Fast data processing pipeline for predicting flight delays using Apache APIs: Kafka, Spark Streaming and Machine Learning (part 3)
October 11, 2021"authorDisplayName": "Carol McDonald", "tags": "use-cases", "publish": "2018-02-08T12:00:00.000Z"
Editor’s Note: MapR products and solutions sold prior to the acquisition of such assets by Hewlett Packard Enterprise Company in 2019 may have older product names and model numbers that differ from current solutions. For information about current offerings, which are now part of HPE Ezmeral Data Fabric, please visit https://www.hpe.com/us/en/software/data-fabric.html
Editor's Note: This is a 3-part Series, see the previously published posts below:
According to Bob Renner, previous CEO of Liaison Technologies, the possibility to blend machine learning with real-time transactional data flowing through a single platform is opening a world of new possibilities, such as enabling organizations to take advantage of opportunities as they arise. According to Gartner over the next few years, virtually every app, application and service will incorporate some level of machine learning. Leveraging these opportunities requires fast and scalable data processing pipelines.

This is the third in a series of blog posts, that discuss the architecture of a data pipeline that combines streaming data with machine learning and fast storage. The first post discussed creating a machine learning model to predict flight delays. The second post discussed using the saved model with streaming data to do a real-time analysis of flight delays. This third post will discuss fast storage and analysis with MapR Database, Apache Spark, Apache Drill and OJAI.
Machine Learning Logistics and Data Pipelines
Machine Learning usually refers to the model training piece of an ML workflow. But, as data fabric expert Ted Dunning says, 90% of the effort around Machine Learning is data logistics which includes all of the aspects that occur before and after this training. When you combine event streams with microservices, you can greatly enhance the agility with which you build, deploy, and maintain complex data pipelines. Pipelines are constructed by chaining together microservices, each of which listens for the arrival of some data, performs its designated task, and optionally publishes its own messages to another topic. Combining event-driven data pipelines with machine learning can handle the logistics of machine learning in a flexible way by:
- Making input and output data available to independent consumers
- Managing and evaluating multiple models and easily deploying new models
- Monitoring and analyzing models, with historical and real-time data.

Architectures for these types of applications are discussed in more detail in the eBooks: Machine Learning Logistics, Streaming Architecture, and Microservices and Containers.
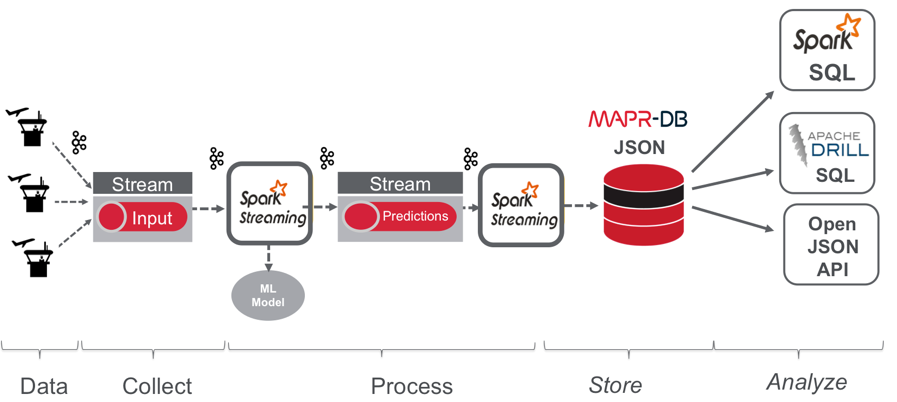
The following figure depicts the (simplified) data pipeline for this tutorial:
- Flight trip data is published to a MapR Event Streams (ES) topic using the Kafka API. (Note this data contains the actual delay label. In the real-world architecture, the actual delay label would come later in a different topic, but to keep the tutorial code simple it is combined with the input data).
- A Spark Streaming application subscribed to the first topic enriches the event with the flight predictions and publishes the results in JSON format to another topic. ( In the real-world architecture, there would be multiple consumers publishing model predictions, but to keep the tutorial code simple there is only one here).
- A Spark Streaming application subscribed to the second topic stores the flight trip data and predictions in MapR Database using the Spark MapR Database Connector.
- Apache Spark SQL, Apache Drill SQL, and Open JSON applications query MapR Database to analyze flight data and prediction performance.
