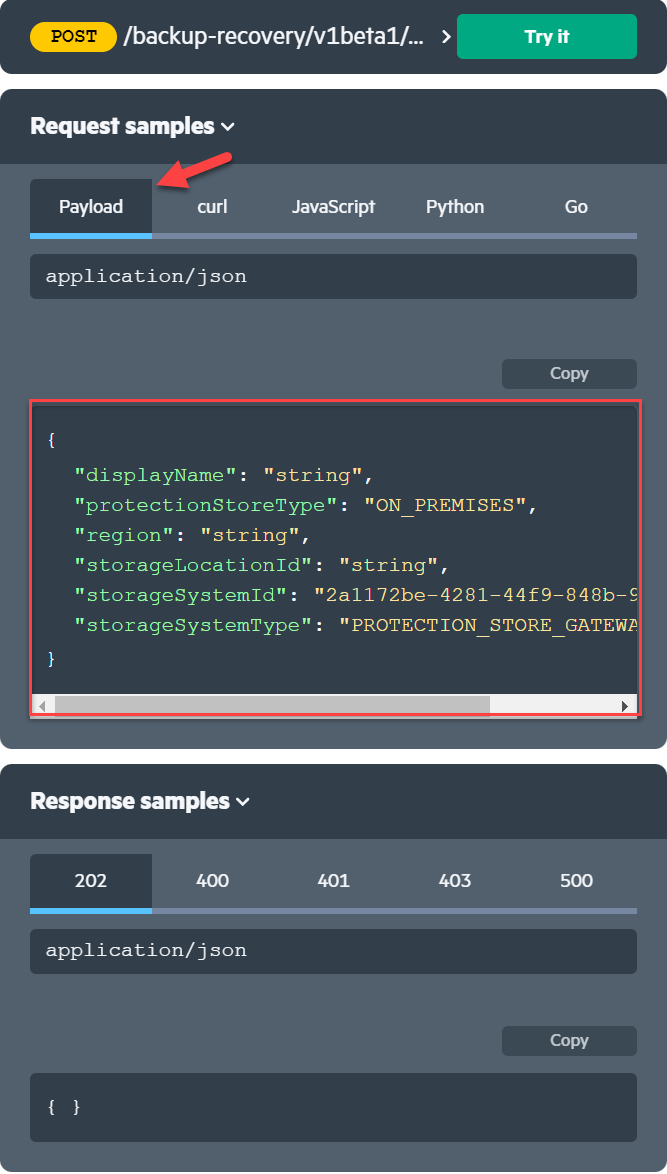
Note: The figure below shows all the fields about this JSON body structures provided on the interactive documentation of
POST /backup-recovery/v1beta1/protection-storesunder Payload tab.
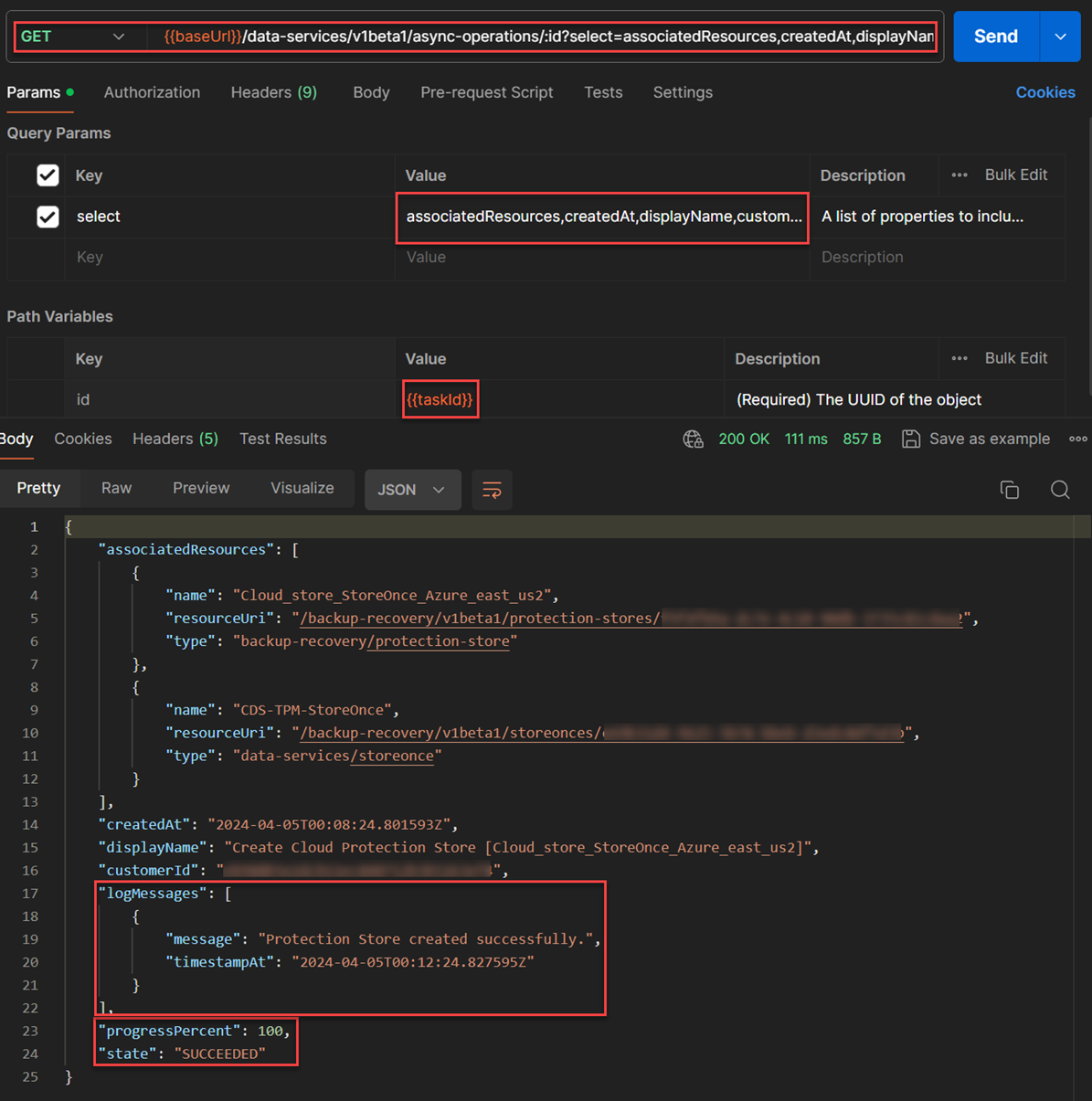
- After roughly five minutes, the cloud protection store was completely created based on response of the following
GET /data-services/async-operations/{Id}API where{{TaskId}}came from previously executed API response.
Note: I used a set of selection parameters in the figure below to provide a summary of this task information:
GET /data-services/v1beta1/async-operations/{{taskId}}/select=associatedResources,createdAt,displayName,customerId,logMessages,progressPercent,stateI copied the task��’s Id from the response header’s location value of the prior API execution into a Postman’s variable called
{{taskId}}, and incorporated the variable to theasync-operationsAPI execution as shown below.
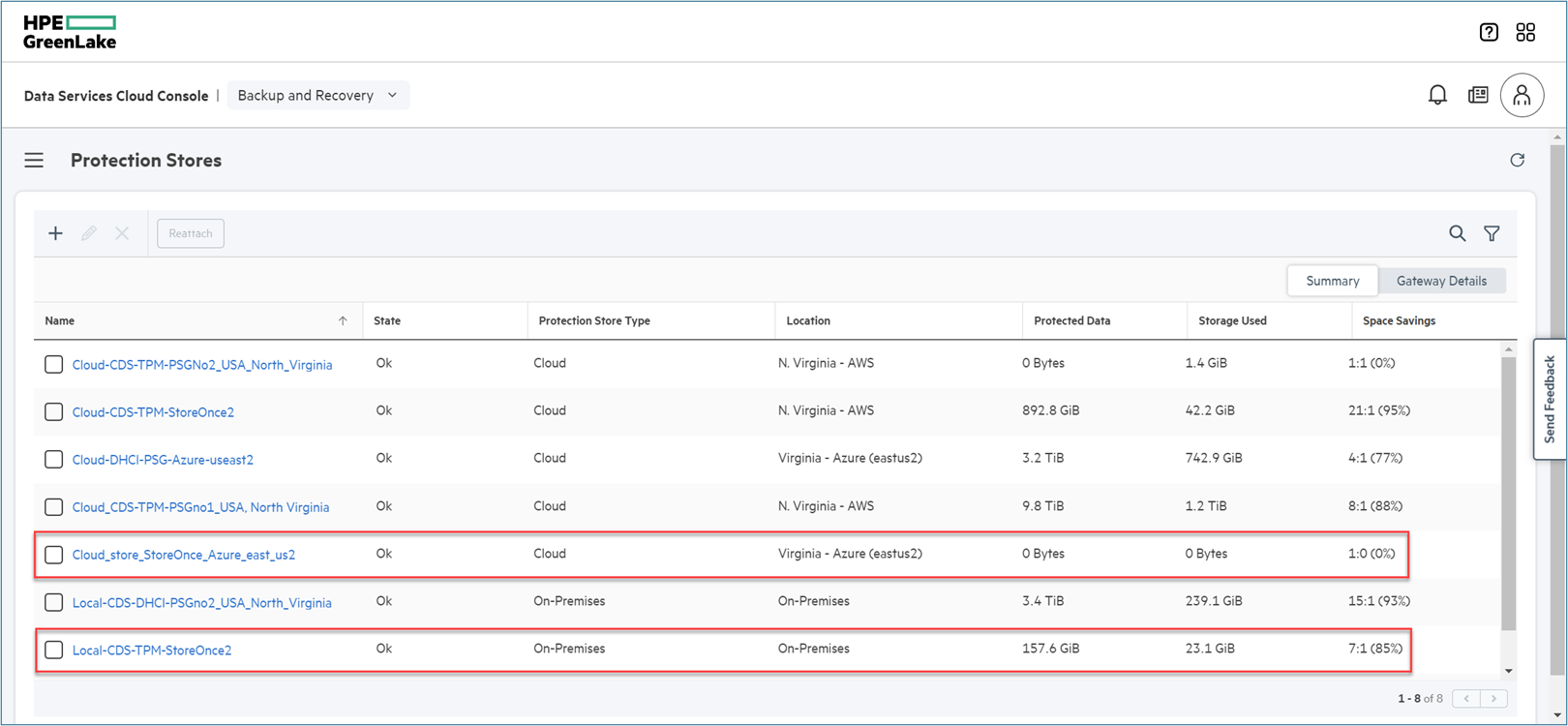
- For reference, I went into the Protection Stores menu as shown in the figure below to show the available HPE GreenLake Backup and Recovery protection-stores, and confirmed that the desired protection store was available.
Creating a Protection-Policy
A common use-case that every user of HPE GreenLake Backup and Recovery will deploy is the creation of a protection-policy. This resource is important because it sets up the schedule for creation of recovery point. Additionally, it sets up the flow of a recovery point from a primary storage to a storage snapshot, to on-premises protection-store and eventually to the cloud protection-store.
A protection policy contains several JSON objects that are displayed in the figure below.
- A schedule that contains the frequency for creation of the copy and time to retain the copies.
- Protection store where the copies are stored: snapshot (in the primary array), on-premises store, and cloud store.
- Length of time when the copy is being locked to satisfy immutability.
- The pre-script information that contains the link to the scripts to be executed prior to the creation of the copy.
- The post-script information that contains the link to the scripts to be executed after the creation of the copy.
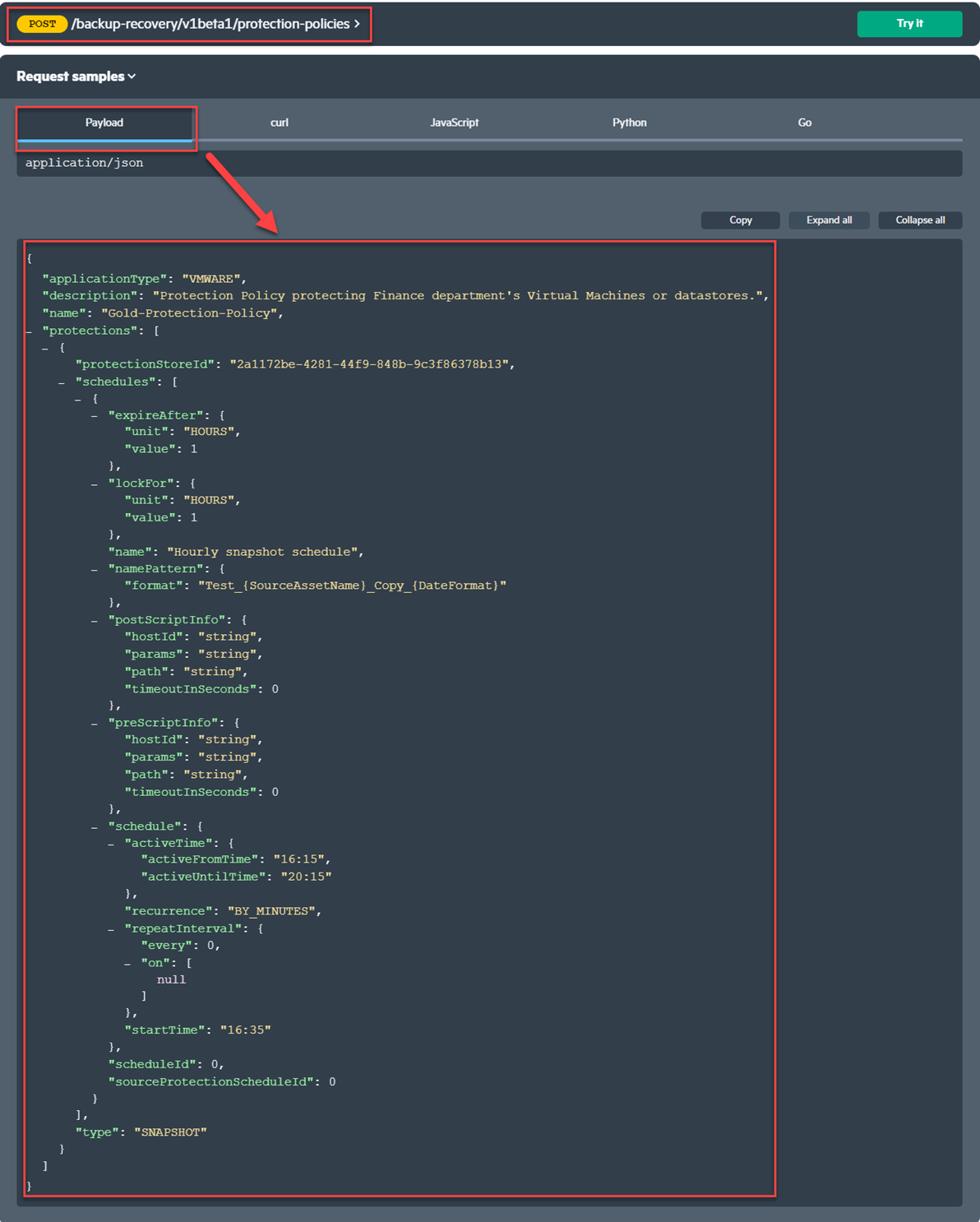
The above figure shows the guide to create a protection-policy request body JSON structure.
