
Everybody’s getting into AI. The visceral experience of using ChatGPT in professional or personal lives can raise a lot of concern. Concerns about the future of work, creativity... even civilization's lifespan.
One big concern that often comes up is about control. How can an organization or individual maintain a certain amount of control over their experience when using AI?
Not everyone cares about this. But for those who do, it’s critical.
I think there are three major reasons why organizations want control over their AI-powered applications, and I’ll discuss them in this post: Data, Model Performance, and Cost.
The only way to address these concerns is to run a model in a private, protected environment - one in which you have full control.
1. Data
Having control over your data means what you think it does; that you don't let anyone else see it.
Privacy and security guarantees
When you run your own large language model (LLM) endpoint, all data is processed locally, on your network. This allows you to minimize the risk of exposure in two ways: when the data is in transit, and when the data is stored in the LLM endpoint’s logs.
When you depend on a service that is hosted externally to your organization, there is always a form of counterparty risk. Public services can fall victim to scalability issues, power outages, ransomware attacks, or other Force Majeure. Also, counterparties can choose to update or change models without telling you. And you can't forget the cost of API calls.
Processing data locally or in controlled environments minimizes these risks. Not because you’re any better at cybersecurity or running a datacenter than these counterparties… just because you’re already exposed to issues on your side. Why increase the surface area? Why trust someone with your tokens if you don’t have to?
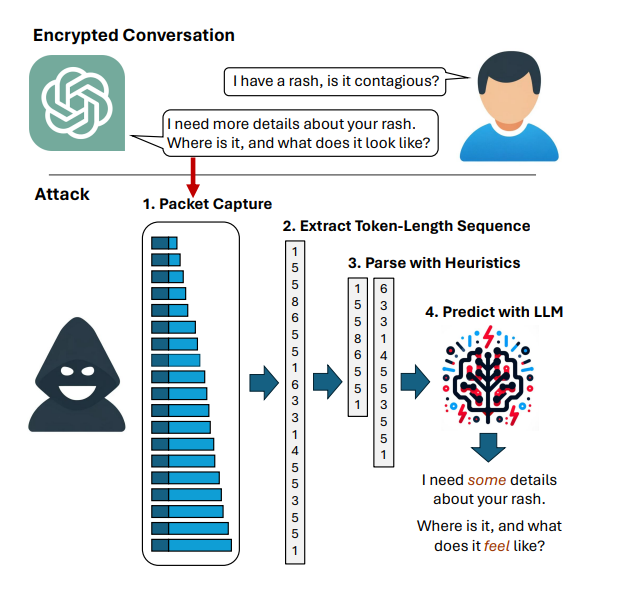
In addition, if you are using a public LLM endpoint that provides a streaming response, even encrypted data in transmit makes it possible to recover the plain text from the encrypted network traffic. More detail is available in this paper, which I hope public endpoint providers have seen and addressed.
Compliance with regulations
Beyond reputational risk, regulations like HIPAA and PCI force counterparties in healthcare and finance to store data for years, while the EU’s GDPR and India’s DPDPA force PII to be stored within their jurisdiction (at least, that’s how companies are interpreting the laws). Ensuring compliance with these regulations is important, but it’s also important in conjunction with the security risks described earlier. Why rely on a third-party who is forced to store every prompt and response for six years?
IP and copyright protection
The final example of losing control of your data is when some engineer goes and uploads a document describing trade secrets, debugs some code with a proprietary algorithm inside, or signs a waiver to download a confidential document, forgets about the waiver, and then uploads it to get a quick summary. Looking at you Samsung…
2. Model Performance
I referred to this in a previous blog: there are two ways to measure model performance: the speed of the output, and the quality of the output.
Improving Model Speed
Primarily, there are two key metrics that impact user experience: latency and throughput. Latency is generally considered to be “time to first token” or TTFT. This is constrained by how fast the model can process the input (i.e. the prompt) measured in tokens-per-second (tok/sec). Throughput is generally considered to be “time per output token” or TPOT. Throughput can also be measured by inter-token latency and generally, it is represented in tokens-per-second (tok/sec).
