
Welcome to the three-part blog series showcasing the remarkable capabilities of HPE Ezmeral Unified Analytics through a real-world use case: Stock Market Prediction. In Part 1 of this series, I will delve into the data engineering aspect of the platform, exploring how it facilitates seamless data management and analysis.
In Part 2 of the blog series, we will take you on a deep dive into the platform's ML/AI capabilities. Together, we will explore how the transformed data can be utilized for model building, leveraging Jupyter notebooks to perform interactive data exploration, pre-processing, and model training. Additionally, you will see how HPE Ezmeral Unified Analytics integrates seamlessly with MLflow for efficient model management and KServe for inference, allowing you to track and reproduce experiments easily.
Finally, in Part 3 of the series, I will focus on automation using MLOps. Now, let's embark on this exciting journey into the design and implementation of this cutting-edge solution.
What is HPE Ezmeral Unified Analytics?
HPE Ezmeral Unified Analytics software is a usage-based Software-as-a-Service (SaaS) platform that fully manages, supports, and maintains hybrid and multi-cloud modern analytics workloads through open-source tools. It goes beyond traditional analytics by seamlessly integrating machine learning and artificial intelligence capabilities, empowering users to develop and deploy data, analytics, and AI applications. By providing access to secure, enterprise-grade versions of popular open-source frameworks, the platform enables efficient and flexible scalability while securely accessing data stored in distributed data platforms. With its consistent SaaS experience, organizations can unlock data and insights faster, make data-driven predictions, and gain valuable business insights for faster decision-making, regardless of whether they operate on private, public, or on-premises infrastructure.
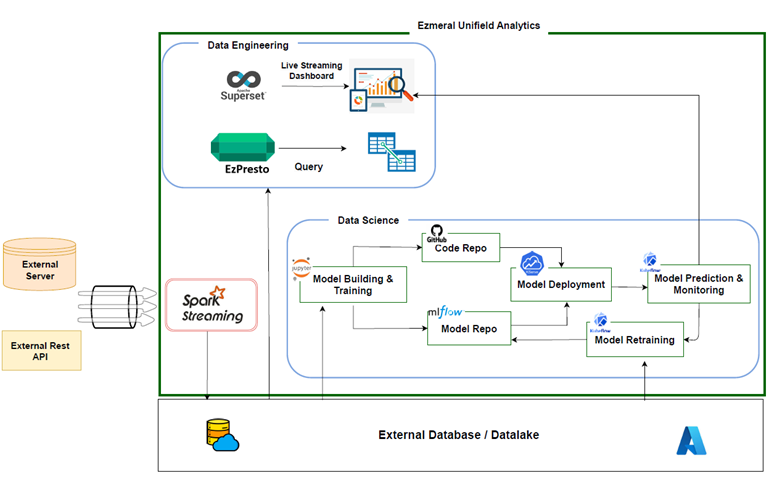
This use case involves leveraging external pricing server/rest API calls, which are streamed into the data lake/data warehouse of a cloud provider (Microsoft Azure) using Spark from HPE Ezmeral Unified Analytics. Let me demonstrate how this platform enables data analysis using EzPresto (an enterprise-supported version of Presto) and empowers the creation of live dashboards using Superset.
Step 1: Data Gathering
The data consists of stock prices of different companies listed in National Stock Exchange (NSE) of India. The files consist of historical data from the year 2000 to 2021, which was transformed to a streaming data source. The data was pulled from external servers hosted publicly and then saved to HPE Ezmeral Data Fabric Volume.

Step 2: Data Ingestion
Apache Livy
HPE Ezmeral Unified Analytics gives access to Apache Livy, which enables easy interaction with the Spark cluster via REST interface. It simplifies the access between Spark cluster and application servers. It enables long running Spark contexts that can be used for multiple Spark jobs and multiple clients. Multiple Spark context can be managed that runs on the Spark Clusters. Spark applications can be either batch jobs or real-time streaming applications as per the business needs. Financial services have both long running batch applications as well as streaming applications, Apache Livy provides seamless management of Spark for the data engineers and application support team.
Apache Livy on the HPE Ezmeral platform enables programmatic, fault-tolerant, multi-tenant submission of Spark jobs from web/mobile apps (no Spark client needed). So, multiple users can interact with the Spark cluster concurrently and reliably. Livy speaks either Scala or Python, so clients can communicate with the Spark cluster via either language remotely. Also, batch job submissions can be done in Scala, Java, or Python.
It enables easy interaction with a Spark cluster over a REST interface. It enables easy submission of Spark jobs or snippets of Spark code, synchronous or asynchronous result retrieval, as well as Spark context management, all via a simple REST interface or an RPC client library.
HPE Ezmeral Unified Analytics provides functions like %reload_ext sparkmagics and %manage_spark for seamless connection to the Spark cluster. %reload_ext sparkmagics loads the Spark session and authenticates the user for secured access to the Spark session. %manage_spark will create the Spark session with predefined Spark cluster configuration in the background.