To simplify this example, I created a three-tier protection-policy for VMware as depicted by this snippet from the protection policy’s menu.
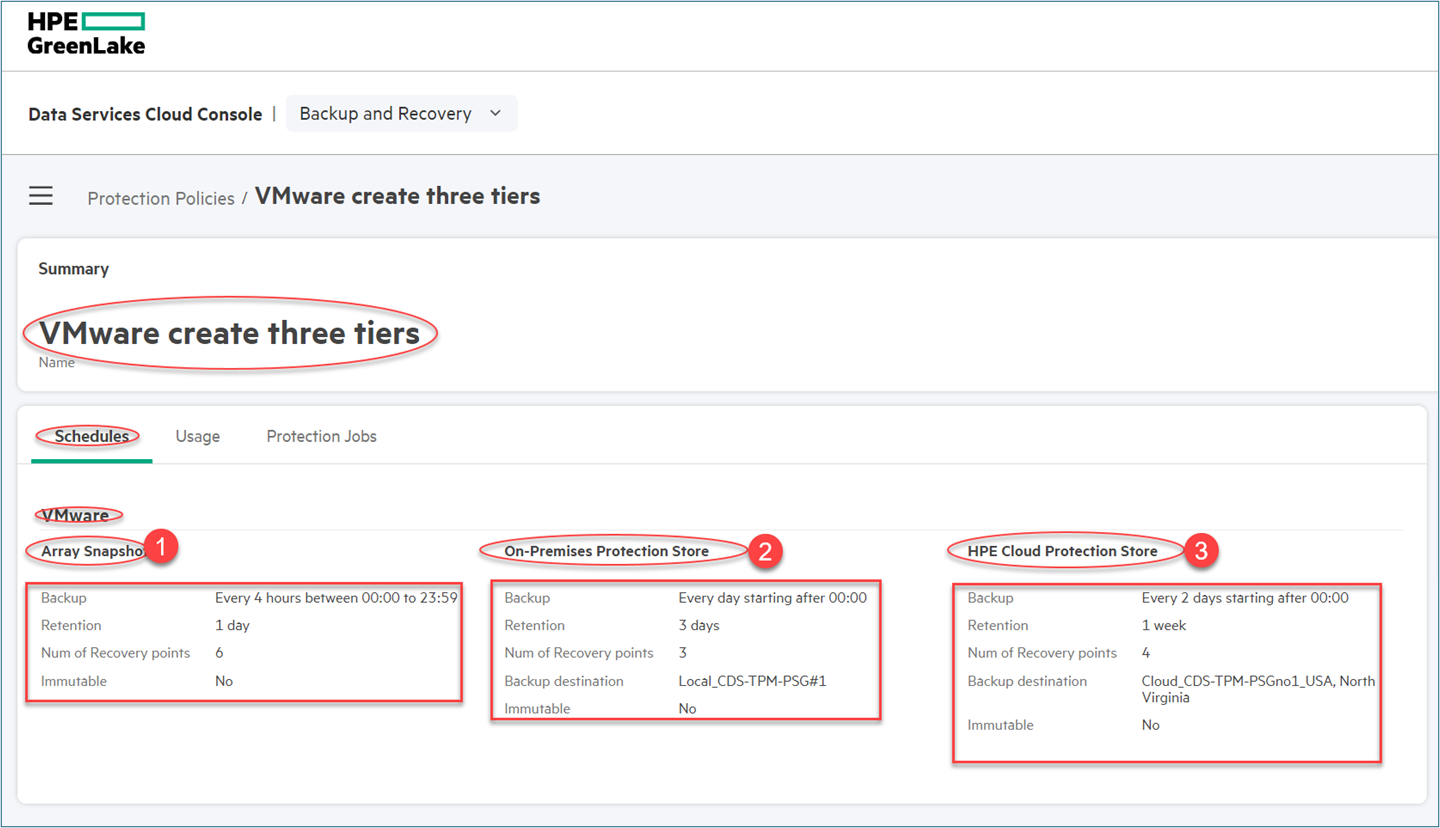
This is the list of the steps used to create this protection policy:
- From the figure below, inside the protection store gateways menu, I discovered the serial number of the protection-store gateway and used it as the filtering parameter to obtain the protection store gateway instance.
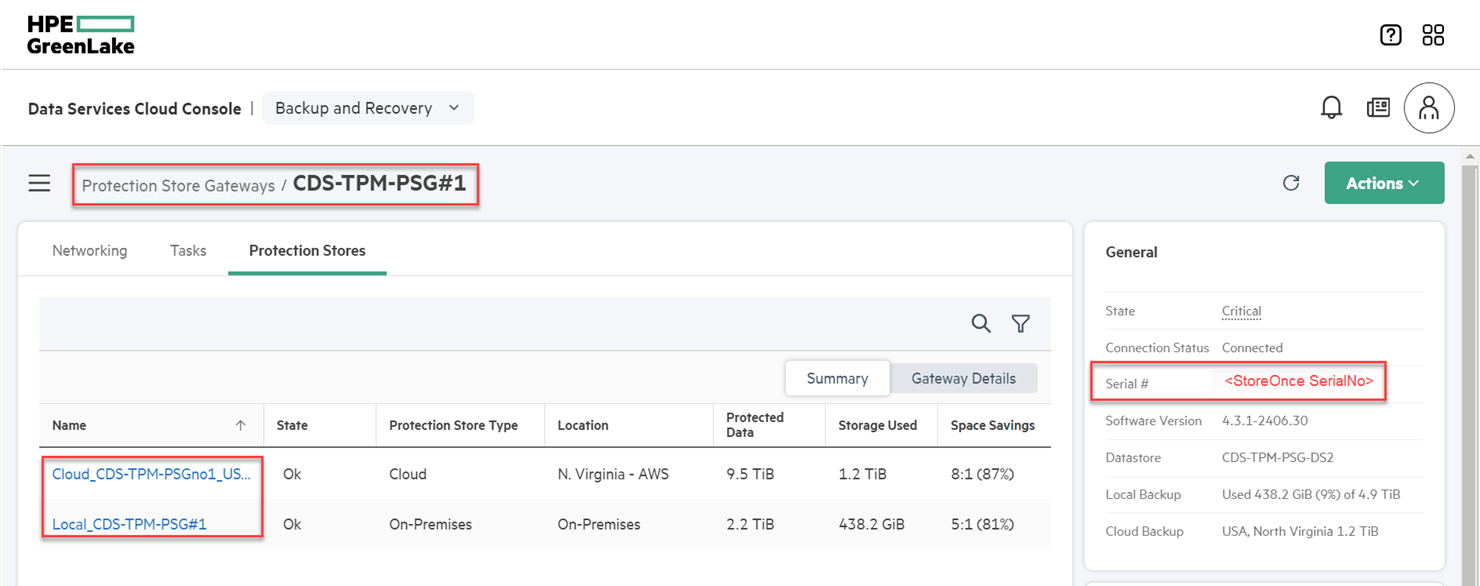
- Afterward, I used
GET /backup-recovery/v1beta1/protection-store-gatewaysAPI and thefilter=serialNumber eq <StoreOnce SerialNo>to figure out the"<protection-store-gateway-id>"that was associated with the protection-stores that would be incorporated into the protection-policy.
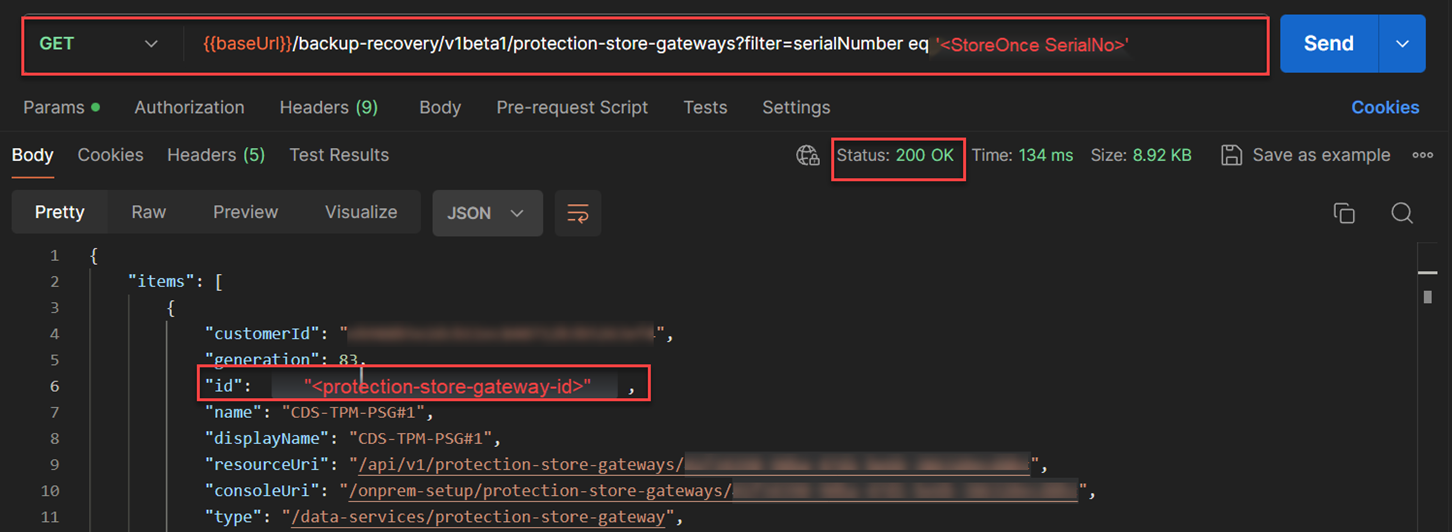
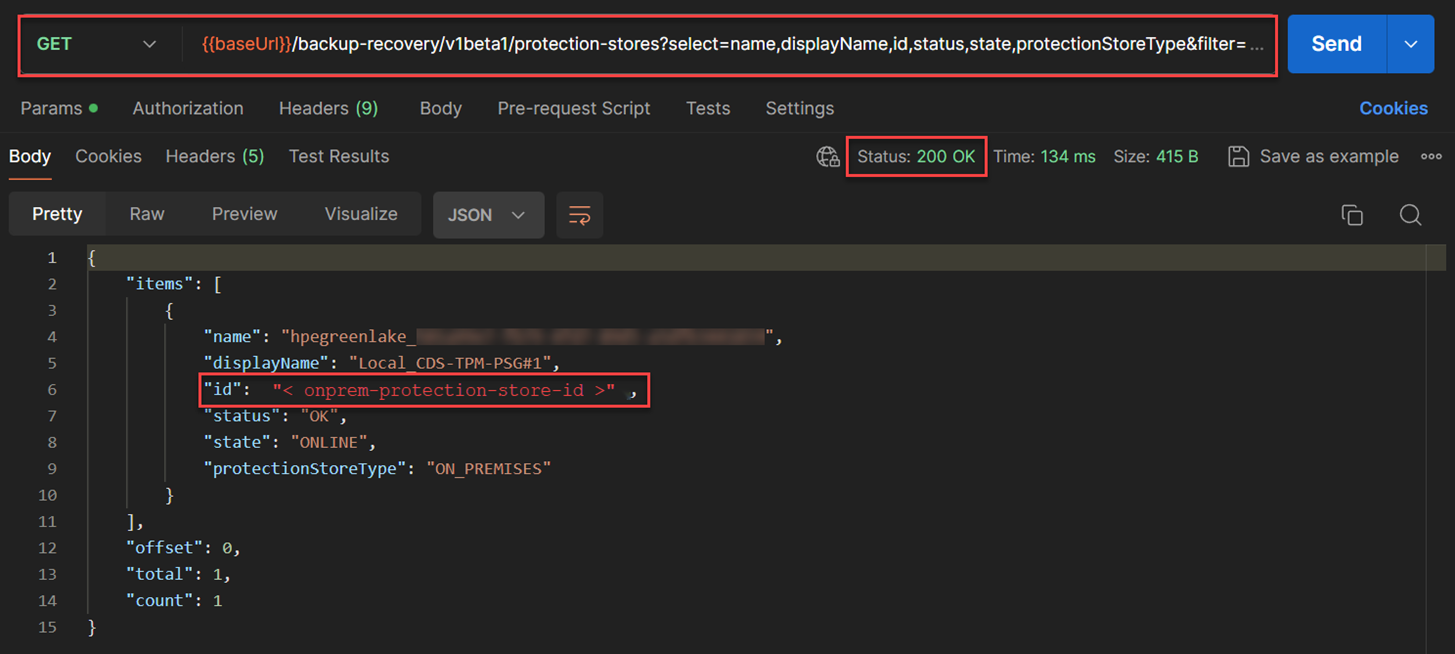
From the figure below, I used
GET /backup-recovery/v1beta1/protection-storesAPI to obtain the protection-store ids for both the on-premises protection store and the cloud protection store. To display protection-stores related to the protection store gateway, I used the parameter filter to display the exact the protection-store associated with protection storage gateway of“<onprem-protection-store-id>”. The filter parameter that I used areprotectionStoreType eq 'ON_PREMISES'andstorageSystemInfo/id eq 'protection-store-gateway-id'. Additionally, I used the followingselectparametername,displayName,id,status,state,protectionStoreTypeto provide a shorter response that simplify the discovery of the protection-store on-premises. The API used for this:GET /backup-recovery/v1beta1/protection-stores?select=name,displayName,id,status,state,protectionStoreType&filter=protectionStoreType eq ‘ON_PREMISES’ and storageSystemInfo/id eq “\<protection-store-gateway-id\>”
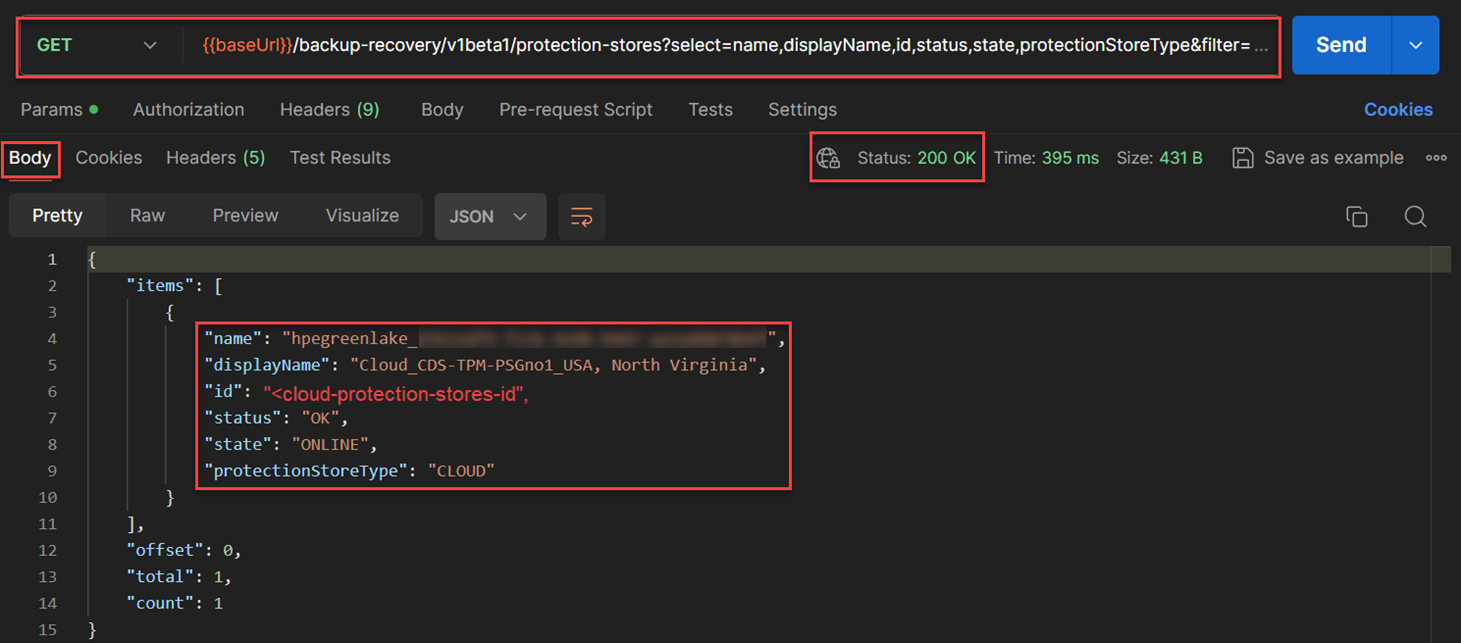
I repeated the same execution of the
GET /backup-recovery/v1beta1/protection-storesto obtain the"<cloud-protection-store-id>". To accomplish that, I used the followingfilter: protectionStoreType eq 'CLOUD' and storageSystemInfo/id eq “<protection-store-gateway-id>”. Additionally, I also used the parameterselect: name,displayName,id,status,state,protectionStoreTypeto provide a shorter response for simpler discovery of the protection-store-id in the cloud. The API used for this:GET /backup-recovery/v1beta1/protection-stores?select=name,displayName,id,status,state,protectionStoreType&filter=protectionStoreType eq ‘CLOUD’ and storageSystemInfo/id eq “<protection-store-gateway-id>”
- For the next step, I created a request body JSON structure that represents the protection policy schedule and each of the protection stores. Inside this JSON structures for request body, I defined the three objects that represent the
SNAPSHOT, BACKUP (on-premises), CLOUD_BACKUP. Note that this structure can be expanded or contracted depending on the required backup strategy. The SNAPSHOT object did not require"<protection-store-Id>"as that recovery points will exist inside the primary storage array. This request JSON body structure was required to create the protection policy using HPE GreenLake APIPOST /backup-recovery/v1beta1/protection-policies.
Note: I didn’t include objects for immutability, prescript, and postscript into the JSON structure. If it’s not intended, you don’t need to include unused key-pair values into the JSON structure. Additionally, the SNAPSHOT object does no require a
protectionStoreId.
{ "name": "VMware create three tiers", "description": "Snapshot-local-cloud", "protections": [ { "type": "SNAPSHOT", "schedules": [ { "scheduleId": 1, "name": "Array_Snapshot_1", "namePattern": { "format": "Array_Snapshot_{DateFormat}" }, "expireAfter": { "unit": "DAYS", "value": 1 }, "schedule": { "recurrence": "HOURLY", "repeatInterval": { "every": 4 }, "activeTime": { "activeFromTime": "00:00", "activeUntilTime": "23:59" } } } ] }, { "type": "BACKUP", "protectionStoreId": "<onprem-protection-store-id>", "schedules": [ { "scheduleId": 2, "name": "On-Premises_Protection_Store_2", "sourceProtectionScheduleId": 1, "namePattern": { "format": "On-Premises_Protection_Store_{DateFormat}" }, "expireAfter": { "unit": "DAYS", "value": 3 }, "schedule": { "recurrence": "DAILY", "repeatInterval": { "every": 1 }, "startTime": "00:00" } } ] }, { "type": "CLOUD_BACKUP", "protectionStoreId": "<cloud-protection-stores-id>", "schedules": [ { "scheduleId": 3, "name": "HPE_Cloud_Protection_Store_3", "sourceProtectionScheduleId": 2, "namePattern": { "format": "HPE_Cloud_Protection_Store_{DateFormat}" }, "expireAfter": { "unit": "WEEKS", "value": 1 }, "schedule": { "recurrence": "DAILY", "repeatInterval": { "every": 2 }, "startTime": "00:00" } } ] } ], "applicationType": "VMWARE" }