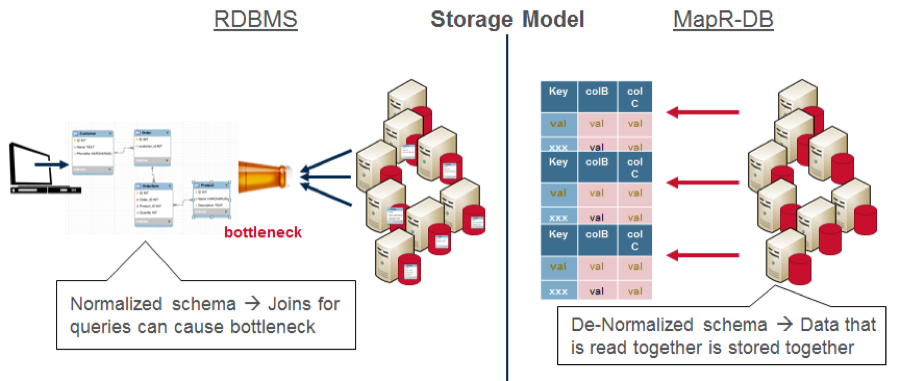
How to Store the Data
One of the challenges, when you are processing lots of streaming data, is where do you want to store it? With a relational database and a normalized schema, related data is stored in different tables. Queries joining this data together can cause bottlenecks with lots of data. For this application, MapR Database JSON, a high-performance NoSQL database, was chosen for its scalability and flexible ease of use with JSON. MapR Database and a denormalized schema scale, because data that is read together is stored together.
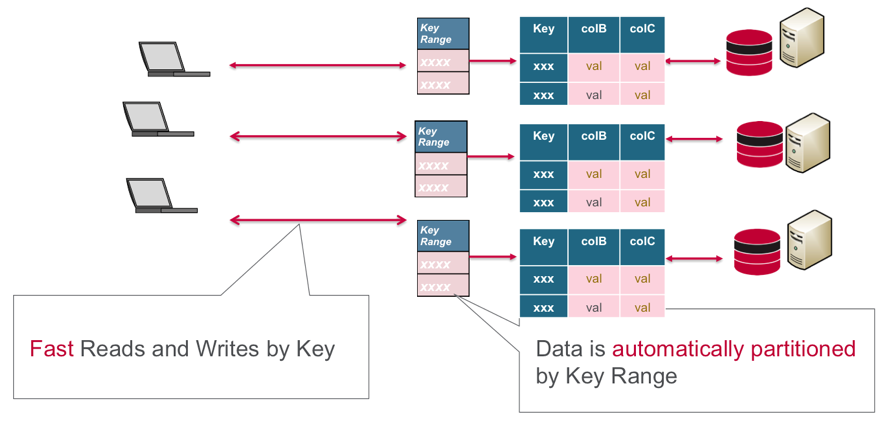
With MapR Database (HBase API or JSON API), a table is automatically partitioned into tablets across a cluster by key range, providing for scalable and fast reads and writes by row key.
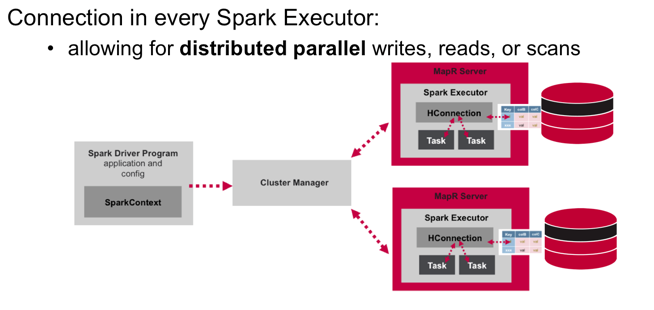
The Spark MapR Database Connector leverages the Spark DataSource API. The connector architecture has a connection object in every Spark Executor, allowing for distributed parallel writes, reads, or scans with MapR Database tablets.
JSON Schema Flexibility
MapR Database supports JSON documents as a native data store. MapR Database makes it easy to store, query and build applications with JSON documents. The Spark connector makes it easy to build real-time or batch pipelines between your JSON data and MapR Database and leverage Spark within the pipeline.
