Fast data processing pipeline for predicting flight delays using Apache APIs: Kafka, Spark Streaming and Machine Learning (part 2)
October 11, 2021"authorDisplayName": "Carol McDonald", "tags": "use-cases", "publish": "2018-01-10T10:00:00.000Z"
Editor’s Note: MapR products and solutions sold prior to the acquisition of such assets by Hewlett Packard Enterprise Company in 2019 may have older product names and model numbers that differ from current solutions. For information about current offerings, which are now part of HPE Ezmeral Data Fabric, please visit https://www.hpe.com/us/en/software/data-fabric.html
Editor's Note: You can find Part 1 of this series here
According to Bob Renner, former CEO of Liaison Technologies, the possibility to blend machine learning with real-time transactional data flowing through a single platform is opening a world of new possibilities, such as enabling organizations to take advantage of opportunities as they arise. Leveraging these opportunities requires fast, scalable data processing pipelines that process, analyze, and store events as they arrive.
This is the second in a series of blog posts that discusses the architecture of a data pipeline that combines streaming data with machine learning and fast storage. The first post discussed creating a machine learning model to predict flight delays. This second post will discuss using the saved model with streaming data to do a real-time analysis of flight delays. The third post will discuss fast storage with MapR Database.
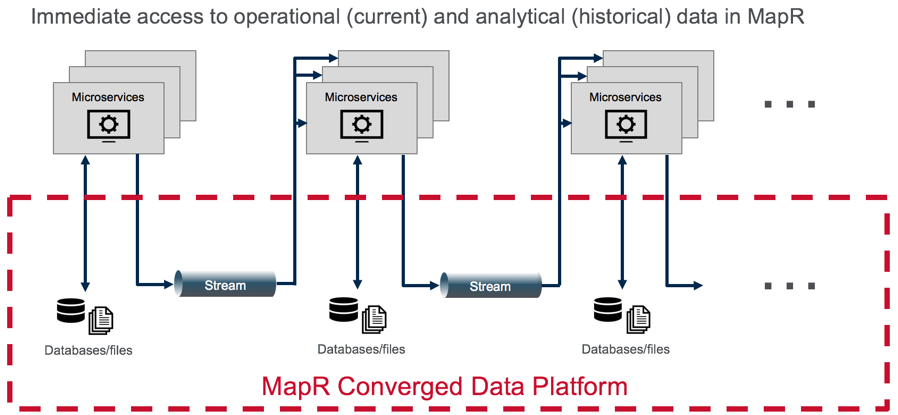
Microservices, Data Pipelines, and Machine Learning Logistics