The above figure shows JSON structure for request body of
POST /backup-recovery/v1beta1/protection-policiesfor the creation of protection-policy as shown by the example in this section.
- Finally, I created the protection policies using the HPE GreenLake API for Backup and Recovery
POST /backup-recovery/v1beta1/protection-policies, and I used the above JSON structure in the request body. This is a special POST API execution where the response is returned immediately. The response of this API contained the body of JSON structure that will be useful to identify the protection-jobs such as the“<protection-policies-id>”.
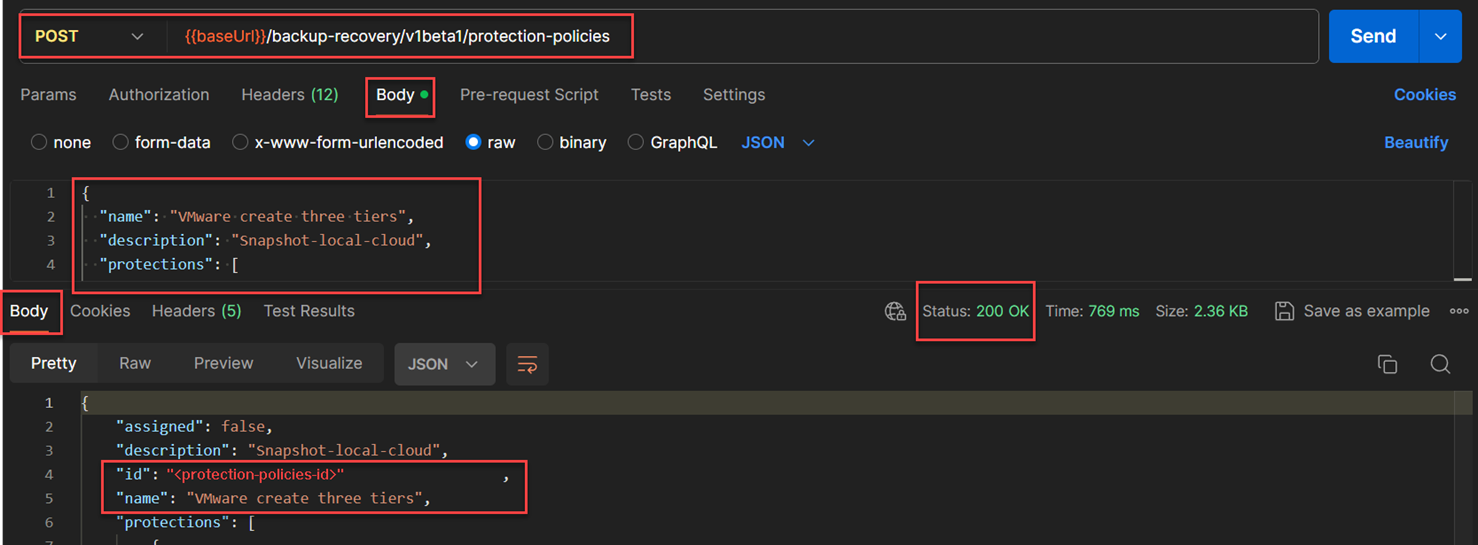
The below figure shows the complete response JSON body from the above API that shows the construction of the protection policy with different protection tiers and the schedules associated with the protection tier. The important values were the ids for different protection tiers that will be used for the next example.
ID: “<protection-policies-id>" SNAPSHOT: “<snapshot-protection-id>” ON-PREMISES: “<onprem-protection-id>” CLOUD: “<cloud-protection-id>”
The full listing of the response body from
POST /backup-recovery/v1beta1/protection-policiesis shown in the below code snippet:{ "assigned": false, "description": "Snapshot-local-cloud", "id": "<protection-policies-id", "name": "VMware create three tiers", "protections": [ { "id": "<snapshot-protection-id>", "schedules": [ { "scheduleId": 1, "name": "Array_Snapshot_1", "schedule": { "activeTime": { "activeFromTime": "00:00", "activeUntilTime": "23:59" }, "recurrence": "HOURLY", "repeatInterval": { "every": 4 } }, "expireAfter": { "unit": "DAYS", "value": 1 }, "namePattern": { "format": "Array_Snapshot_{DateFormat}" } } ], "type": "SNAPSHOT" }, { "id": "<onprem-protection-id>", "schedules": [ { "scheduleId": 2, "sourceProtectionScheduleId": 1, "name": "On-Premises_Protection_Store_2", "schedule": { "recurrence": "DAILY", "repeatInterval": { "every": 1 }, "startTime": "00:00" }, "expireAfter": { "unit": "DAYS", "value": 3 }, "namePattern": { "format": "On-Premises_Protection_Store_{DateFormat}" } } ], "protectionStoreInfo": { "id": "onprem-protectio-store-id", "name": "Local_CDS-TPM-PSG#1", "type": "backup-recovery/protection-store", "resourceUri": "/backup-recovery/v1beta1/protection-stores/501a99e7-fb79-4fd7-89d5-a5dfb3441859", "protectionStoreType": "ON_PREMISES" }, "type": "BACKUP" }, { "id": “<cloud-protection-id>”, "schedules": [ { "scheduleId": 3, "sourceProtectionScheduleId": 2, "name": "HPE_Cloud_Protection_Store_3", "schedule": { "recurrence": "DAILY", "repeatInterval": { "every": 2 }, "startTime": "00:00" }, "expireAfter": { "unit": "WEEKS", "value": 1 }, "namePattern": { "format": "HPE_Cloud_Protection_Store_{DateFormat}" } } ], "protectionStoreInfo": { "id": "cloud-protection-store-id", "name": "Cloud_CDS-TPM-PSGno1_USA, North Virginia", "type": "backup-recovery/protection-store", "region": "USA, North Virginia", "resourceUri": "/backup-recovery/v1beta1/protection-stores/25611df9-xxxx-xxxx-xxxx-aa3a4887869f", "protectionStoreType": "CLOUD" }, "type": "CLOUD_BACKUP" } ], "createdAt": "2024-04-05T03:28:03.000000Z", "createdBy": { "id": "<user-id>", "name": "ronald.dharma@hpe.com" }, "generation": 1, "resourceUri": "/backup-recovery/v1beta1/protection-policies/f572ce6e-xxxx-xxxx-xxxx-530284bf2bc4", "consoleUri": "/backup-and-recovery/protection-policies/f572ce6e-xxxx-xxxx-xxxx-530284bf2bc4", "applicationType": "VMWARE", "type": "backup-recovery/protection-policy", "updatedAt": "2024-04-05T03:28:03.000000Z" }
Applying protection policy to a Virtual Machine
Next in the list of use cases for this blog post, I followed the progression for the Day One activities. The next one is to protect a virtual machine that is applying this protection policy to a virtual machine.