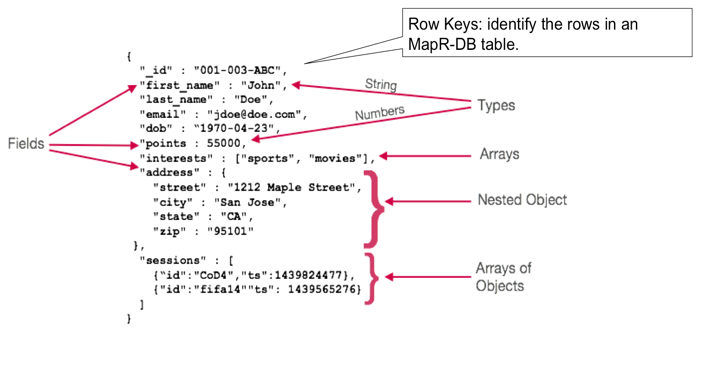
JSON facilitates the natural evolution of your data schema during the life of your application. For example, suppose at first we have the following schema, where each JSON message has the predicted flight delay using a decision tree:
{ "_id": "UA_2017-03-28_DEN_SFO_721", "dofW": 2, "carrier": "UA", "origin": "DEN", "dest": "SFO", "crsdephour": 11, "crsdeptime": 1120.0, "crsarrtime": 1308.0, "crselapsedtime": 168.0, "pred_dtree": 1.0 }
Later, you can easily capture more prediction data values quickly without changing the architecture of your application and without updating a database schema, by adding attributes. In the example below, we have added predictions for other machine learning models. These can be added dynamically to the same document instance in MapR Database without any database schema changes:
{ "_id": "UA_2017-03-28_DEN_SFO_721", "dofW": 2, "carrier": "UA", "origin": "DEN", "dest": "SFO", "crsdephour": 11, "crsdeptime": 1120.0, "crsarrtime": 1308.0, "crselapsedtime": 168.0, "pred_dtree": 1.0, "pred_randforest": 1.0, "pred_svm": 1.0, "actual_delay": 1.0 }
MapR Event Store allows processing of the same messages by different consumers. This makes it easy to add different consumers for the same message. With this type of architecture and flexible schema, you can easily add and deploy new microservices with new machine learning models.
Spark Streaming writing to MapR Database
The MapR Database OJAI Connector for Apache Spark enables you to use MapR Database as a sink for Apache Spark Data Streams.
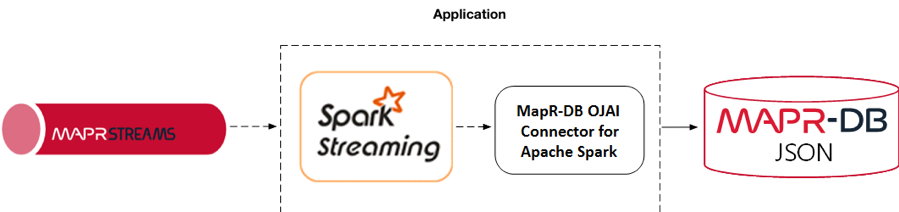
You can read about the MapR Event Streams Spark Streaming code in part 2 of this series; here, we will focus on Spark streaming writing to MapR Database. The messages from the MapR Database topic are in JSON format and contain the following for each flight: the flight id, day of the week, carrier, origin, destination, scheduled departure hour, scheduled departure time, scheduled arrival time, scheduled travel time, delay prediction, and actual delay label (Note in the real-world architecture, the actual delay label would come later in a different topic, but to keep the tutorial code simple, it is combined here). An example is shown below:
{ "_id": "UA_2017-03-28_DEN_SFO_721", "dofW": 2, "carrier": "UA", "origin": "DEN", "dest": "SFO", "crsdephour": 11, "crsdeptime": 1120.0, "crsarrtime": 1308.0, "crselapsedtime": 168.0, "label": 0.0, "pred_dtree": 1.0 }
Below, we use a Scala case class and Structype to define the schema, corresponding to the input data.