The microservice architectural style is an approach to developing an application as a suite of small independently deployable services. A common architecture pattern combined with microservices is event sourcing using an append-only publish-subscribe event stream such as MapR Event Streams (which provides a Kafka API).
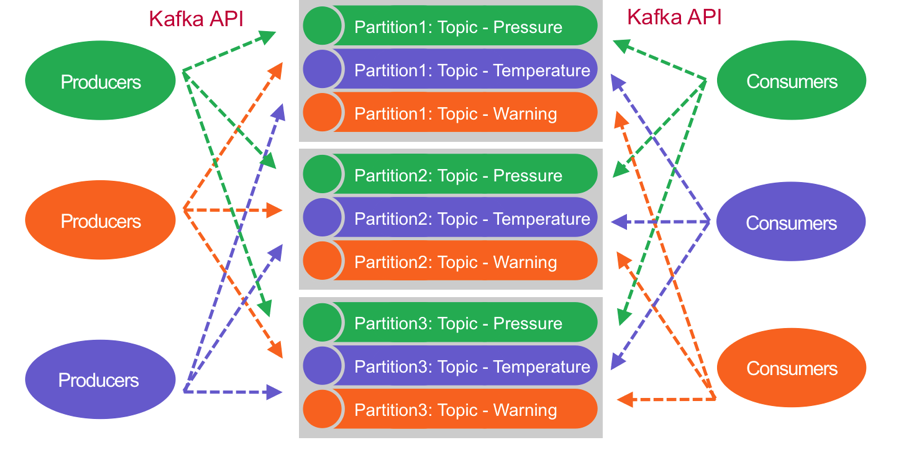
Publish Subscribe Event Streams with MapR Event Store
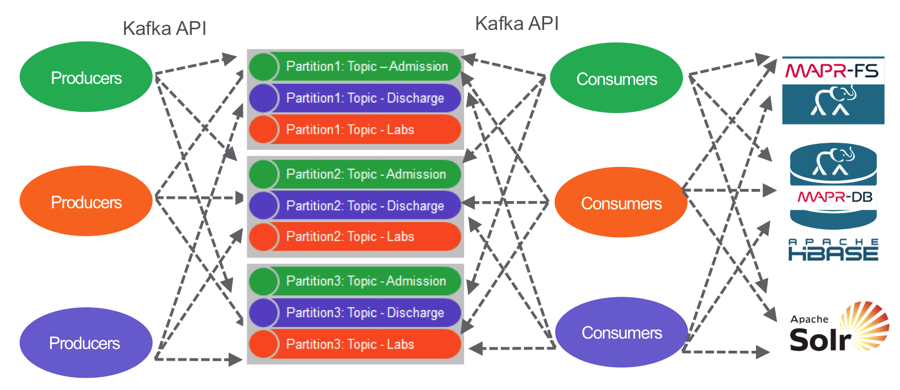
A central principle of publish/subscribe systems is decoupled communications, wherein producers don’t know who subscribes, and consumers don’t know who publishes; this system makes it easy to add new listeners or new publishers without disrupting existing processes. MapR Event Store allows any number of information producers (potentially millions of them) to publish information to a specified topic. MapR Event Store will reliably persist those messages and make them accessible to any number of subscribers (again, potentially millions). Topics are partitioned for throughput and scalability, producers are load balanced, and consumers can be grouped to read in parallel. MapR Event Store can scale to very high throughput levels, easily delivering millions of messages per second using very modest hardware.
You can think of a partition like a queue; new messages are appended to the end, and messages are delivered in the order they are received.
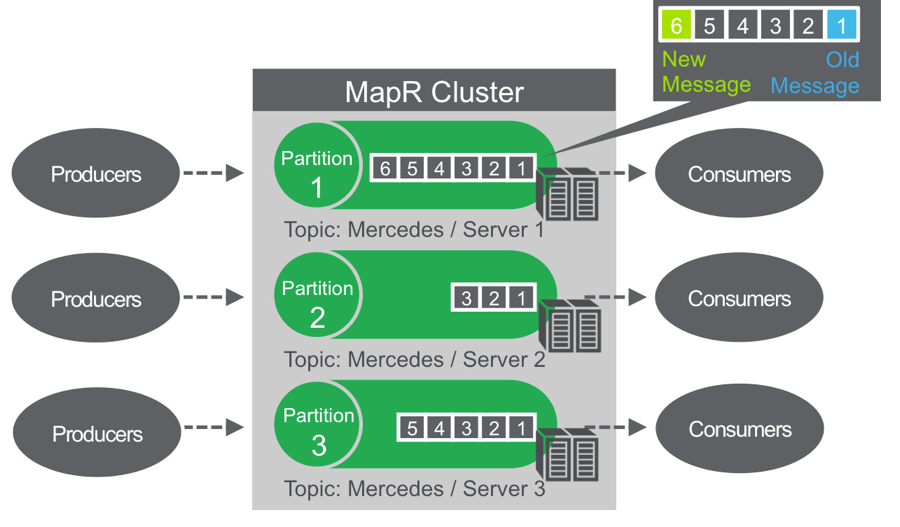
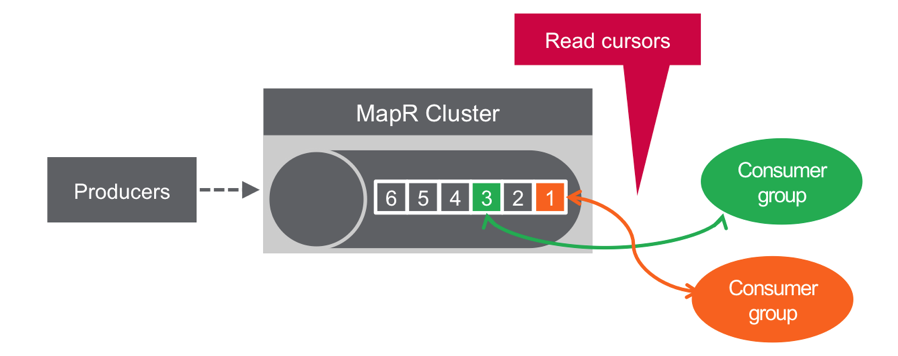
Unlike a queue, messages are not deleted when read; they remain on the partition, available to other consumers. Messages, once published, are immutable, and can be retained forever.