These are the steps required to apply the protection policy against a virtual machine:
I obtained the values from
virtual machine id, name, and typekeys that were going to be used as the key-pair values required for the keyassetInfoas shown in below figures. To obtain those, I used one of the HPE GreenLake API from Virtualization API set to discover the detail information of a virtual machine“0-Linux-Demo-VM02”. The API used for this:GET /virtualization/v1beta1/virtual-machines?sort=name desc& select=appType,id,name,type,guestInfo,protectionJobInfo& filter=name eq '0-Linux-Demo-VM02'
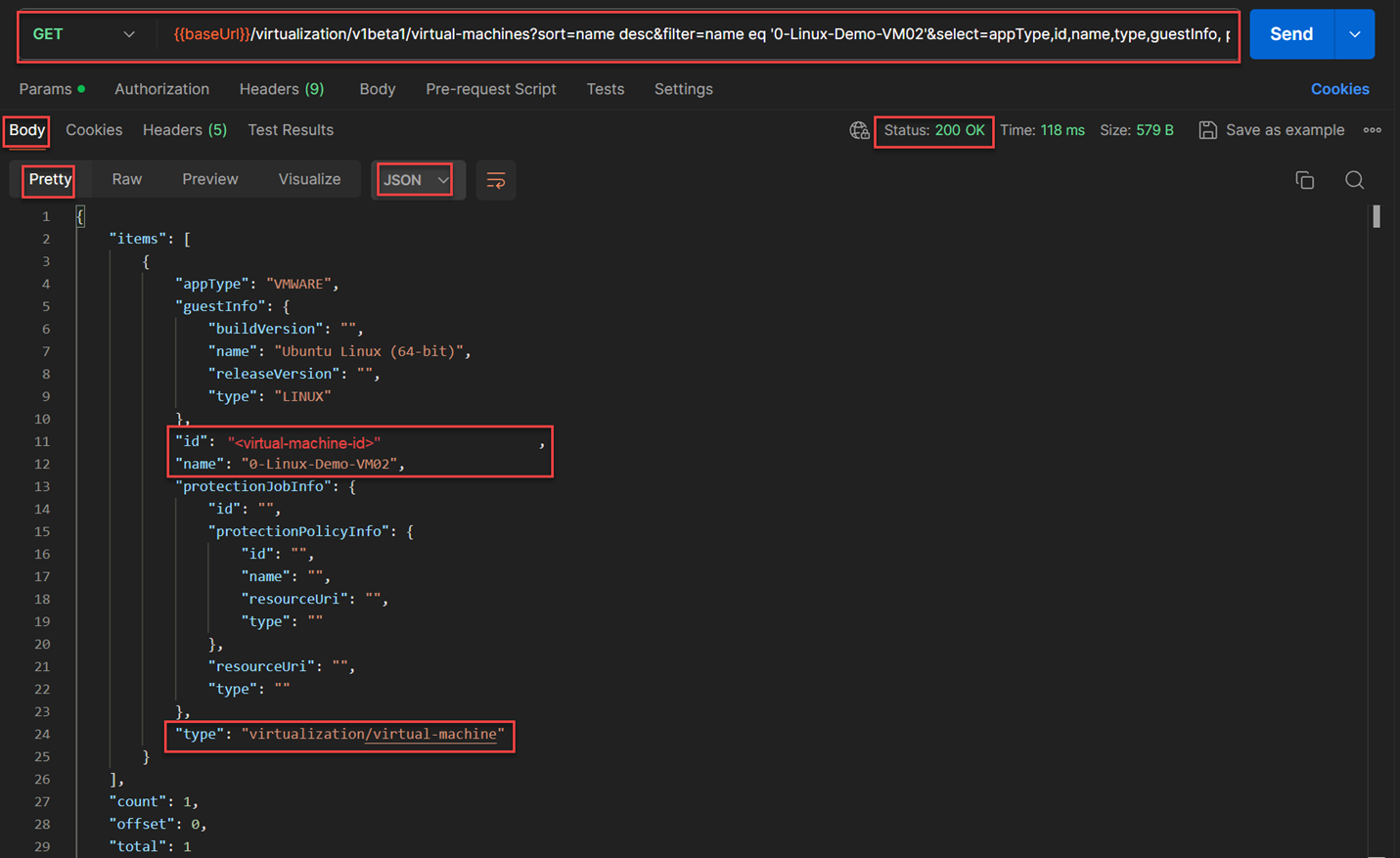
- I created a JSON structure of a request body for applying the protection policy against a virtual machine without a protection group to make a simple example for this blog post. Note that this JSON body structure created the association of the asset, which is a virtual machine, against the protection policy. The two other parameters entered here were the consistency
(CRASH vs APPLICATION)and technology for protection(VMWARE_CBT vs VOLUME). The three values obtained from previous response of the previous APIPOST /backup-recovery/v1beta1/protection-policiesassociated with SNAPSHOT, BACKUP and CLOUD would be used as part of this request body. Each of these protections will be identified with schedule id marked 1,2 and 3 as shown below. There are other options available as part of this JSON structure of this request body, and they are documented in the Payload tab of this interactive guide for this API.
Note: As of March 2024, value of
typefromvirtualization/virtual-machinewas translated tohybrid-cloud/virtual-machine.{ "assetInfo":{ "id": ”<virtual-machine-id>”, "type":"hybrid-cloud/virtual-machine", "name":"0-Linux-Demo-VM02" }, "protectionPolicyId”: “<protection-policies-id>”, "overrides":{ "protections":[ { "id": “<snapshot-protection-id>”, "schedules":[ { "scheduleId":1, "consistency":"CRASH", "backupGranularity":"VMWARE_CBT" } ] }, { "id": “<backup-protection-id>”, "schedules":[ { "scheduleId":2, "consistency":"CRASH", "backupGranularity":"VMWARE_CBT" } ] }, { "id": “<cloud-protection-id>”, "schedules":[ { "scheduleId":3, "consistency":"CRASH", "backupGranularity":"VMWARE_CBT" } ] } ] } }
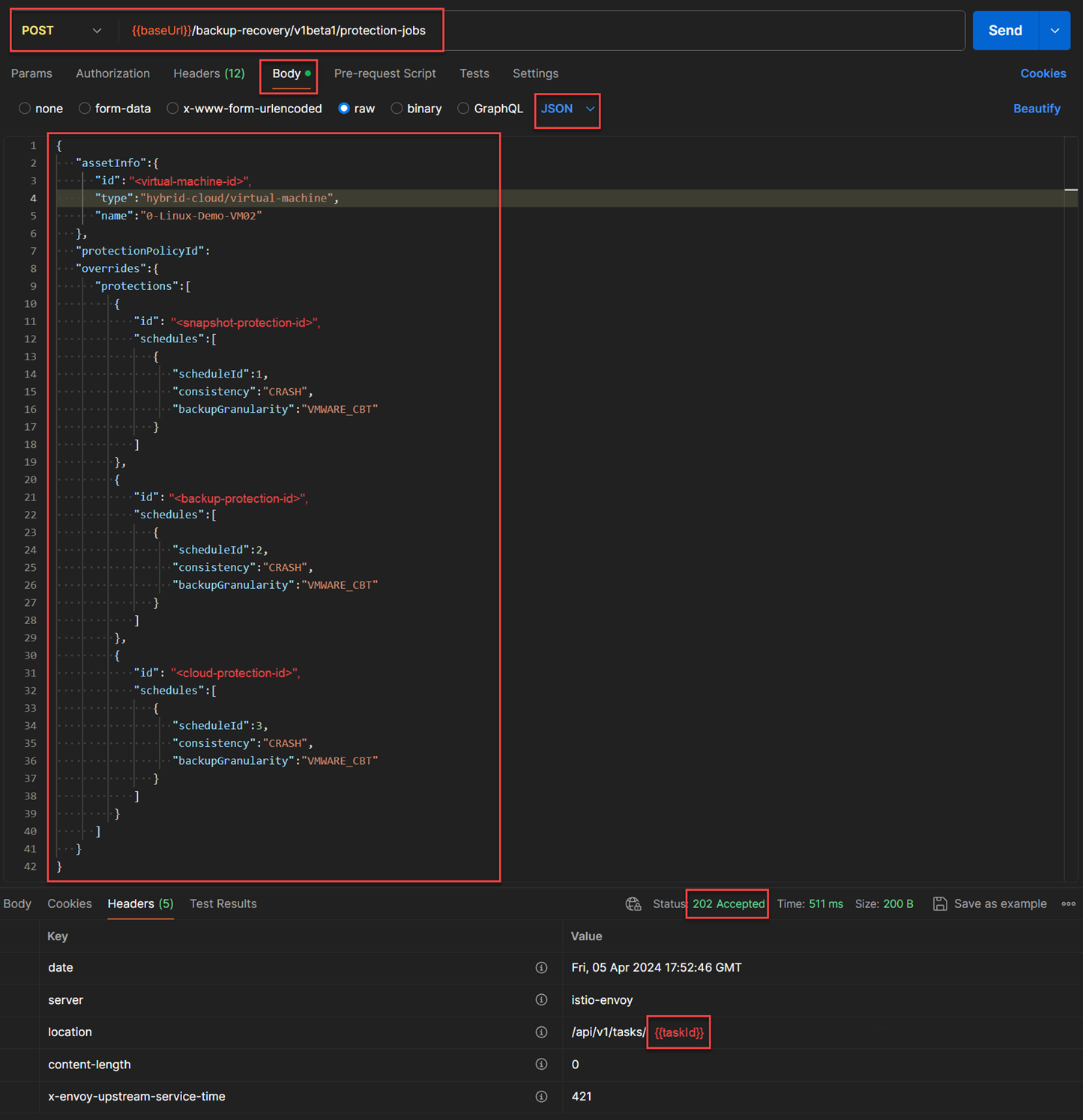
- In the figure below, I used HPE GreenLake API for Backup and Recovery
POST /backup-recovery/v1beta1/protection-jobswith the body JSON structure from the above so that I could associate the protection policy against a virtual machine. This POST API execution completed asynchronously and returned Status0x202with a response. The response header contained the{{taskId}}that I can use to ensure that this API completed properly.
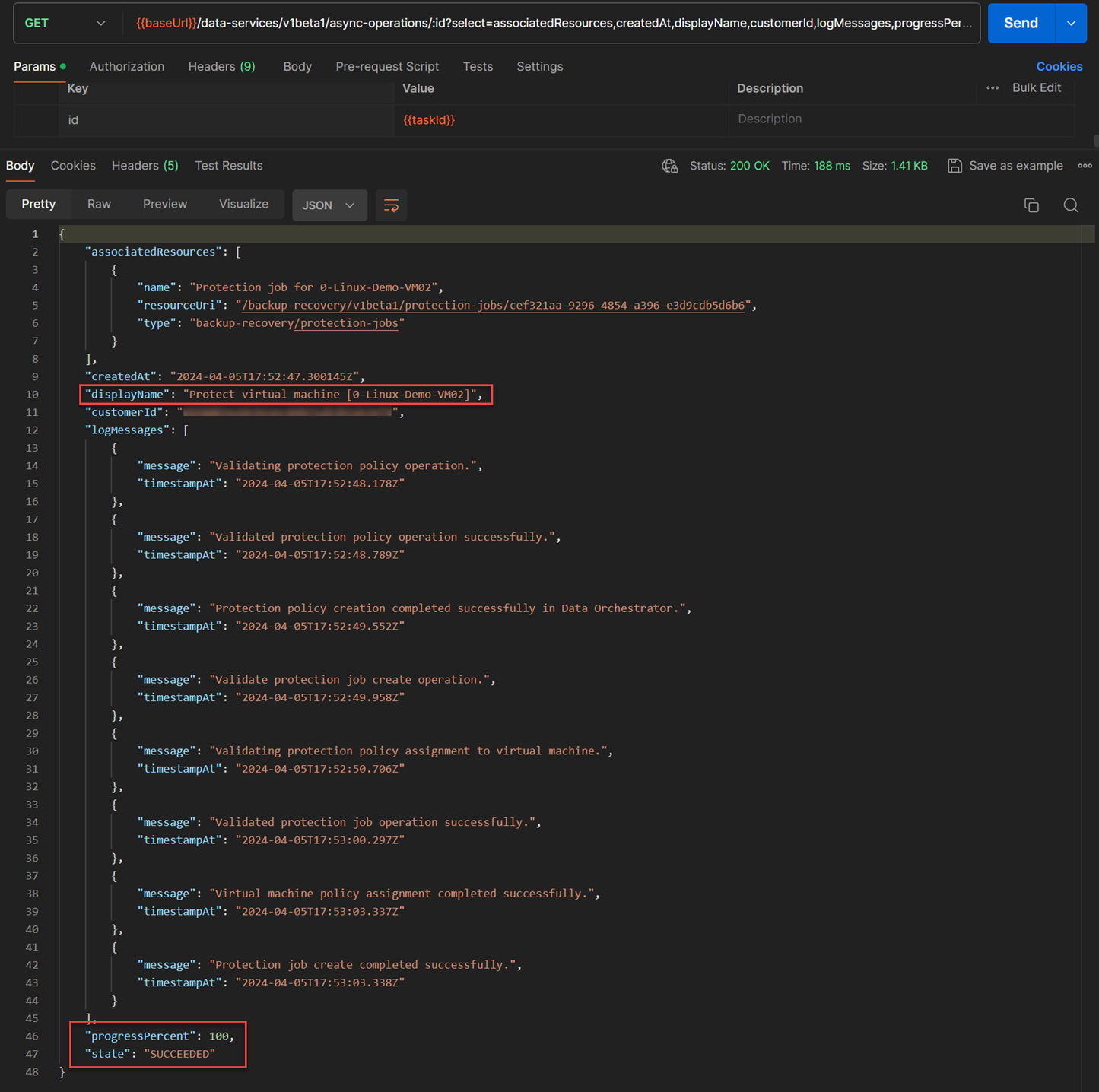
- The API execution was executed successfully. I validated this completion using the task id that I obtained from the response headers as shown above. The API used for this:
GET /data-services/v1beta1/async-operations/{{taskId}}
Note: The execution of this API will trigger a protection execution right after the execution of this API completed.
Triggering a protection
Once the protection policy named "VMware create three tiers" was bound to the virtual machine as shown above, I then issued a trigger to create cloud protection against the virtual machine “0-Linux-Demo-VM02” to create one-off cloud-protection.