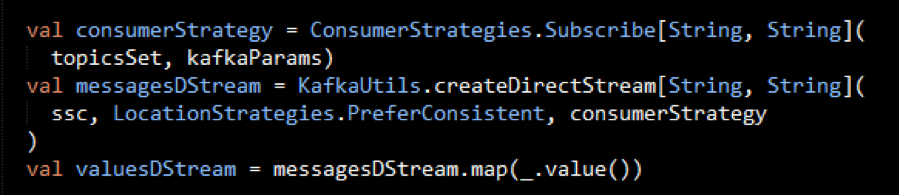
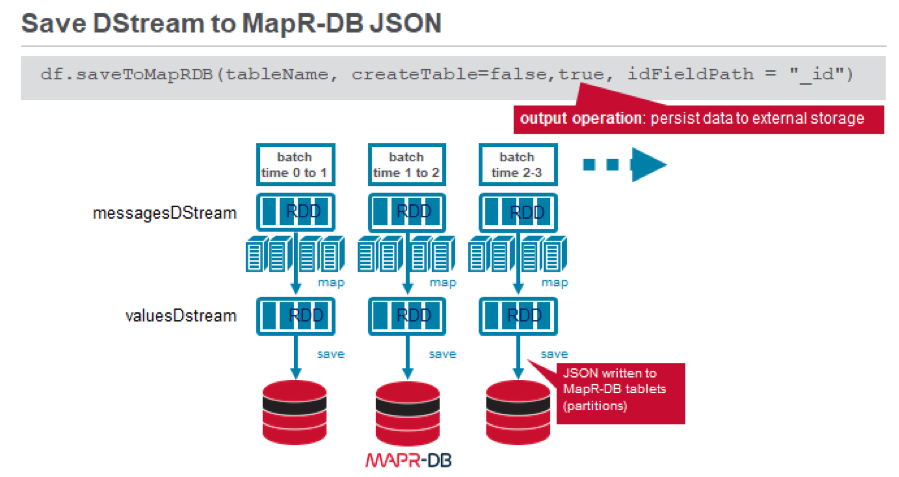
We use the KafkaUtils createDirectStream method with Kafka configuration parameters to create an input stream from a MapR Event Store topic. This creates a DStream that represents the stream of incoming data, where each message is a key value pair. We use the DStream map transformation to create a DStream with the message values.
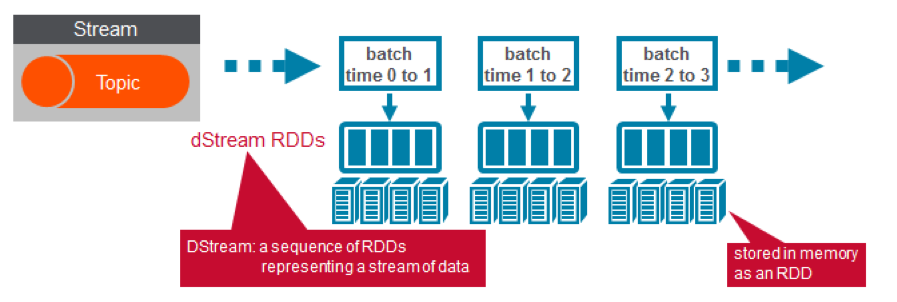
In the code below, each RDD in the valuesDStream is transformed into a Spark Dataset. Then, the MapR Database Spark Connector DStream saveToMapRDB method performs a parallel partitioned bulk insert of JSON FlightwPred objects into MapR Database.

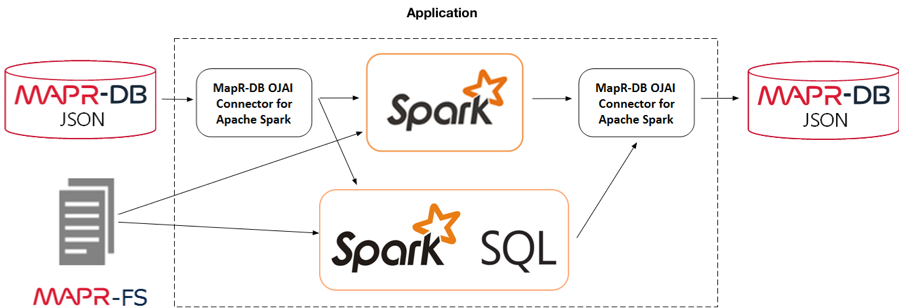
Querying MapR Database JSON with Spark SQL
The Spark MapR Database Connector enables users to perform complex SQL queries and updates on top of MapR Database using a Spark Dataset, while applying critical techniques such as Projection and filter pushdown, custom partitioning, and data locality.