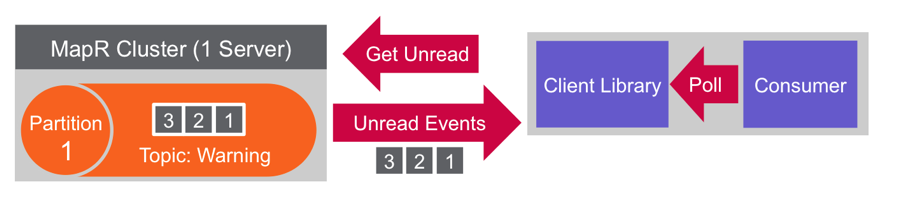
Not deleting messages when they are read allows for high performance at scale and also for processing of the same messages by different consumers for different purposes such as multiple views with polyglot persistence.
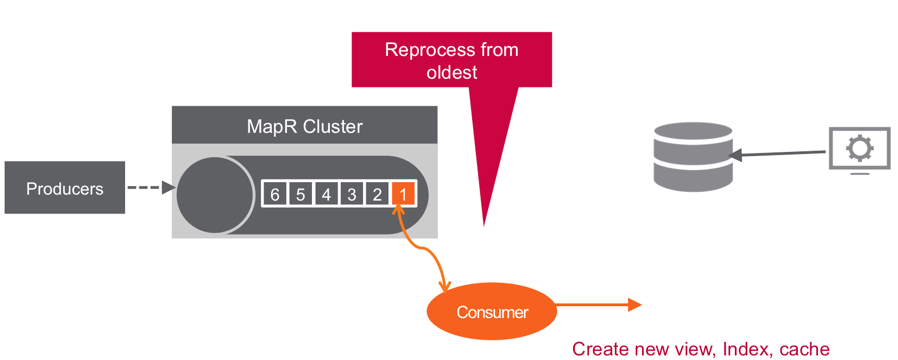
New subscribers of information can replay the data stream, specifying a starting point as far back as the data retention policy enables.
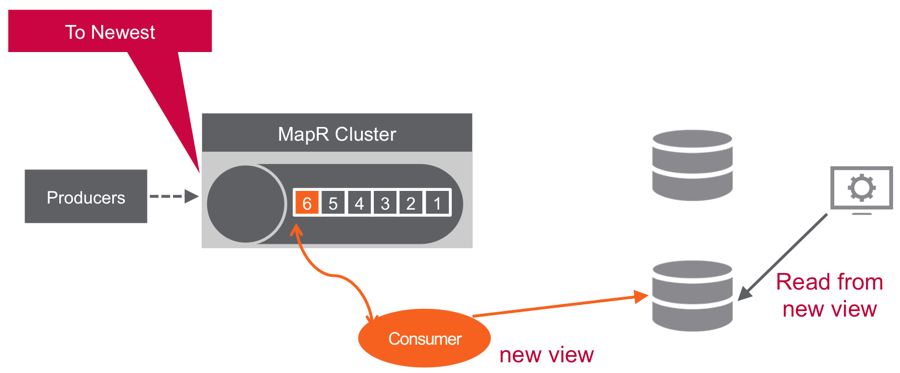
Data Pipelines
When you combine these messaging capabilities with the simple concept of microservices, you can greatly enhance the agility with which you build, deploy, and maintain complex data pipelines. Pipelines are constructed by simply chaining together multiple microservices, each of which listens for the arrival of some data, performs its designated task, and optionally publishes its own messages to a topic. Development teams can deploy new services or service upgrades more frequently and with less risk, because the production version does not need to be taken offline. Both versions of the service simply run in parallel, consuming new data as it arrives and producing multiple versions of output. Both output streams can be monitored over time; the older version can be decommissioned when it ceases to be useful.