The steps required to trigger the protection are listed below:
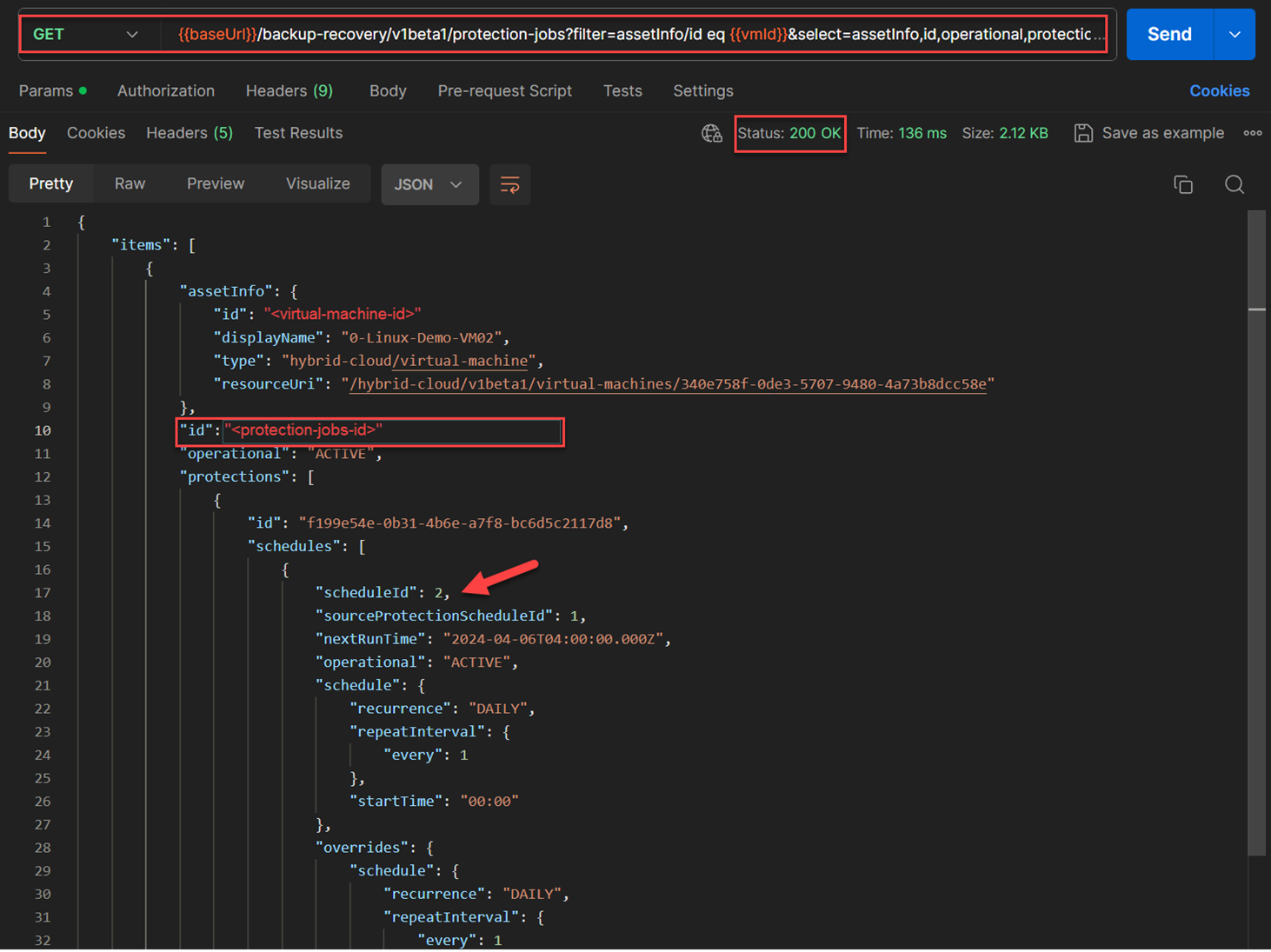
I figured out the
protection-job-idthat is associated with“0-Linux-Demo-VM02”. and the cloud backupschedule Idof the virtual machine. To achieve that, I used the HPE GreenLake API for Backup and RecoveryGET /backup-recovery/v1beta1/protection-jobsandfilter assetInfo/id eq "{VM-id}”as shown below. Note that the variable{vmId}contained the value of the virtual machine id as discovered in previous example, namely"<virtual-machine-id>". The response body’s JSON structure contained the id of the protection job associated with“0-Linux-Demo-VM02”. From the same response body, I recognized that cloud protection is thescheduleId no 3. The API used for this:GET /backup-recovery/v1beta1/protection-jobs?filter=assetInfo/id eq {{vmId}}&select=assetInfo,id,operational,protections
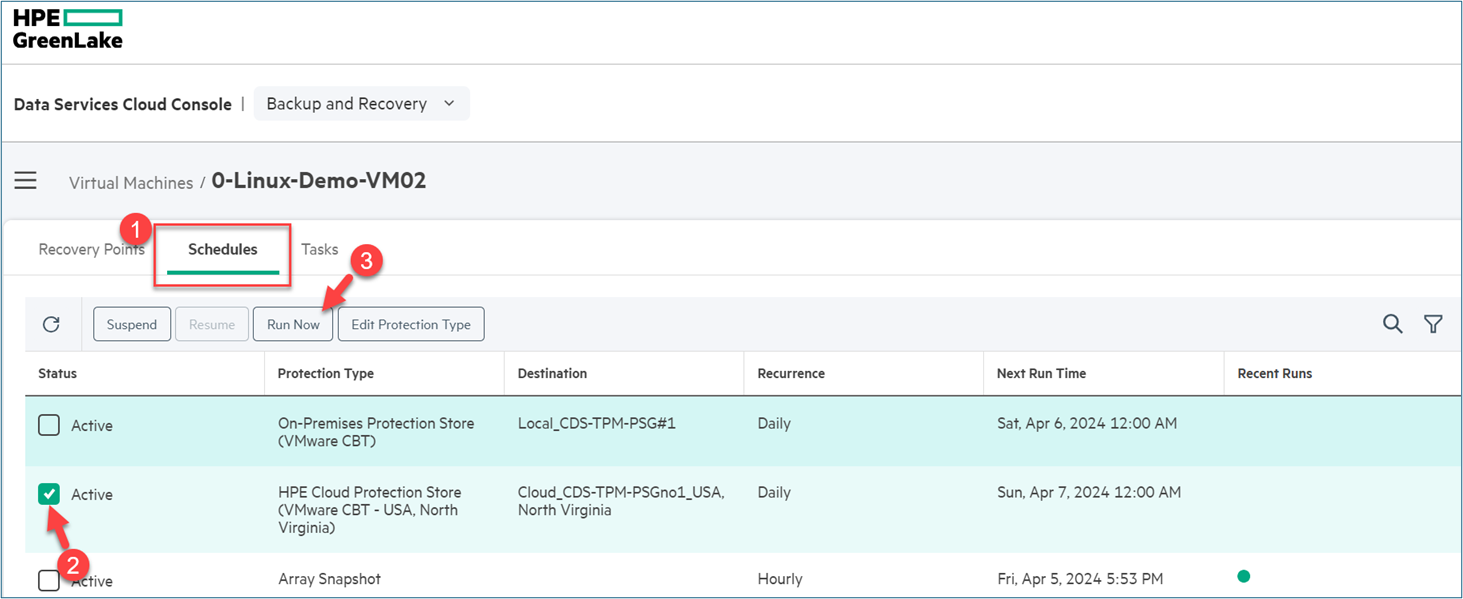
- This use case is equivalent to run now button at the schedule of the
“0-Linux-Demo-V02”on the selected cloud protection as shown in below figure. After clicking“Run Now”button, a cloud protection will commence against the virtual machine, a recovery point is going to be created at the cloud protection store. In next step, I will invoke"Run Now"on theHPE Cloud Protection Storeusing HPE GreenLake API for Backup and Recovery.
The HPE GreenLake API used to accomplish the use case shown above was
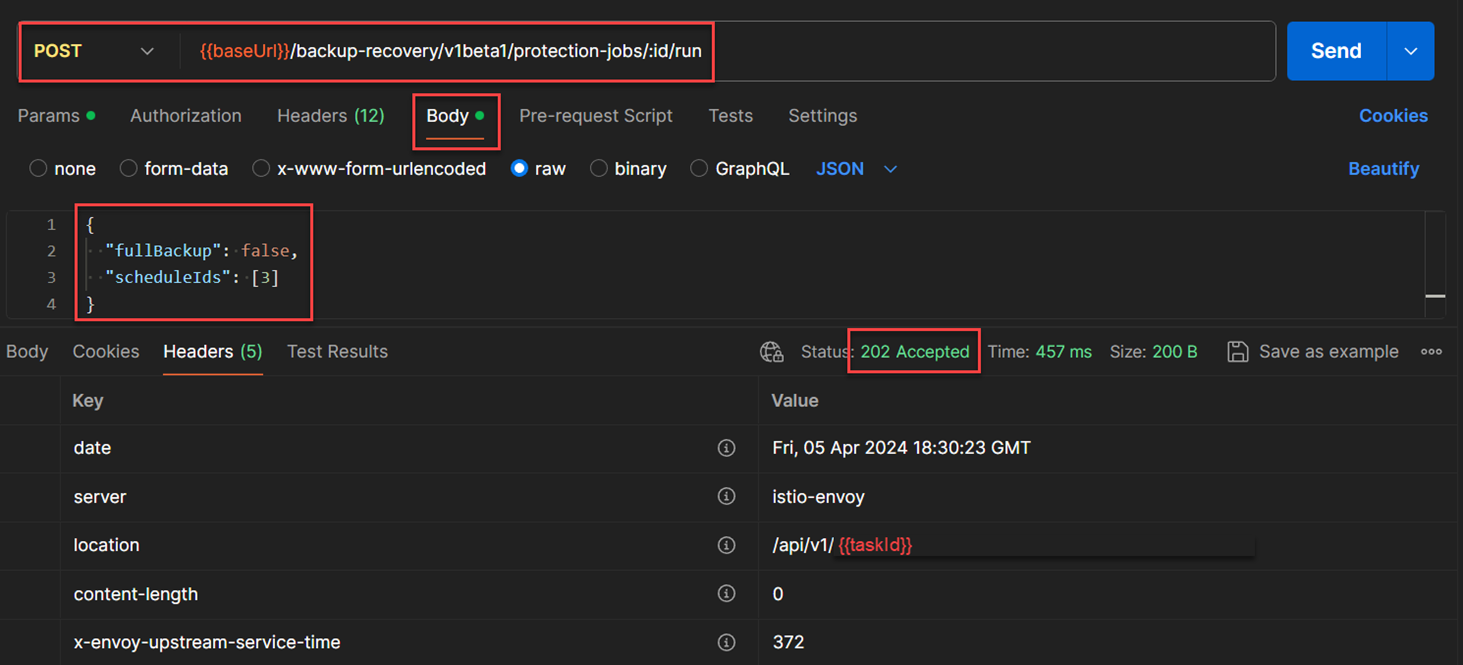
POST /backup-recovery/v1beta1/protection-jobs/:id/run, and the documentation of this API also lists the required JSON structure for the request body. I created a JSON request body structure for this example as follows:{ "fullBackup": false, "ScheduleIds": [3] }
Note: There is a key called
“fullBackup”inside the JSON request body to enable the creation of full protection where a backup will be created independently from the existing copies in the protection store. I also entered number 3 intoScheduleIdsJSON array, to represent the cloud backup schedule. The below figure shows an example of the execution of"run now"without full backup protection of the third schedule, which is cloud protection of this virtual machine. The value<protection-jobs-id>will be entered from the parameter of this API in this manner:POST /backup-recovery/v1beta1/protection-jobs/"<protection-jobs-id>"/run.
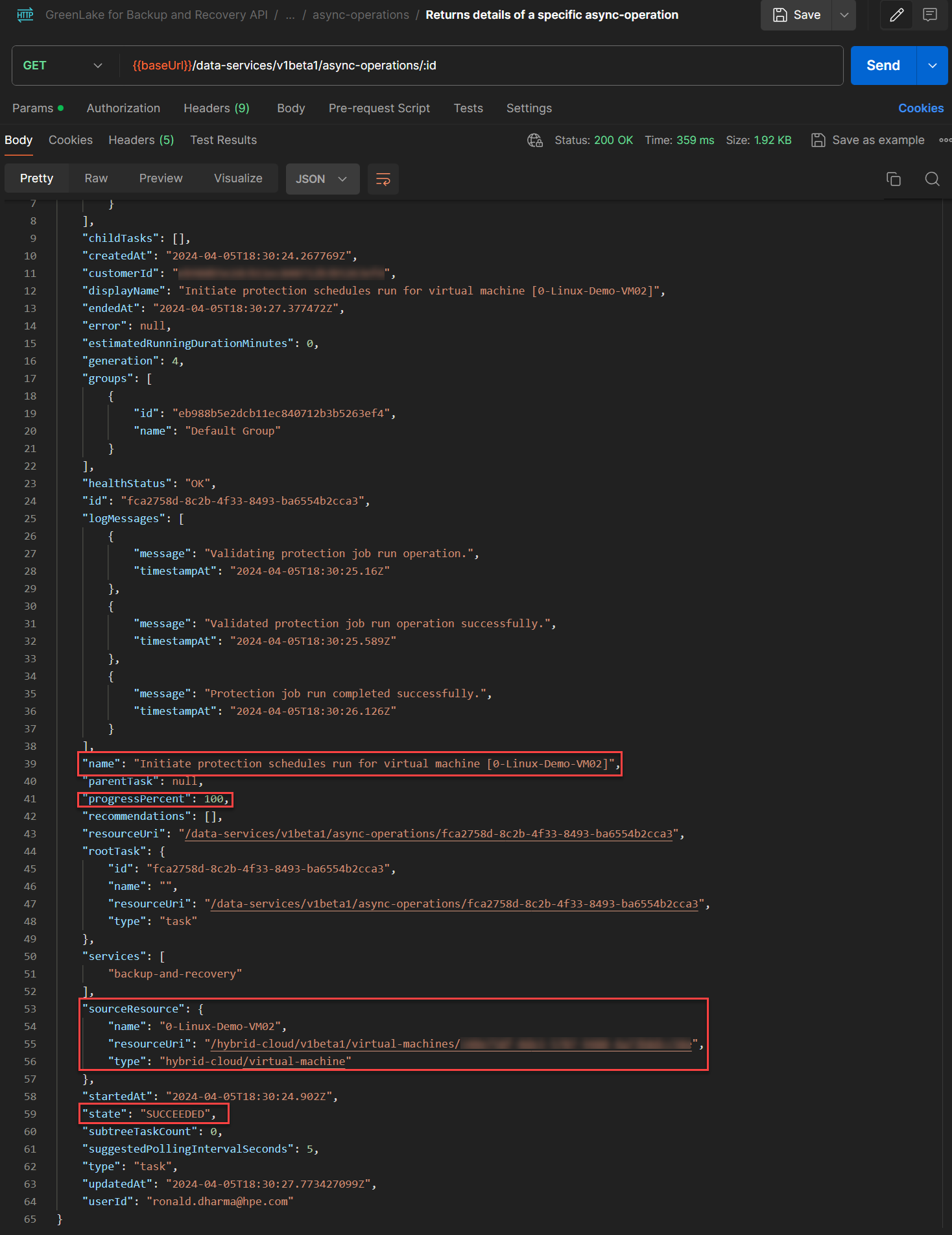
- The result from the API execution above can be validated from the API
/data-services/v1beta1/async-operations/:idusing the task id obtained from the above response header. The API used for this:GET /data-services/v1beta1/async-operations/{{taskId}}.
