Editor’s Note: MapR products and solutions sold prior to the acquisition of such assets by Hewlett Packard Enterprise Company in 2019 may have older product names and model numbers that differ from current solutions. For information about current offerings, which are now part of HPE Ezmeral Data Fabric, please visit https://www.hpe.com/us/en/software/data-fabric.html
Original Post Information:
"authorDisplayName": "John Omernik", "publish": "2018-06-07T13:00:00.000", "category": "use-case",
Since starting at MapR, I’ve been focusing on a number of things, including learning more about MapR, meeting coworkers and customers, and a topic near and dear to my heart: immersing myself in containers and their integration with the MapR Data Platform. In past jobs, I’ve used MapR with containers but have not dug into the Persistent Application Client Container (PACC) nearly as much as I should. This cautionary tale is one to remind everyone how amazing containers are AND how to keep the benefits of containers at the top of your mind when working to create them, so you don’t design your containers in such a way that you give up those benefits and end up writing a mea culpa blog post like this one.

I was tasked to come up with a way to have a syslog server receive log messages and produce those messages to MapR Event Store – a powerful setup for Information Security and IT Operations professions. I had a few requirements:
- Must run in Docker. This is now a self-imposed philosophy for all things. I want everything to be portable, sharable, and usable by everyone on the MapR Data Platform.
- Simple in and out. It has to listen on a syslog port (TCP and UDP) and produce to MapR Event Store. I wanted to show how it works in the Dockerfile, but I didn’t want to chain multiple containers together.
After some research I decided to utilize a great MapR partner, StreamSets, and their StreamSets Data Collector (SDC) as the core. The SDC’s interface, capabilities, and integrations with MapR would serve me well here. I had worked with StreamSets before in Docker with MapR; however, I had NOT used the MapR PACC, so it would be a learning experience. I pulled out my old Dockerfiles, modified some components, ensured I was handling my newly secured cluster with tickets, and it worked great! I even produced a script to create the MapR Event Store and generate test messages, all contained in one handy GitHub repository.
As you can see by the title of this post, I did it wrong. Now, most folks would just update their code once they realized their mistake; however, I created a second repository because I wanted to share what I did wrong as an example to others. What did I do wrong? I did not create a deterministic container (https://en.wikipedia.org/wiki/Deterministic_system).
One of the primary benefits of Docker should be that, if I create a Docker container, I will be able run it on all my systems, and if I hand that container to someone else, it should run the same way, thereby being a deterministic system. Now, let me say there are always caveats, but this should be a primary goal for Docker users.
Where did I go wrong? Well, my main issue was using my old code from before the MapR PACC. In this code, I took a number of directories for StreamSets, including logs, conf (config), and others, and placed it on the local system. When I ran this on a MapR node in my cluster, it worked great, because all the users that I would use inside the container were also on my MapR nodes running Docker. Thus, I could set up permissions on those local directories, and when the container ran, the user inside the container had proper filesystem permissions to the directories required by StreamSets.

However, when I shared my repository with a colleague at MapR, they reported it didn’t work on their system. I was baffled: it should work; it’s Docker! That’s the whole point of using containers. Well, my colleague was not running the container on MapR nodes; instead, it was running on a client machine. This client machine did NOT have the same users as the MapR cluster. Thus there were a number of issues that my scripts ran into with creating the configuration directories, settings permissions, and even running StreamSets. I made assumptions in my original Docker, and by doing so, made a container that ran differently depending on the execution system.
This was an eye-opener for me. From one perspective, I had tried to get StreamSets running in the PACC by using old knowledge and approaches in an effort to expedite the process. By doing so, I hampered the usability, portability, and shareability of my container. Because of this, I’ve created another GitHub repository.
Here is my first attempt to “get it right.” Instead of volume mounting the configuration directories for StreamSets to the local filesystem, I use the MapR POSIX Client built into the PACC to put the configuration directly on MapR XD. This ensures that the user in the container always has access and that the config files are available to StreamSets anywhere they run.
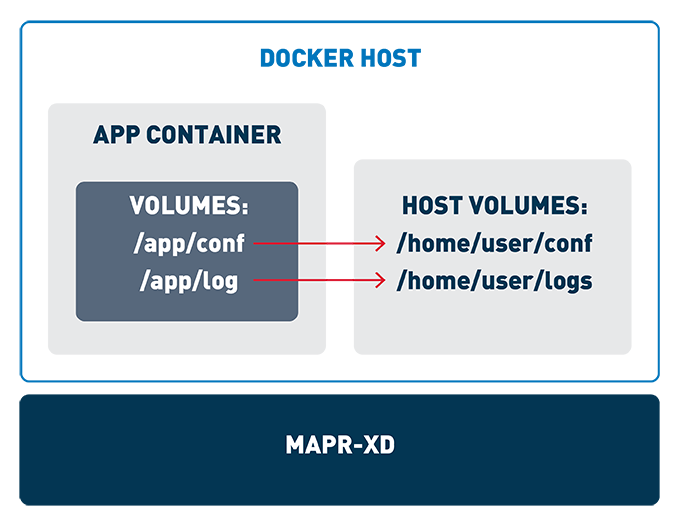
This allowed me to simplify my startup scripts and ensure a much cleaner runtime environment, independent of the system I was running the container on. This is a much better approach and really shows the power of using MapR with Docker containers. I am still learning more about the PACC, but as I learn, I wanted to take the time to share my follies, so others can learn as well. If you take the time to review my repository here and find ways to improve them even more, I am all ears! Leave a comment, or post a GitHub issue.
Related Links:
Related
3 ways a data fabric enables a data-first approach
Mar 15, 2022A Functional Approach to Logging in Apache Spark
Feb 5, 2021
Getting Started with DataTaps in Kubernetes Pods
Jul 6, 2021