Machine Learning Logistics and Data Pipelines
Combining data pipelines with machine learning can handle the logistics of machine learning in a flexible way by:
- Making input and output data available to independent consumers
- Managing and evaluating multiple models and easily deploying new models
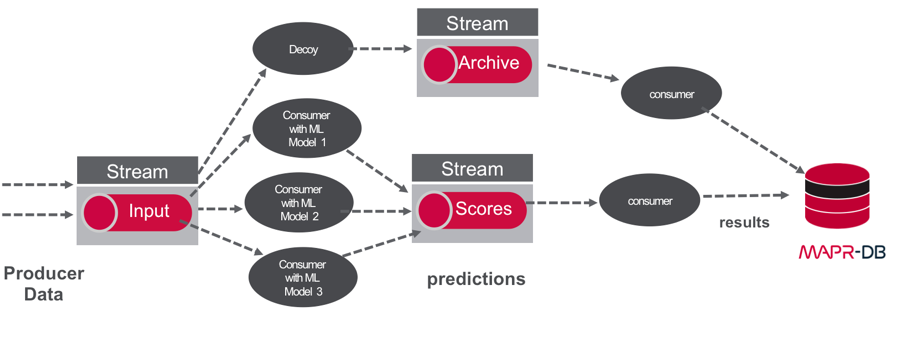
Architectures for these types of applications are discussed in more detail in the ebooks Machine Learning logistics, Streaming Architecture, and Microservices and Containers.
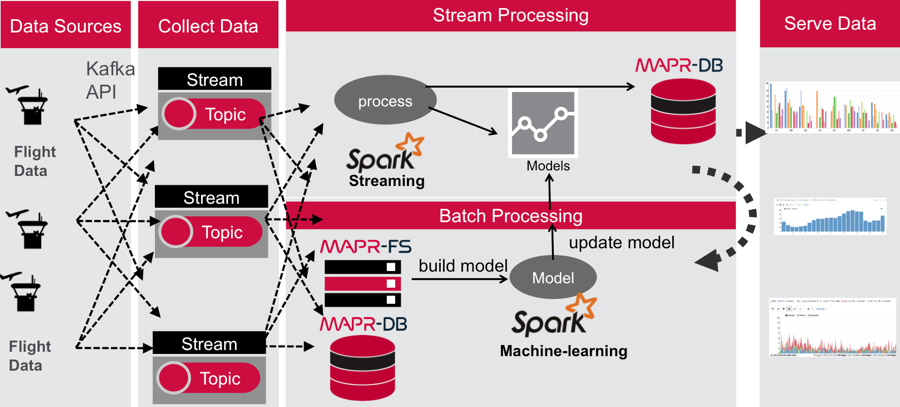
Below is the data processing pipeline for this use case of predicting flight delays. This pipeline could be augmented to be part of the rendezvous architecture discussed in the Oreilly Machine Learning Logistics ebook.
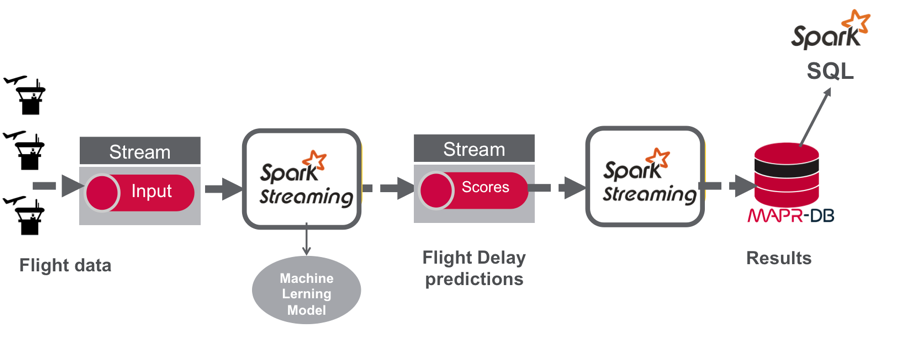
Spark Streaming Use Case Example Code
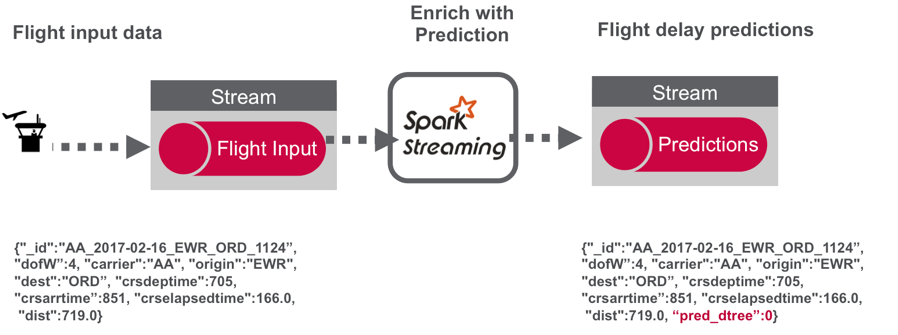
The following figure depicts the architecture for the part of the use case data pipeline discussed in this post:
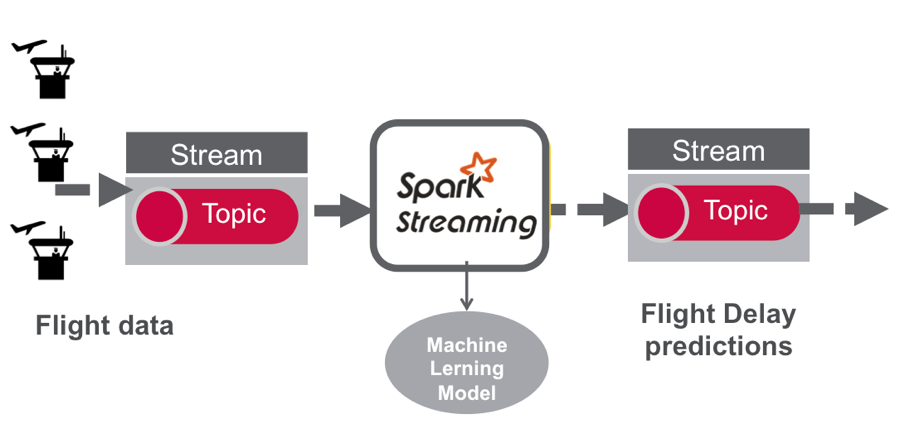
- Flight data is published to a MapR Event Store topic using the Kafka API.