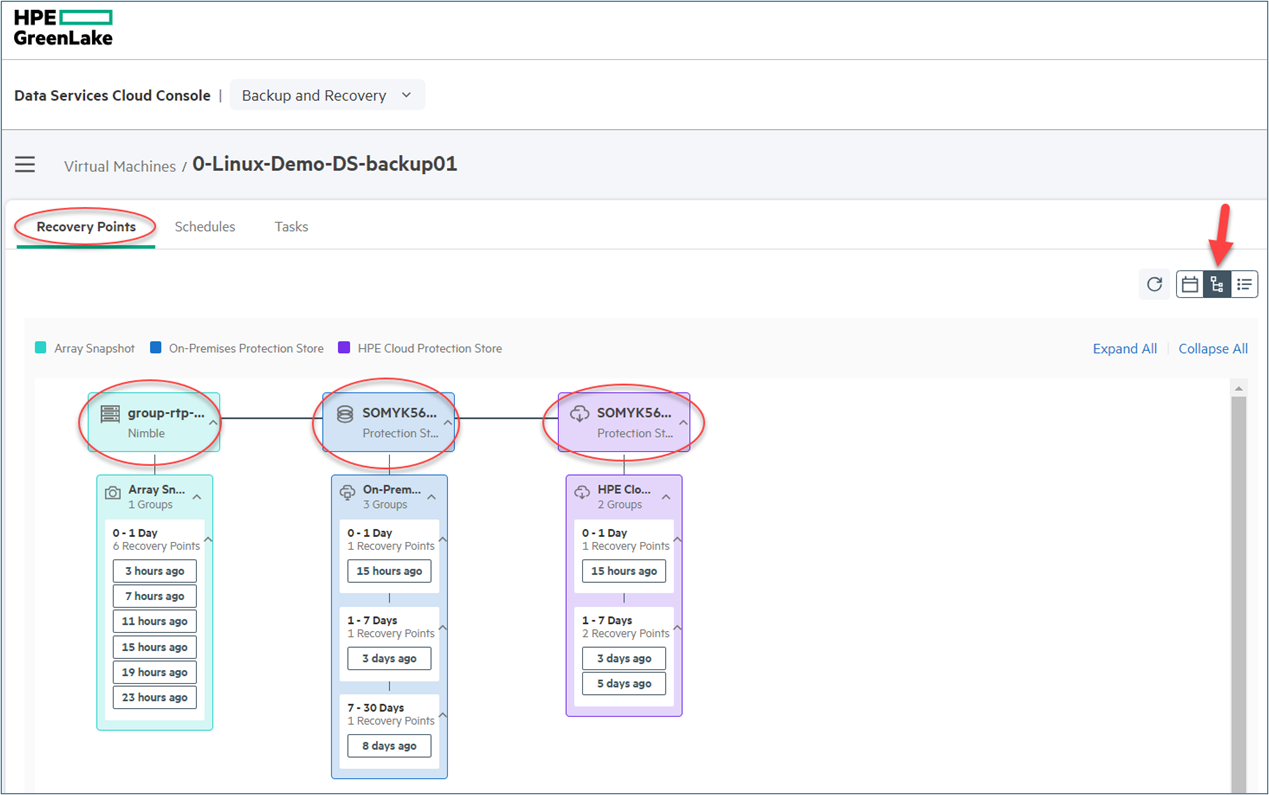
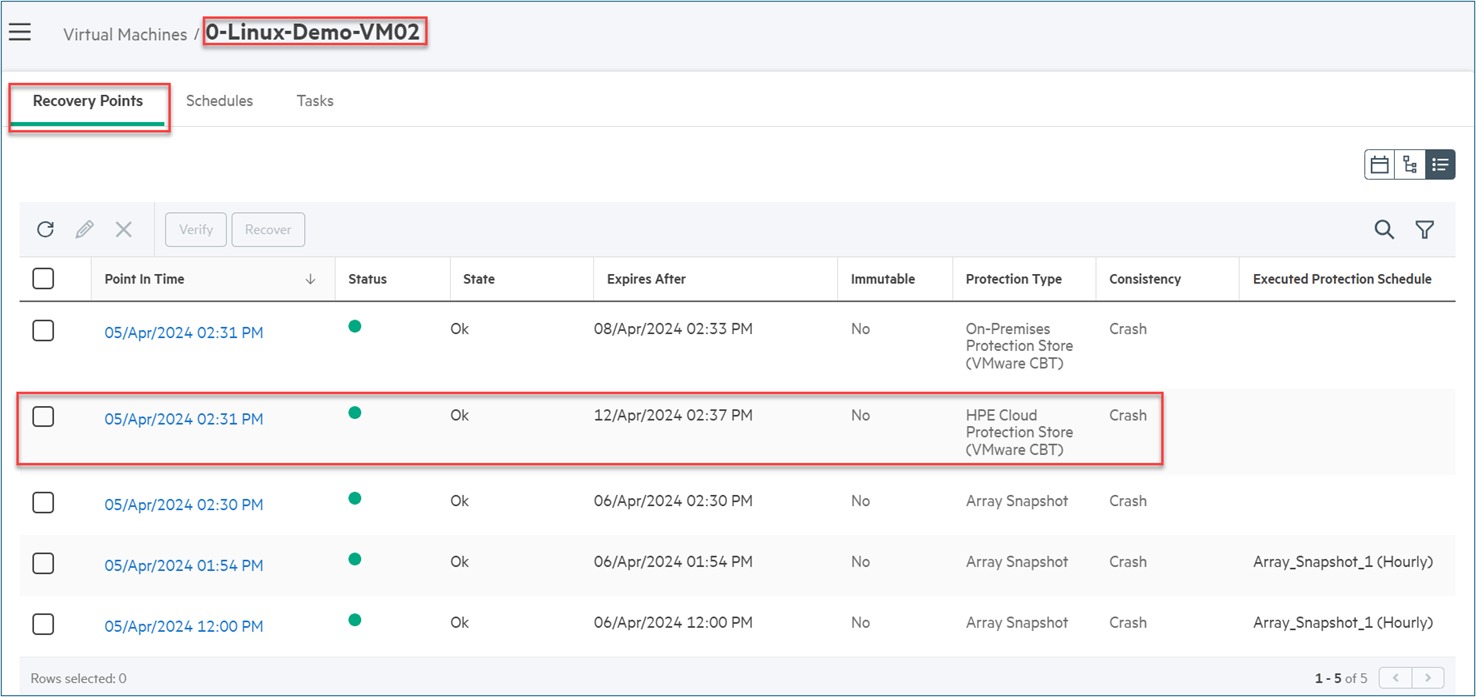
The activities above were validated from the HPE GreenLake Backup and Recovery list of the recovery points as shown in the figure below.
Wow.. those were so cool! Can I recover a new virtual machine from that recovery point that I just created?
Each of the recovery points, regardless of the location of store (array snapshot, On-Premises Protection-Store, or HPE Cloud Protection-Store), can be recovered using the HPE GreenLake APIs for Backup and Recovery.
To restore the backup from a virtual machine, this API requires a request body of JSON structure as documented in the HPE GreenLake developer website. In this blog post, I planned a demo of the steps to recover the virtual machine from a copy that had existed in the HPE Cloud Protection Store into the VMware cluster where the Protection Storage Gateway is hosted (recover as a new virtual machine). Copy the
{{vmId}}from the response JSON body to be used on subsequent API execution. The API used for this:GET /virtualization/v1beta1/virtual-machines?sort=name desc&filter=name eq’0-Linux-Demo-VM02’&select=appType,id,name,type,guestinfo,protectionJobInfo
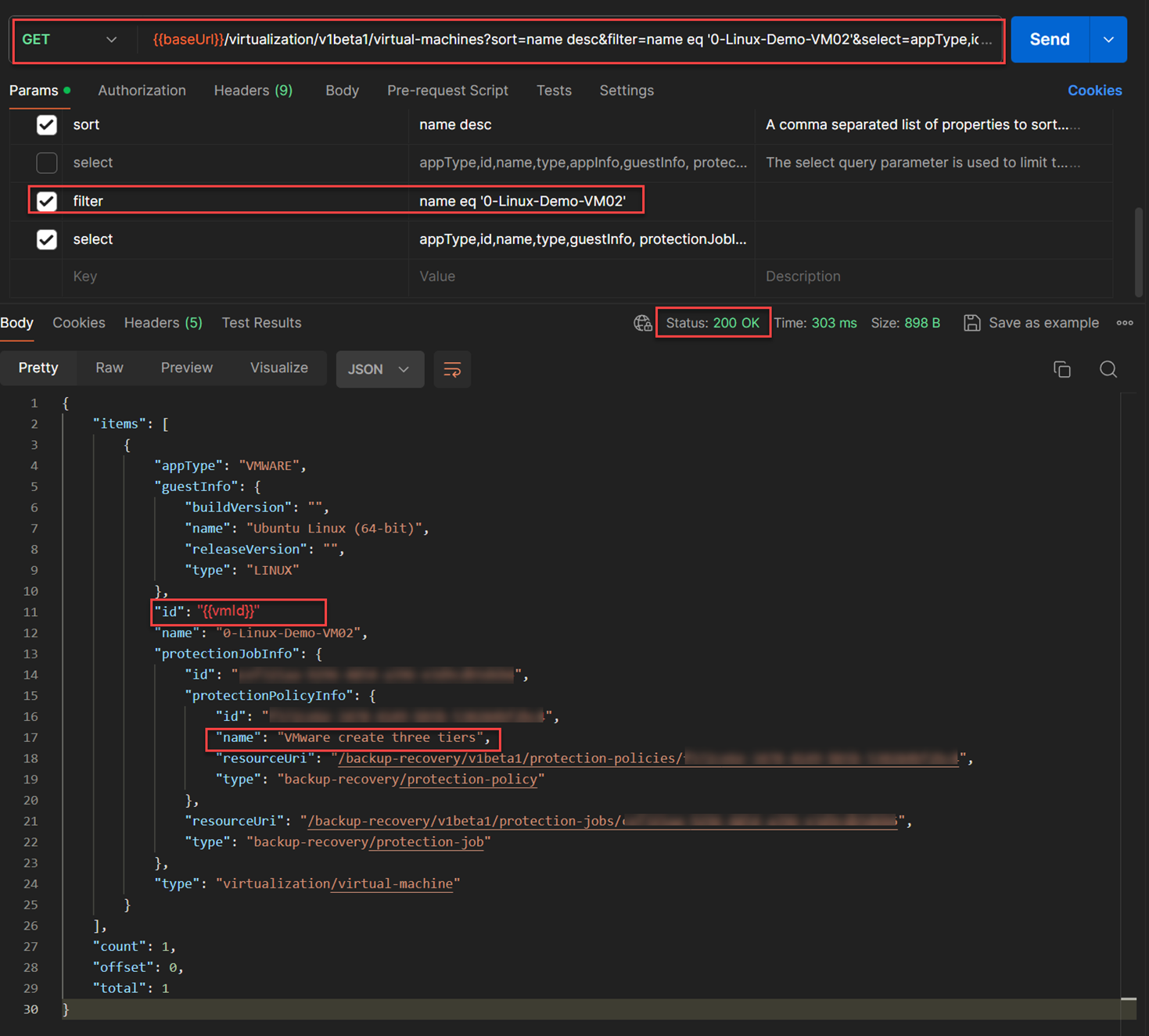
Let's obtain the Cloud Recovery Point id for the cloud protection recovery from the virtual machine id from the step #1 using the HPE GreenLake API
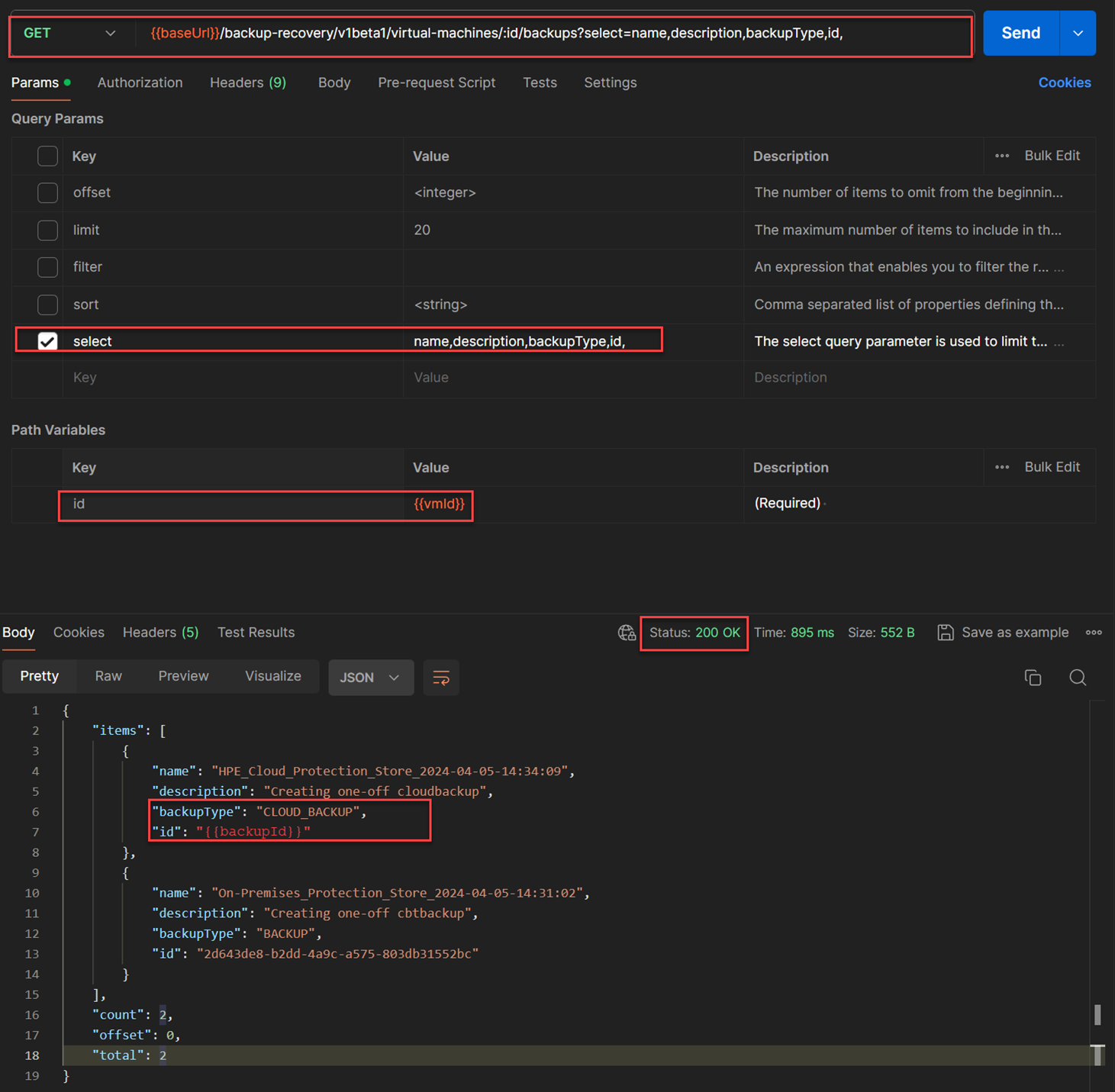
GET /backup-recovery/v1beta1/virtual-machines/:id/backupsgiven the virtual machine id{{vmId}}. Copy the{{backupId}}from the response body from the below figure so that it can be used in the subsequent API execution. The API used for this:GET /backup-recovery/v1beta1/virtual-machines/{{vmId}}/backups?select=name,description,backupType,id
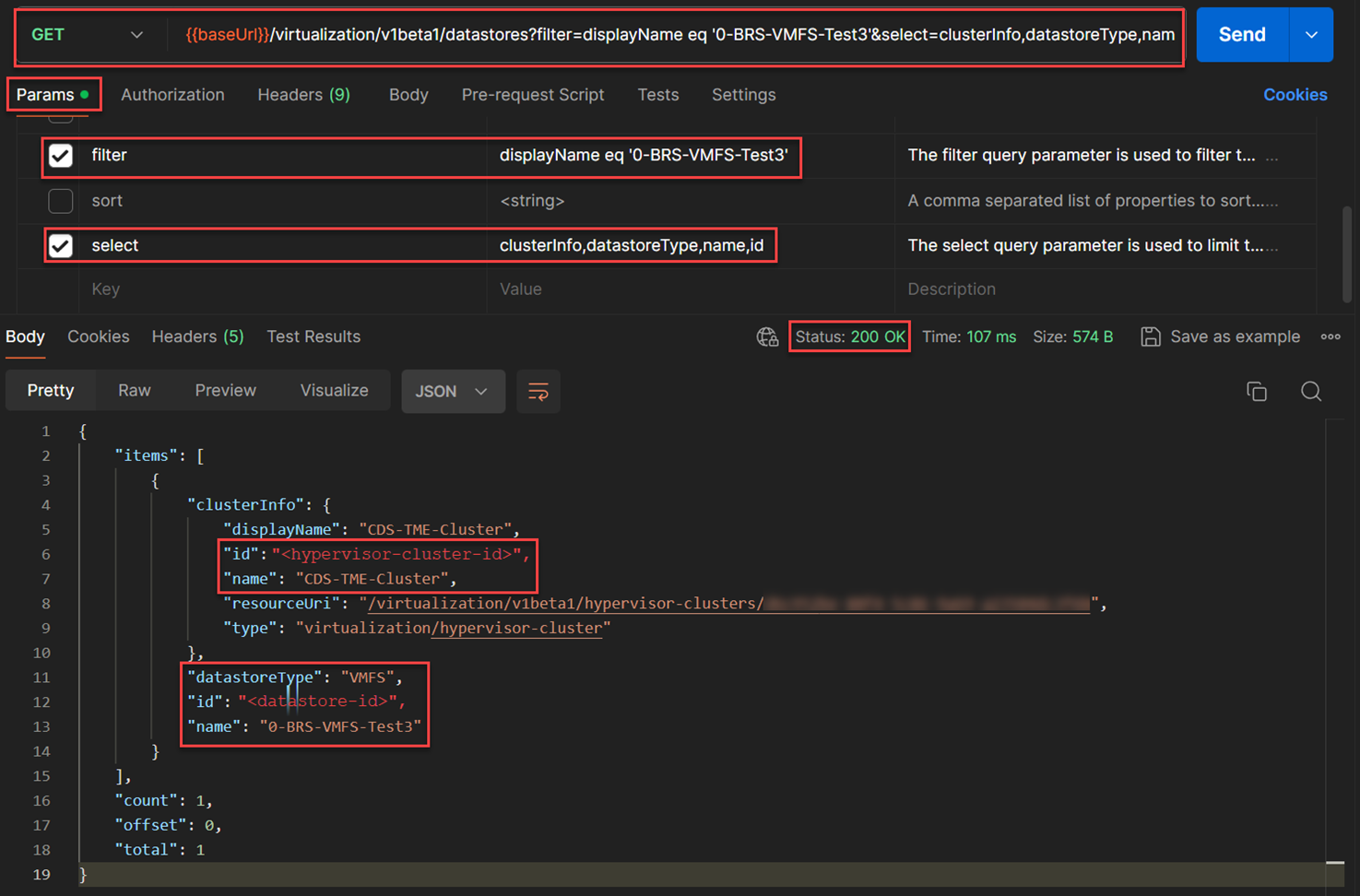
Let's obtain the
datastore idand thecluster idfrom the existing VMFS datastore that can accommodate the datastore type that this VM can be restored. In this hypervisor, I am using the datastore with the name“0-BRS-VMFS-Test3”and enter that as part of the filter into HPE GreenLake APIGET /virtualization/v1beta1/datastores. The API used for this:GET /virtualization/v1beta1/datastores?filter=displayName eq '0-BRS-VMFS-Test3'&select=clusterInfo,datastoreType,name,id