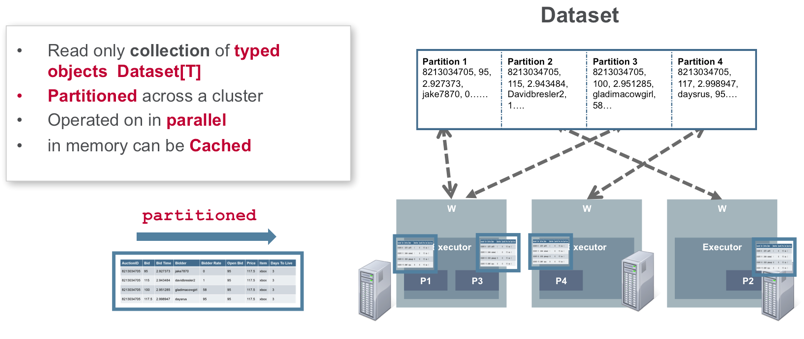
A Spark Dataset is a distributed collection of data. Dataset is a newer interface, which provides the benefits of strong typing, the ability to use powerful lambda functions, efficient object serialization/deserialization, combined with the benefits of Spark SQL's optimized execution engine.
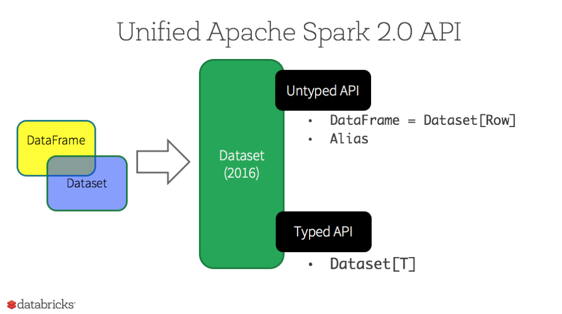
A DataFrame is a Dataset organized into named columns Dataset[Row]. (In Spark 2.0, the DataFrame APIs merged with Datasets APIs.)
Loading data from MapR Database into a Spark Dataset
To load data from a MapR Database JSON table into an Apache Spark Dataset, we invoke the loadFromMapRDB method on a SparkSession object, providing the tableName, schema and case class. This will return a Dataset of FlightwPred objects:

Explore and query the Flight data with Spark SQL
Datasets provide a domain-specific language for structured data manipulation in Scala, Java, and Python. Below are some examples in scala. The Dataset show() action displays the top 20 rows in a tabular form.
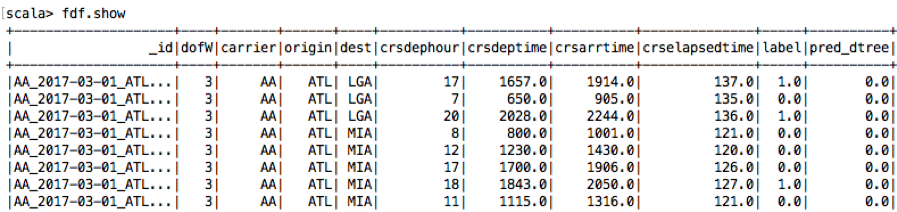
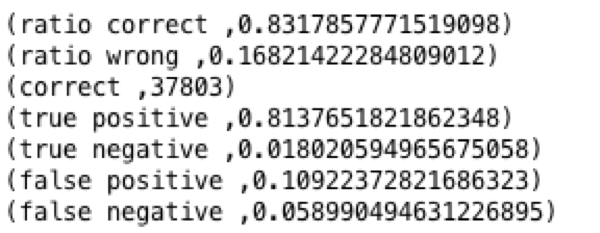
In the code below, a filter is used to count the predicted delays, actual delays and total. This is then used to calculate the ratio wrong, correct, false positive. These type of calculations would be useful for continued analysis of models in production.

The output is shown below.
What is the count of predicted delay/notdelay for this dstream dataset?

You can register a Dataset as a temporary table using a given name, and then run Spark SQL. Here are some example Spark SQL queries on the Dataset of FlightwPred objects:
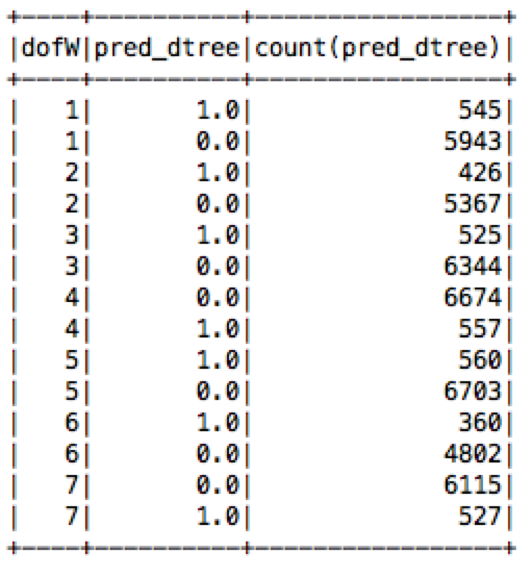
What is the count of predicted delay/notdelay by day of the week?