- A Spark streaming application, subscribed to the first topic: Ingests a stream of flight data
- Uses a deployed machine learning model to enrich the flight data with a delayed/not delayed prediction
- publishes the results in JSON format to another topic.
- (In the 3rd blog) A Spark streaming application subscribed to the second topic: Stores the input data and predictions in MapR Database
Example Use Case Data
You can read more about the data set in part 1 of this series. The incoming and outgoing data is in JSON format, an example is shown below:
{"_id":"AA_2017-02-16_EWR_ORD_1124”, "dofW”:4, "carrier":"AA", "origin":"EWR", "dest":"ORD”, "crsdeptime":705, "crsarrtime”:851, "crselapsedtime":166.0,"dist":719.0}
Spark Kafka Consumer Producer Code
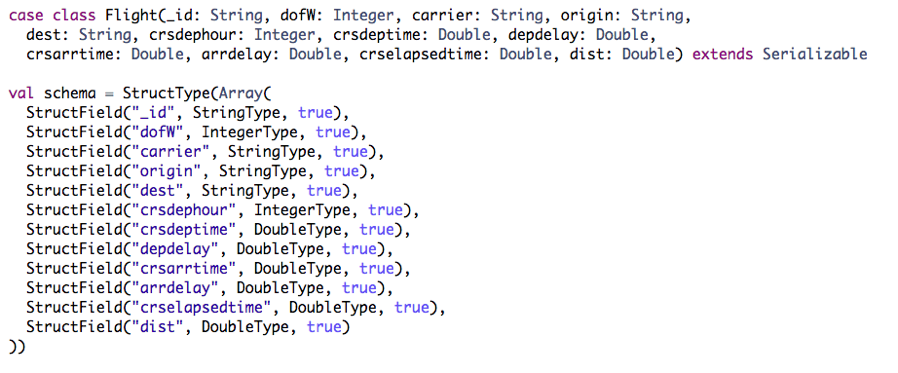
Parsing the Data Set Records
We use a Scala case class and Structype to define the schema, corresponding to the input data.
Loading the Model
The Spark CrossValidatorModel class is used to load the saved model fitted on the historical flight data.

Spark Streaming Code
These are the basic steps for the Spark Streaming Consumer Producer code:
- Configure Kafka Consumer and Producer properties.