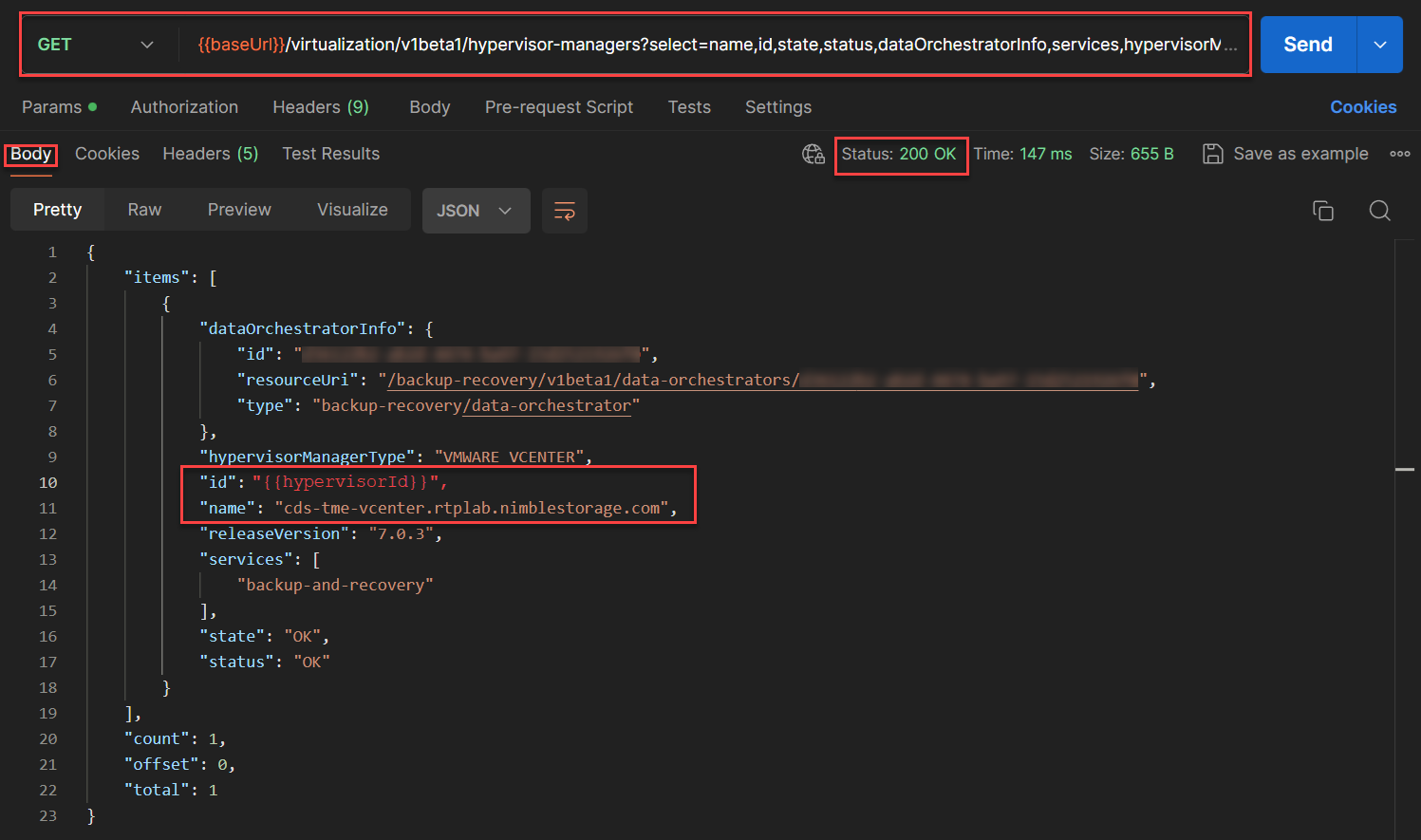
To obtain the hypervisor Network Id that is required to recover the recovery point into a new virtual machine, I had to discover the hypervisor id. The API used for this:
GET /virtualization/v1beta1/hypervisor-manager?select=name,id,state,status,dataOrchestratorInfo,services,hypervisorManagerType,releaseVersion&filter=state eq "OK" and status eq "OK" and name eq "vCenter Name"
To set the virtual machine network to the correct network port group, I'll need to look into into the existing virtual machine
"0-Linux-Demo-V02", and discovered the network port group“Mgmt-DPortGroup”. From the list of the network port group, I selected the associated network port group of the virtual machine by filtering the name of the port group. Afterward, we copied the"<hypervisor-network-id>"from the response body of this API to be used for subsequent execution. The API used for this:GET /virtualization/v1beta1/hypervisor-managers/{{hyperVisorId}}/networks?select=id,displayName&filter=displayName eq 'Mgmt-DPortGroup'
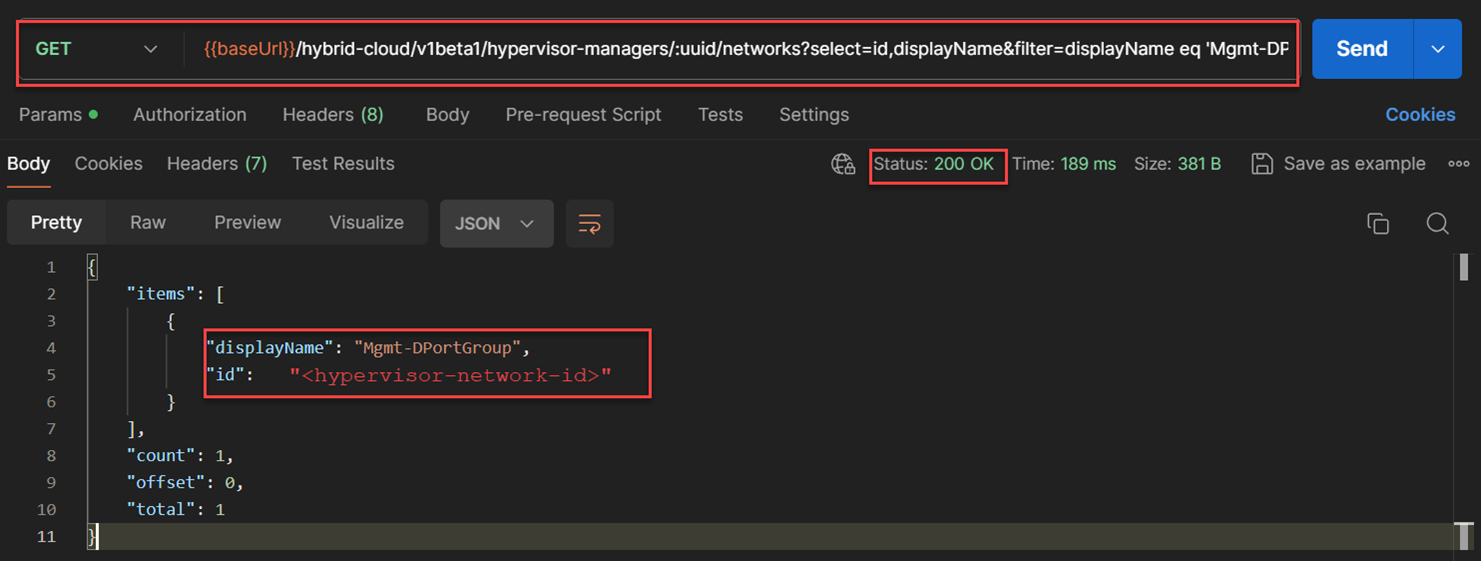
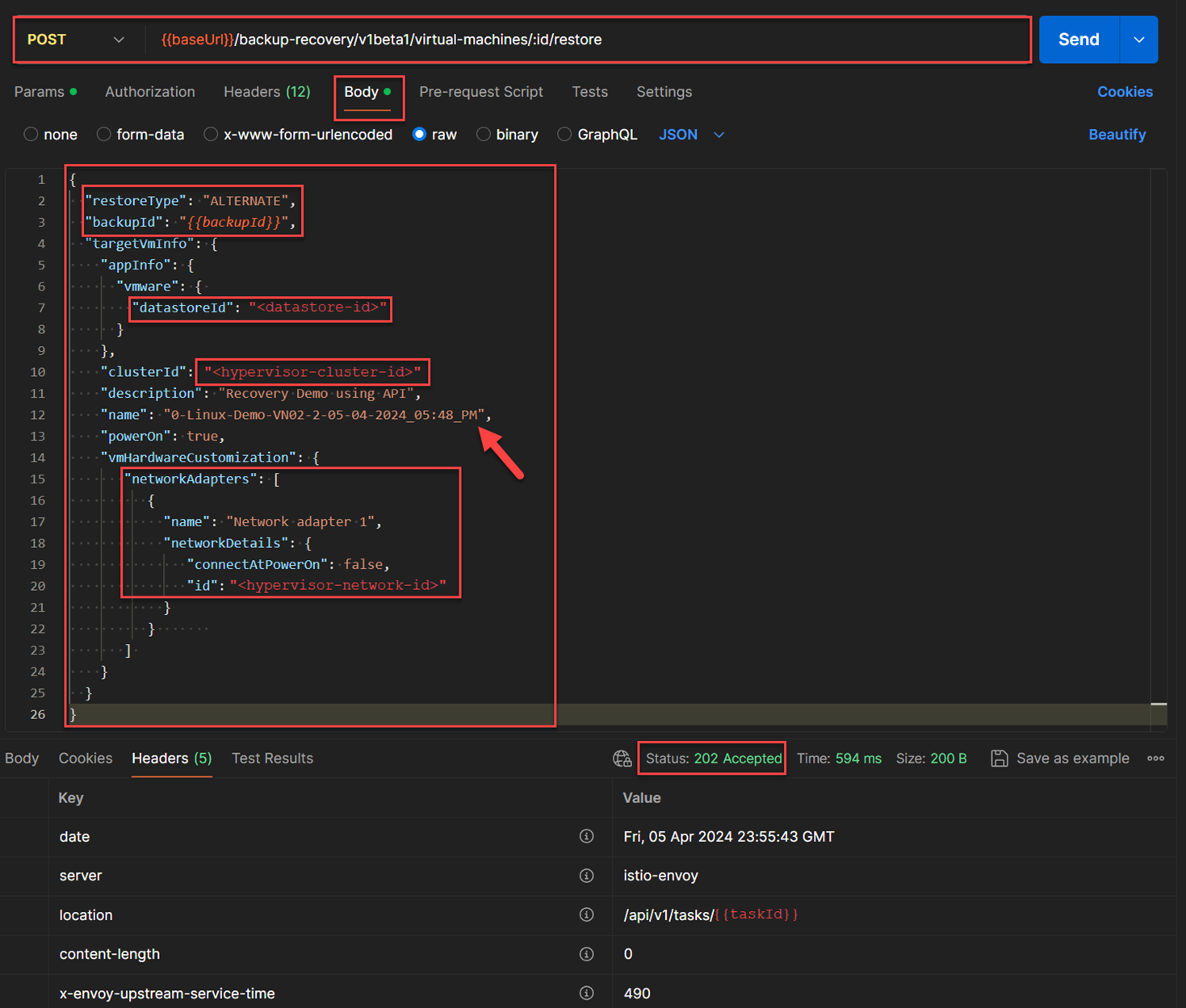
After I obtained all the values that were required to build the request body to recover a cloud recovery point from
“0-Linux-Demo-VM02", I constructed the JSON request body as shown in the below figure. To restore the recovery point into a new virtual machine, therestoreTypekey of the request body JSON structure was set to“ALTERNATE”as shown in the below figure. I also provided the new virtual machine name after the recovery as“0-Linux-Demo-VN02-2-05-04-2024_05:48_PM”. The API used for this:POST /backup-recovery/v1beta1/virtual-machines/{{vmId}}/restore
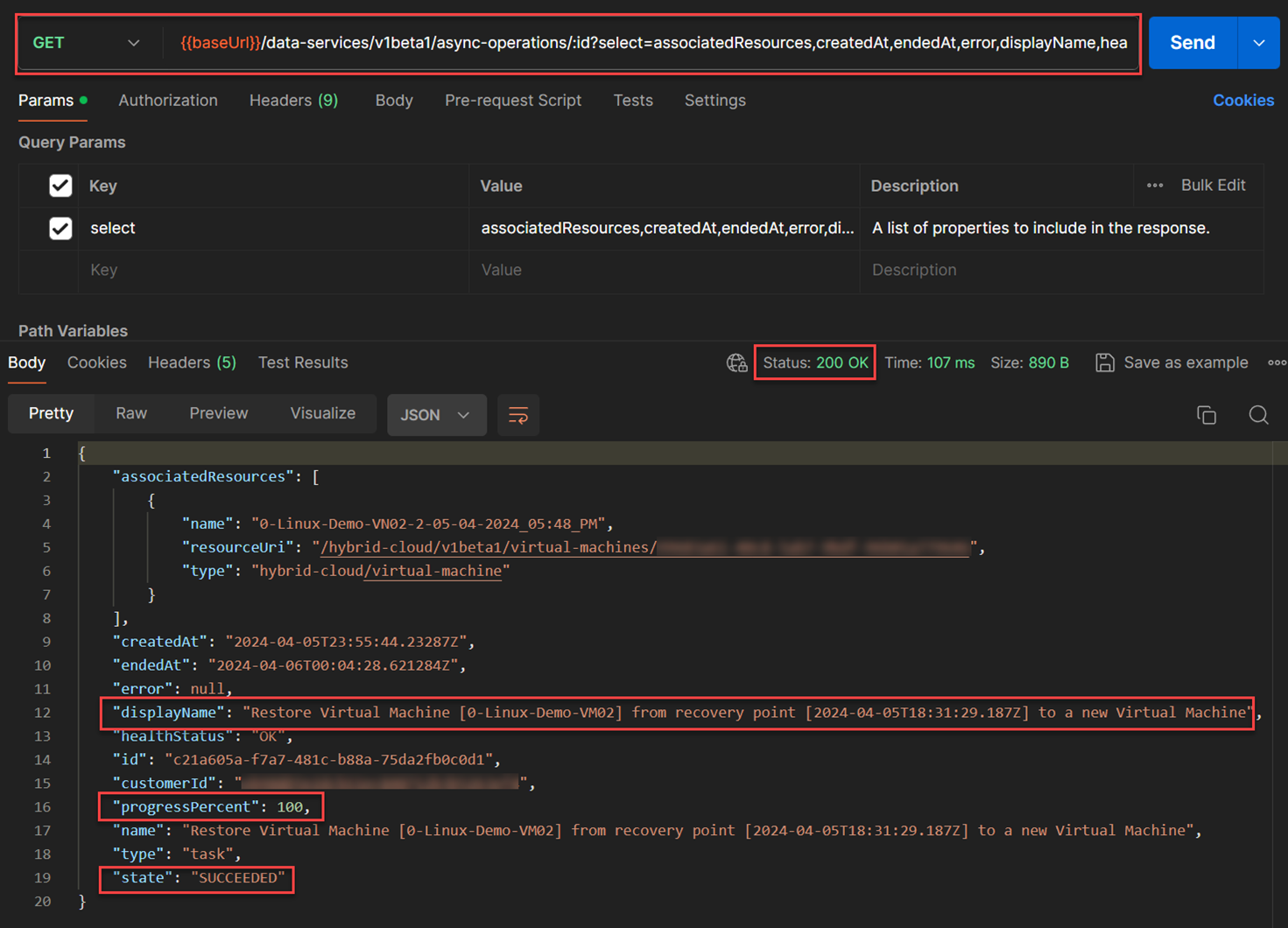
To validate that the recovery was completed, I tracked the progress from the response using the
async-operationsAPI based on{{taskId}}from previous execution as shown below. The API used for this:GET /data-services/v1beta1/async-operations/:id?select=associatedResources,createdAt,endedAt,error,displayName,healthStatus,id,customerId,progressPercent,name,type,state