Once the Livy session is enabled, the code can be run on the notebook servers.

Spark Streaming
Financial applications like real-time transaction processing, fraud detection, trade matching and settlement systems are widely distributed and deal with large volume and variety of data. These systems require parallel processing of transactions in a distributed computing architecture. Hence, Spark streaming best suits the needs of such financial applications like the stock market prediction analysis.
Spark Streaming is a real-time data processing module in Apache Spark, a popular distributed computing framework for big data processing. It enables processing and analysis of live data streams in a scalable and fault-tolerant manner. Spark Streaming brings the power and flexibility of Spark's batch processing capabilities to real-time data streams, making it a versatile choice for various real-time data processing use cases.
Micro-Batch Processing: Spark Streaming follows the micro-batch processing model, where it divides the continuous stream of data into small, discrete batches. Each batch of data is processed as a RDD (Resilient Distributed Dataset), which is Spark's fundamental data abstraction for distributed computing. This approach allows Spark Streaming to process data in mini-batches, providing low-latency processing and better resource utilization.
Data Sources and Sinks: Spark Streaming can ingest data from various sources, including Kafka, Flume, Kinesis, HDFS, TCP sockets, and more. It supports a wide range of input formats, making it compatible with different streaming data pipelines. Similarly, Spark Streaming can write the processed data to various sinks, such as HDFS, databases (e.g., MySQL, Cassandra), and external systems.
Notebook servers
HPE Ezmeral Unified Analytics is equipped with notebook servers that can execute Python commands seamlessly along with scalable resources like CPUs, GPUs, and memory. Notebook servers can be spun up on Kubeflow using pre-defined Jupyter notebook images or custom-built notebook images based on your requirement. It will take a few minutes to bring the notebook server up and running.

Once it is available, you can connect to the notebook server either on HPE Ezmeral Unified Analytics Notebooks Tab or directly from the Kubeflow Notebooks.
MySQL Database
A MySQL database was created and hosted in Microsoft Azure to capture the structured streaming data to a single table. The database server is configured to permit access to the select IP addresses.
Step 3: Streaming data to database
The data is read from HPE Ezmeral Data Fabric volume by the Spark Streaming engine in constant time intervals. The Spark engine converts the files into batches and does some data engineering like transformations and aggregations on the data. Finally, it is saved to MySQL database using jdbc connections. It is mandatory for all the incoming files to share the same schema.
3.1 Load the required Spark libraries.
Once connected to the Livy server, the Spark connection is configured and managed internally by HPE Ezmeral Unified Analytics platform. Now you can directly import the required libraries and you’ll be ready to use Spark.

3.2 Define the Data Schema
Define the data schema for the data to stream in the application.

3.3 Read the input stream of files from the external server
3.4 Write the output stream to the destination path.

3.5 Read the data using Spark SQL and perform Exploratory Data Analysis.

Step 4: Connecting the database to HPE Ezmeral Unified Analytics
HPE Ezmeral Unified Analytics provides users with a quick and simple process to connect to external data sources like different databases, Hive, Snowflake, Teradata, etc. Here a new data source connection is added, and the source is selected as MySQL. The connection is established once the jdbc connection url, username and password are validated.
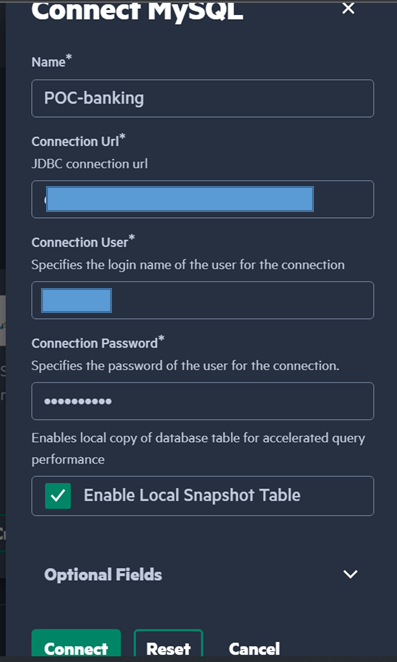
This will connect the database to EzPresto, which is a distributed analytic query engine for big data, integrated into HPE Ezmeral Unified Analytics. This enables users to query the tables in the database using SQL commands. This service helps users to use the database seamlessly by enabling them to insert, delete, update and query records from the tables. The data can be accessed from a remote server or on HPE Ezmeral Data Fabric Software.