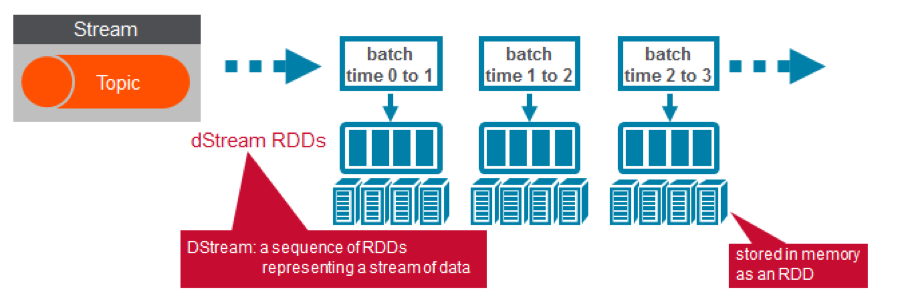
- Initialize a Spark StreamingContext object. Using this context, create a DStream that reads a message from a Topic.
- Apply transformations (which create new DStreams).
- Write messages from the transformed DStream to a Topic.
- Start receiving data and processing. Wait for the processing to be stopped.
We will go through each of these steps with the example application code.
1) Configure Kafka Consumer Producer properties
The first step is to set the KafkaConsumer and KafkaProducer configuration properties, which will be used later to create a DStream for receiving/sending messages to topics. You need to set the following parameters:
- Key and value deserializers: for deserializing the message.
- Auto offset reset: to start reading from the earliest or latest message.
- Bootstrap servers: this can be set to a dummy host:port since the broker address is not actually used by MapR Event Store.
For more information on the configuration parameters, see the MapR Event Store documentation.

2) Initialize a Spark StreamingContext object.
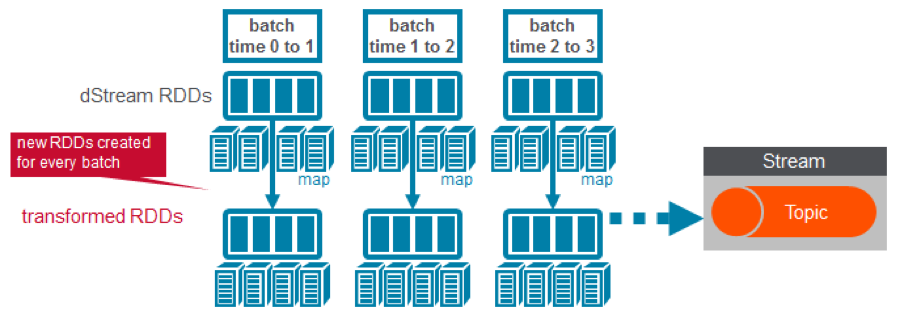
ConsumerStrategies.Subscribe, as shown below, is used to set the topics and Kafka configuration parameters. We use the KafkaUtils createDirectStream method with a StreamingContext, the consumer and location strategies, to create an input stream from a MapR Event Store topic. This creates a DStream that represents the stream of incoming data, where each message is a key value pair. We use the DStream map transformation to create a DStream with the message values.

3) Apply transformations (which create new DStreams)
We use the DStream foreachRDD method to apply processing to each RDD in this DStream. We read the RDD of JSON strings into a Flight Dataset. Then we display 20 rows with the Dataset show method. We also create a temporary view of the Dataset in order to execute SQL queries.

Here is example output from the df.show :

We transform the Dataset with the model pipeline, which will transform the features according to the pipeline, estimate and then return the predictions in a column of a new Dateset. We also create a temporary view of the new Dataset in order to execute SQL queries.

4) Write messages from the transformed DStream to a Topic
The Dataset result of the query is converted to JSON RDD Strings, then the RDD sendToKafka method is used to send the JSON key-value messages to a topic (the key is null in this case).
Example message values (the output for temp.take(2) ) are shown below:
{"_id":"DL_2017-01-01_MIA_LGA_1489","dofW":7,"carrier":"DL","origin":"MIA","dest":"LGA","crsdephour":13,"crsdeptime":1315.0,"crsarrtime":1618.0,"crselapsedtime":183.0,"label":0.0,"pred_dtree":0.0} {"_id":"DL_2017-01-01_LGA_MIA_1622","dofW":7,"carrier":"DL","origin":"LGA","dest":"MIA","crsdephour":8,"crsdeptime":800.0,"crsarrtime":1115.0,"crselapsedtime":195.0,"label":0.0,"pred_dtree":0.0}
5) Start receiving data and processing it. Wait for the processing to be stopped.
To start receiving data, we must explicitly call start() on the StreamingContext, then call awaitTermination to wait for the streaming computation to finish. We use ssc.remember to cache data for queries.