scala> spark.sql("select dofW, pred_dtree, count(pred_dtree) from flight group by dofW, pred_dtree order by dofW").show
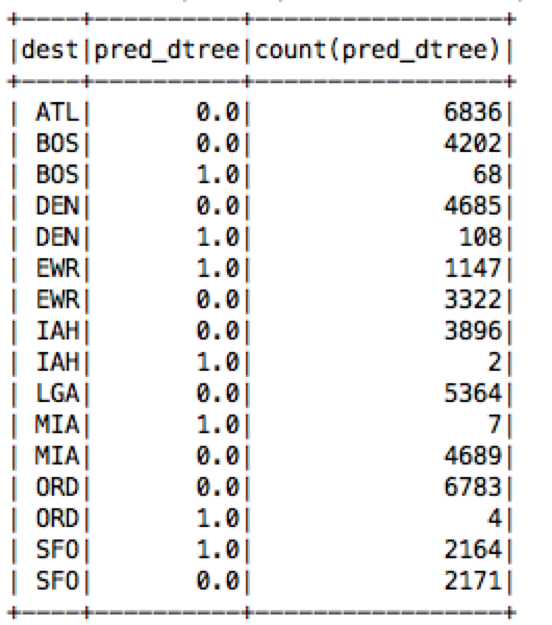
What is the count of predicted delay/notdelay by destination?
scala> spark.sql("select dest, pred_dtree, count(pred_dtree) from flight group by dest, pred_dtree order by dest").show
(The complete code, instructions and more example queries are in the github code link at the end.)
Querying the Data with Apache Drill
Apache Drill is an open source, low-latency query engine for big data that delivers interactive SQL analytics at petabyte scale. Drill provides a massively parallel processing execution engine, built to perform distributed query processing across the various nodes in a cluster.
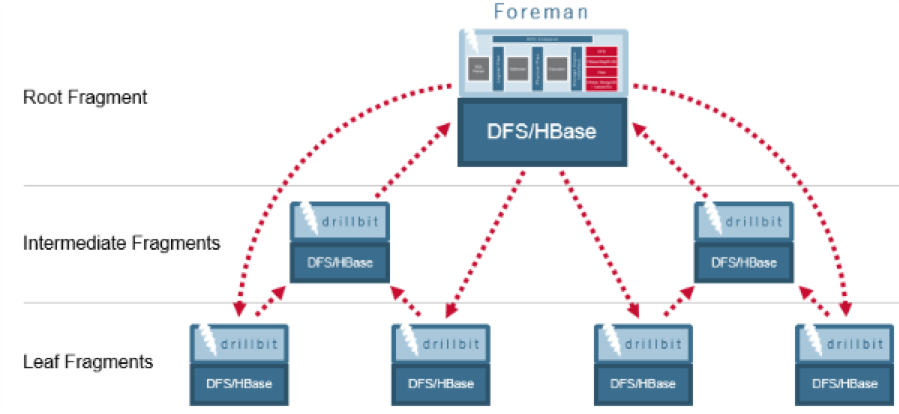