Note: Tokens are the basic units of input and output in a large language model. Tokens typically represent words, sub-words, or characters. They are the smallest units of meaning in a text that can be processed by a large language model.
When considering a minimum tok/sec of performance for language models, most people jump to a comparison that includes reading speed. The reasoning goes something like: proficient readers are around 300 words per minute. Considering the vocabulary size of current LLM tokenizers to be 1.5 tokens per word, that is 450 tokens per minute, or 7.5 tokens per second.
However, a few comments:
- 5 tok/sec feels slow to me. 10 tok/sec feels good. 20+ tok/sec feels fast.
- Many LLM’s are used for things beyond just chatting back and forth, where the user doesn’t read every line that was generated line by line. For example, when I am editing a blog or generating an image, I am just waiting for the LLM to finish generating before I ctrl+C, ctrl+V. Or, when generating, refactoring, and adding comments to code, I am going to immediately insert it and move on.
- Many “online” or “interactive” LLM-powered applications contain multiple prompts and responses. For example, RAG involves an embedding model and a chat model. Text-to-SQL involves a prompt/response to generate the query, running the query, and an optional prompt/response for synthesis of the response. Tool use, agentic workflows, reflection, and chain-of-thought prompting is all growing in popularity. These approaches require multiple prompt/response turns before. Anything that involves audio (text-to-speech or speech-to-text) has a minimum speed requirement (people can speak English at around 150 words per minute, about half as fast as they read).
- Many “offline” or “batch” use cases also exist (i.e. summarize, classify, translate or transcribe 1000 files)
In just about every one of these cases, faster is better (or cheaper). Having full control over the hardware that your model runs on is really the only way to improve this.
Improving Model Quality
Three ways to improve model quality is via prompt-tuning (or p-tuning), retrieval augmented-generation (RAG), or fine-tuning the model (i.e. changing some of the weights).
In all of these cases, it is clear that the developer of the LLM-powered application would like to control things like the system prompt (kind of available via ChatGPT or Claude), the weights of the model (not really available for public endpoints), and most importantly, use private data during RAG.
As discussed earlier, the quality of your AI-powered application depends on the quality of your data. If you want to integrate private datasets without taking on risk, you have to host the endpoint(s) for yourself.
3. Cost
The biggest thing that bothers me about using public APIs, is paying per token. It seems like cloud has gone too far. First, it was CPU cycles by the hour. Then, it was functions as-a-Service. Now, if the model is too chatty, I’m getting hit with a bill.
This isn’t fantasy: many use cases for large context windows are popping up. The first Harry Potter book costs around 100k tokens, and so do a lot of my product spec sheets and user guides. Anthropic prices Claude 3.5 Sonnet at $3/M tokens. OpenAI charges $5/M tokens for GPT-4o. Google offers Gemini 1.5 Pro for $1.25/M tokens.
So, (over simplifying and avoiding the pricing improvements of context caching), if I have 10 questions about the first Harry Potter book, it’s going to cost me between $1 and $5. And, I have a few more questions than that.
Conclusion: The world will be hybrid
It seems to me that Private AI will experience a similar evolution as found with Private Cloud. Public experiences will win hearts, minds, and popular culture. However, many companies will feel the need to try and get the same experience in private due to specific requirements for data privacy, model performance, and cost. The result will be a mix of both, resulting in a hybrid AI experience.
Hunter and I discussed this in Episode 3 of Things We Read This Week. You can watch it here on YouTube.
Related
Artificial Intelligence and Machine Learning: What Are They and Why Are They Important?
Nov 12, 2020Bringing AI assistants to GreenLake with MCP Servers
Dec 3, 2025Closing the gap between High-Performance Computing (HPC) and artificial intelligence (AI)
Sep 15, 2023Demystifying AI, Machine Learning and Deep Learning
Nov 25, 2020Deploying a Small Language Model in HPE Private Cloud AI using a Jupyter Notebook
Feb 20, 2025Distributed Tuning in Chapel with a Hyperparameter Optimization Example
Oct 9, 2024End-to-End Machine Learning Using Containerization
Feb 5, 2021