Streaming Data Exploration
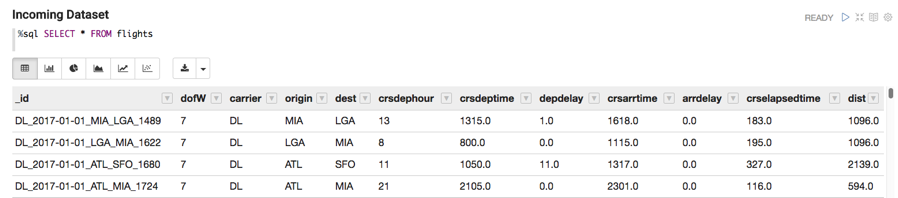
Now we can query the cached streaming data in the input temporary view flights, and the predictions temporary view flightsp. Below we display a few rows from the flights view:
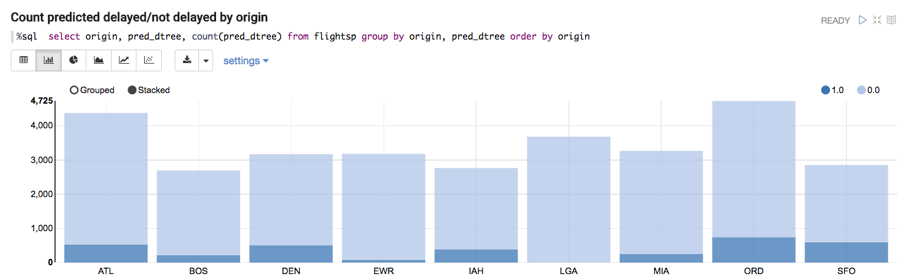
Below we display the count of predicted delayed/not delayed departures by Origin:
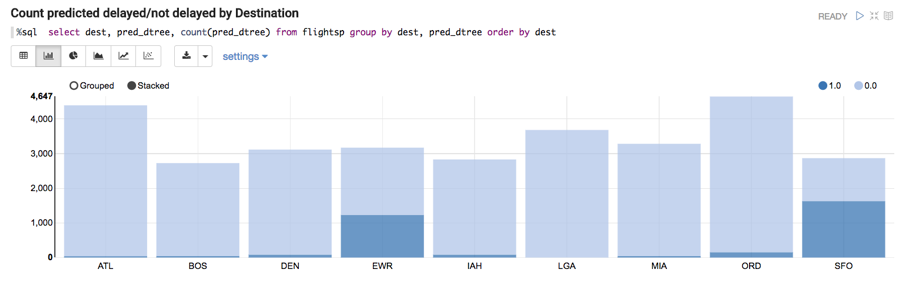
Below we display the count of predicted delayed/not delayed departures by Destination:
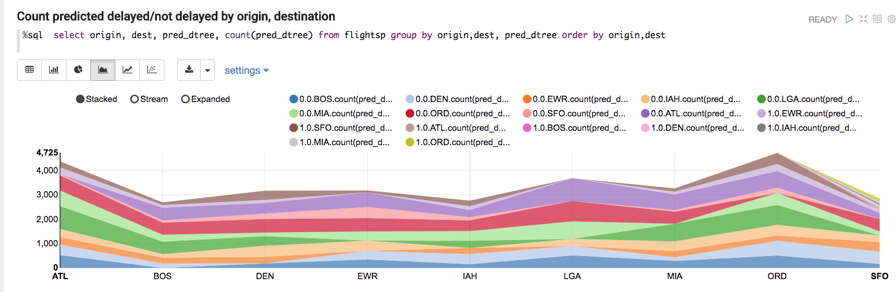
Below we display the count of predicted delayed/not delayed departures by Origin,Destination:
Summary
In this blog post, you learned how to use a Spark machine learning model in a Spark Streaming application, and how to integrate Spark Streaming with MapR Event Streams to consume and produce messages using the Kafka API.
Code
- You can download the code and data to run these examples from here
- Zeppelin Notebook for the code
Running the Code
All of the components of the use case architecture we just discussed can run on the same cluster with the MapR Data Platform.
Related
3 ways a data fabric enables a data-first approach
Mar 15, 2022A Functional Approach to Logging in Apache Spark
Feb 5, 2021
Getting Started with DataTaps in Kubernetes Pods
Jul 6, 2021