With Drill, you can use SQL to interactively query and join data from files in JSON, Parquet, or CSV format, Hive, and NoSQL stores, including HBase, MapR Database, and Mongo, without defining schemas. MapR provides a Drill JDBC driver that you can use to connect Java applications, BI tools, such as SquirreL and Spotfire, to Drill. Below is a snippit of Java code for querying MapR Database using Drill and JDBC:
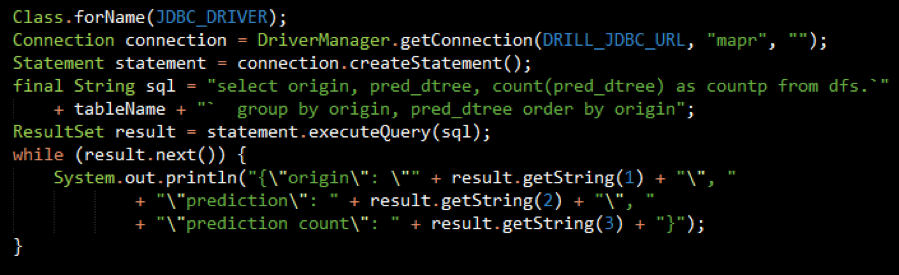
The output for this query "What is the count of predicted delay/notdelay by origin?" is shown below:
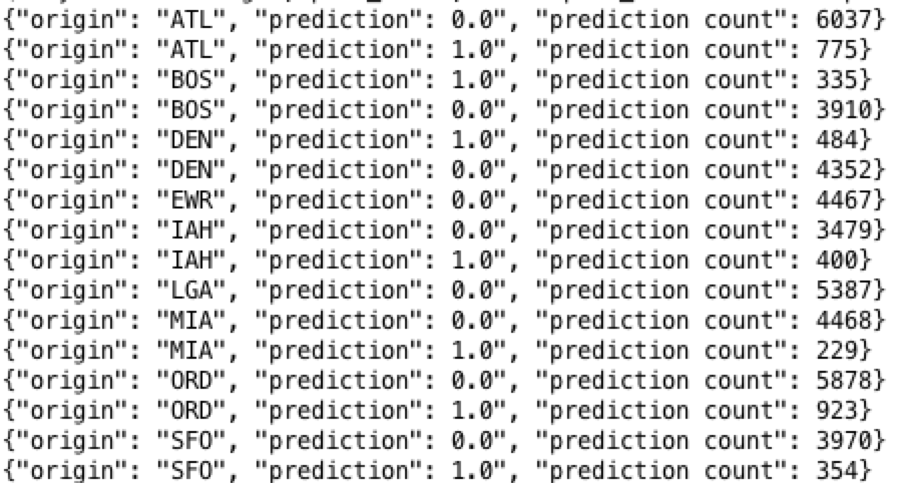
Below are some example SQL queries using the Drill shell.
What is the count of predicted delay/notdelay by origin
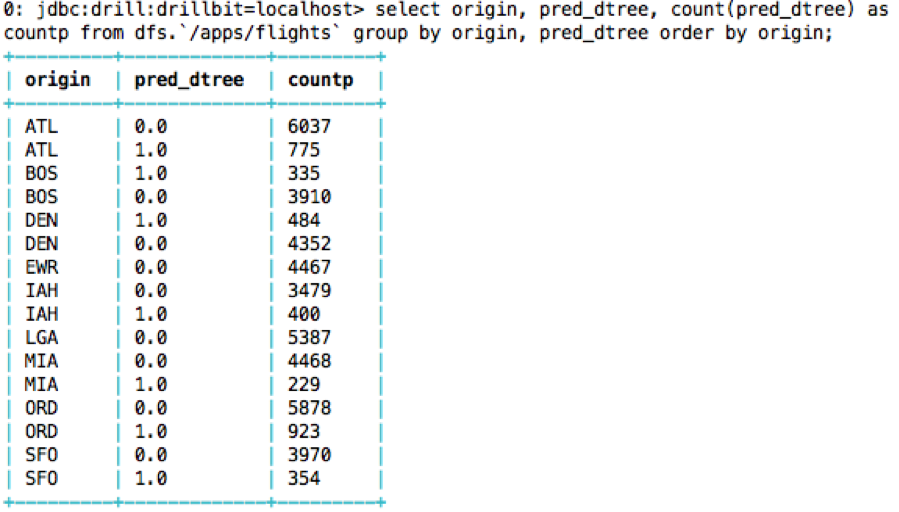
What is the count of predicted delay/notdelay by origin and dest?
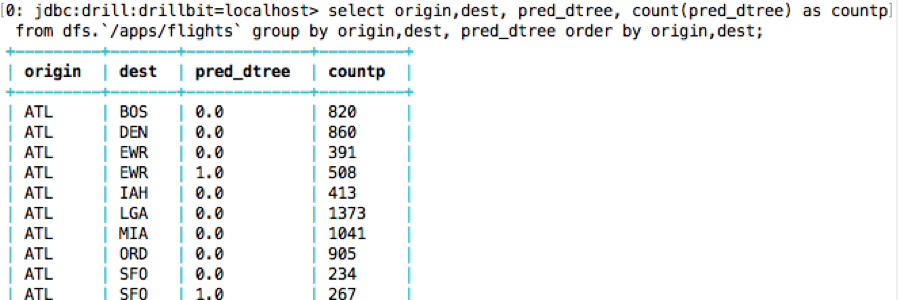
Follow the instructions in the github code README to add a secondary index to MapR Database and try more queries using the index.