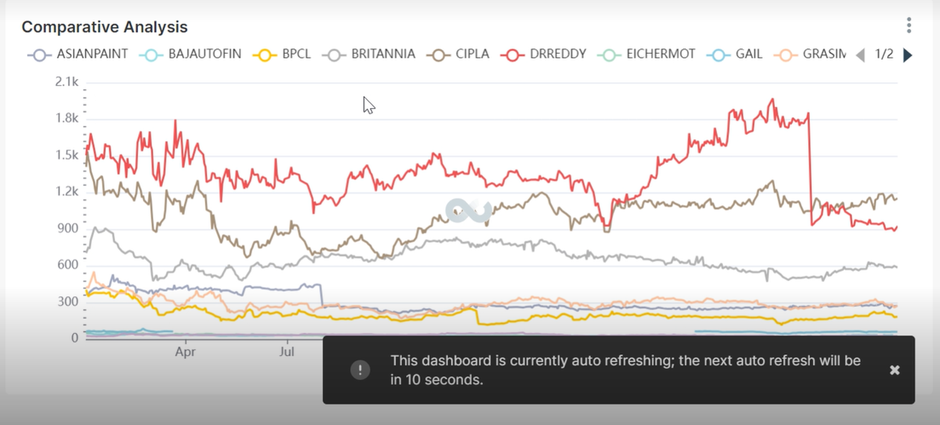
Step 5: Visualization using Superset
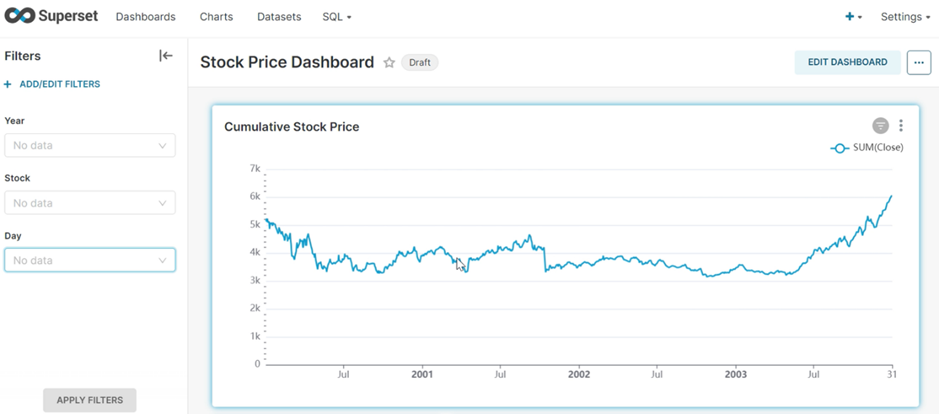
Apache Superset, a data visualization tool has been integrated into HPE Ezmeral Unified Analytics, which helps with the graphical representation of data, from simple line charts to highly detailed geospatial charts. The dashboards help users to get a clear picture of the KPIs and other relevant metrices of the business.
Here, a new dashboard is created in HPE Ezmeral Unified Analytics, and the connection to the database is established. Different visuals on the stock data are integrated into the dashboard and it is customized to auto refresh to a customer-defined time interval. Once the data starts streaming, the dashboard updates the visuals periodically and the latest data is available on the dashboard for analysis.

Summary
In concluding Part 1 of this blog series, you’ve journeyed through the data engineering and analytics aspects of using Spark, EzPresto, and Superset, powered by HPE Ezmeral Unified Analytics. With a spotlight on assimilating external pricing data to craft a dynamic dashboard, I hope I have illuminated how this platform brings together best of breed open-source tools to transform complex data into valuable insights.
Don't miss Part 2, where you’ll get to explore the machine learning capabilities of our platform. To get familiar with HPE Unified Analytics Software, try it for free or visit our website for details. Let's unlock the future of analytics together!
Contributors to this blog post include Suvralipi Mohanta (suvralipi.mohanta@hpe.com), Harikrishnan Nair (harikrishnan.nair@hpe.com), and Joann Starke (joann.starke@hpe.com).
Related
3 ways a data fabric enables a data-first approach
Mar 15, 2022A Functional Approach to Logging in Apache Spark
Feb 5, 2021
Getting Started with DataTaps in Kubernetes Pods
Jul 6, 2021