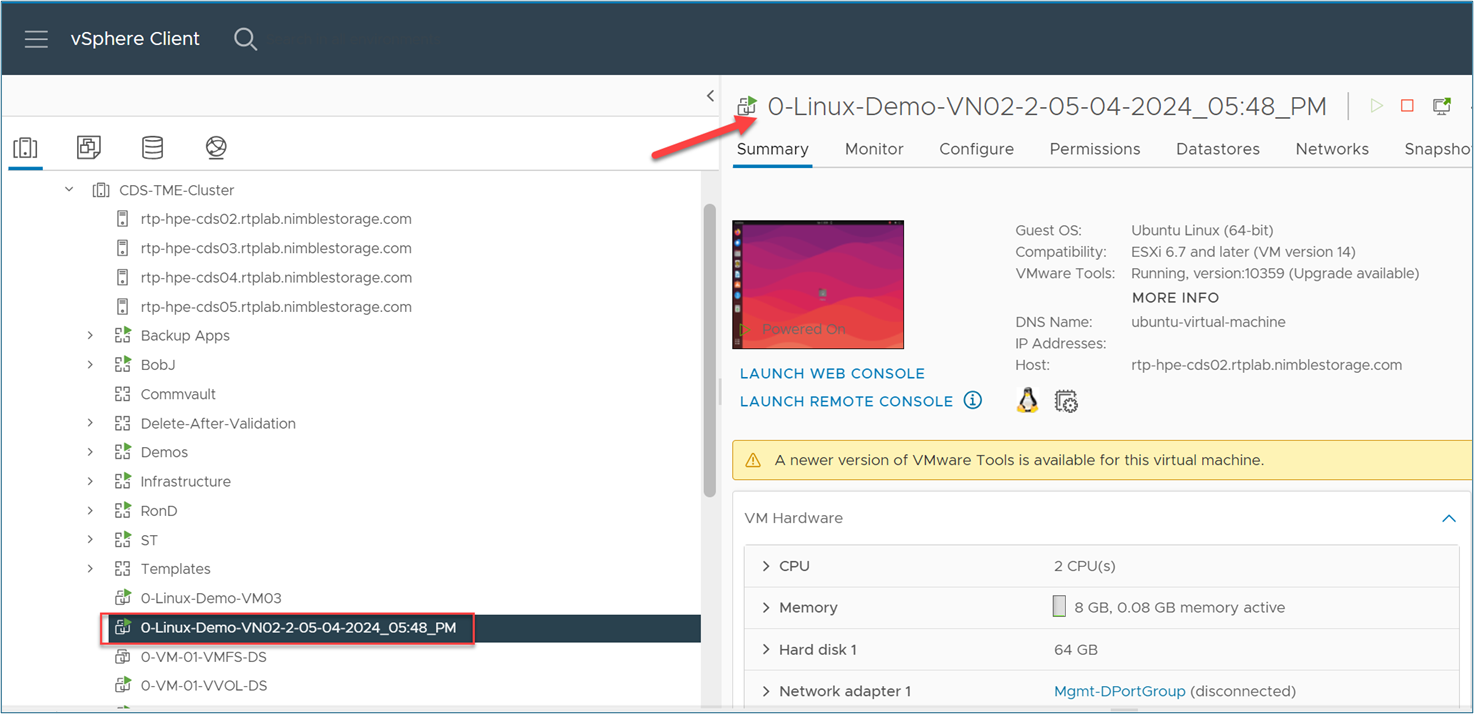
- At the end, I went to the VMware vCenter console used in this example to validate that the virtual machine 0-Linux-Demo-VN02-2-05-04-2024_05:48_PM was indeed part of the virtual machines inventory.
Summary
This blog post introduces the new set of REST API from the family of the APIs for data services on HPE Greenlake, namely HPE GreenLake API for Backup and Recovery. This set of APIs is documented at the HPE GreenLake for developer website using interactive documentation based on OpenAPI Standard version 3.1.
Early in this blog post, I laid down the relationship of the resources in this set of HPE GreenLake APIs with the objects in the HPE GreenLake Backup and Recovery user interface. In this blog post, I also introduced the examples from several use cases associated with utilizing HPE GreenLake for Backup and Recovery to provide virtual machine protection from day one.
The examples presented in this blog post provided some guides on using combination of the REST APIs that were announced in March 2024 to achieve the goal for protecting a virtual machine.
All the execution for the examples were done using Postman API tool without any scripting language to encourage anyone to experiment with the family of REST APIs for data services on HPE GreenLake.
Please don’t hesitate to explore this new set of APIs for Cloud Data Services on HPE GreenLake and see how you can improve your agility in managing your data. Any questions on HPE GreenLake Data Services Cloud Console API? Please join the HPE Developer Community Slack Workspace, and start a discussion in our #hpe-greenlake-data-services Slack channel.
Related
Converting HPE GreenLake API specifications in OAS 3.1 using OpenAPI tools
May 27, 2024
Getting started with HPE GreenLake API for Virtualization
Apr 3, 2024
Getting started with Private Cloud Business Edition APIs
May 13, 2024
Getting started with the HPE Data Services Cloud Console Powershell SDK
Aug 7, 2023
How to monitor HPE GreenLake for Compute Ops Management infrastructure with Grafana Metrics Dashboards
Oct 19, 2022Using the SimpliVity API with Java
Aug 3, 2018