Querying with the Open JSON API (OJAI)
Below is a Java example of using the OJAI Query interface to query documents in a MapR Database JSON table:
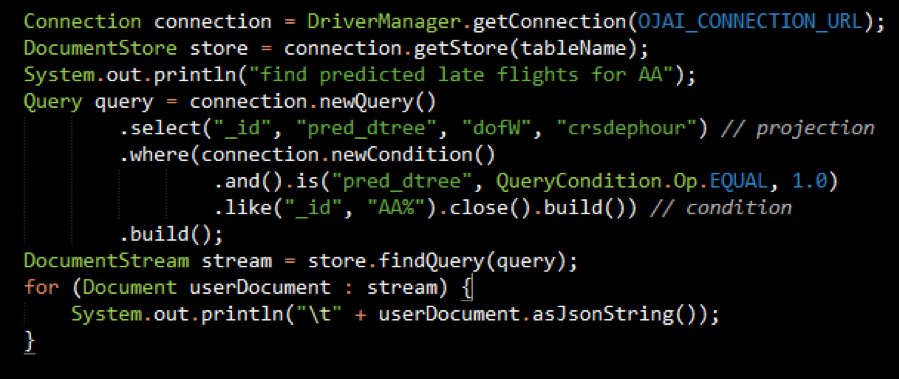
Partial output for this query to "find predicted late flights for AA" is shown below:
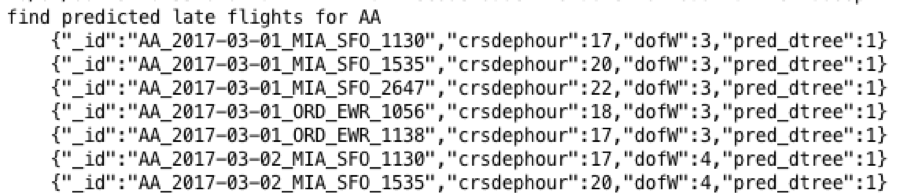
Below are some example OJAI queries using the MapR Database shell.
What are the SFO to DEN flights that were predicted late ?
maprdb> find /apps/flights -where '{"$and":[{"$eq":{"pred_dtree":1.0}},{ "$like" : {"_id":"%SFO_DEN%"} }]}' --f _id,pred_dtree
Summary
In this blog post, you've learned how to consume streaming JSON events, store in a document database, and explore with SQL using Apache Spark, Apache Kafka API, Apache Drill, MapR Event Store, MapR Database, and OJAI.
Code
You can download the code and data to run these examples from here (refer to the README for complete instructions to run): https://github.com/mapr-demos/mapr-es-db-60-spark-flight
Running the Code
All of the components of the use case architecture we just discussed can run on the same cluster with the MapR Data Platform. The MapR Data Platform integrates global event streaming, real-time database capabilities, and scalable enterprise storage with a collection of data processing and analytical engines to power data processing pipelines and intelligent applications.
This example was developed using the MapR 6.0 container for developers, a docker container that enables you to create a single node MapR cluster. The container is lightweight and designed to run on your laptop. (refer to the code README for instructions on running the code).
You can also look at the following examples:
- MapR Database 60-getting-started to discover how to use DB Shell, Drill and OJAI to query and update documents, but also how to use indexes.
- MapR Event Store getting started on MapR 6.0 developer container
- Ojai 2.0 Examples to learn more about OJAI 2.0 features
- MapR Database Change Data Capture to capture database events such as insert, update, delete and react to these events.
WANT TO LEARN MORE?
- Free On-Demand Training
- MapR Database Rowkey Design
- MapR Database OJAI Connector for Apache Spark
- MapR Database shell
- Integrate Spark with MapR Event Store Documentation
- Apache Drill Tutorial
- MapR Database secondary indexes
- MapR Container for Developers
- Apache Spark Streaming programming guide
- Spark SQL programming Guide
Related
3 ways a data fabric enables a data-first approach
Mar 15, 2022A Functional Approach to Logging in Apache Spark
Feb 5, 2021
Getting Started with DataTaps in Kubernetes Pods
Jul 6, 2021