
Editor’s Note – HPE Ezmeral Container Platform is now HPE Ezmeral Runtime Enterprise. For more information on why the name was changed, please click here.
Apache Spark™ is an awesomely powerful developer tool for finding the value in your data. I highly recommend you check out this Hewlett Packard Enterprise (HPE) white paper for some background – Apache Spark 3 on HPE Ezmeral. In this post, I’m going to explain how I deployed Apache Spark in my own on-premises HPE Ezmeral Container Platform-managed lab so that I could try Apache Spark out for myself.
We need a story first, right?
Suppose your story is similar to mine: I am a data scientist and I work for ACME Windmills Incorporated – or just ACME, for short. ACME owns and operates windmills that generate power. They have multiple sites, such as one in Australia and another one in Southern California. I’ve been asked to predict how much power will be generated by these various sites.
What tools do I have at my disposal?
Our infrastructure team runs all of the hardware and software for the Data Science team. They provide me access to things like a Jupyter Notebook where I will do my Data Science work. The infrastructure team of DevOps engineers and system administrators have the ultimate toolbox to work with, a toolbox called the HPE Ezmeral Software Platform. HPE Ezmeral software enables an “all of the above” approach to deployment and management of ACME's data, apps, and the compute & storage resources that run it all - from anywhere. The infrastructure team can use this toolbox to:
modernize legacy apps, and manage those apps alongside cloud-native apps
use existing data lakes alongside HPE Ezmeral Data Fabric
and all of the hardware and software can be consumed as-a-service from HPE!
For this particular job, the infrastructure team pulled out the HPE Ezmeral Container Platform from the toolbox for application and cluster management. This will provide the data science teams with a wealth of MLOps tools such as an Apache Spark cluster configured to run a customized Jupyter Notebook with connections to ACME’s HPE Ezmeral Data Fabric. I can’t wait to get access to my environment and get to coding!
What is the infrastructure team building for me?
As mentioned above, ACME needs to predict power output from their windmills, so they can make intelligent decisions about where to add more windmills and how to optimize the windmills they already have. This is a job for Apache Spark on Kubernetes on HPE Ezmeral! The infrastructure team amazingly built the following workspace for me in the blink of an eye! This used to take them weeks before they got their hands on the HPE Ezmeral software.

As the figure above indicates, the infrastructure team built a Kubernetes Cluster and deployed the Apache Spark Operator onto it. The Apache Spark Operator is the glue that allows you to run Apache Spark within a containerized environment, such as a Kubernetes Cluster. The infrastructure team then carved out a Kubernetes Namespace and deployed the MLOps applications I will need like that custom Jupyter Notebook I mentioned previously. I will use that Jupyter Notebook to run my Apache Spark jobs.
The code running inside the Jupyter Notebook will make an API call to the Apache Spark Operator using an API server called “Livy”. Livy will ask Apache Spark to create an Apache Spark session so I can perform analytics on the data. Apache Spark will be able to ingest data from the Australia core deployment of HPE Ezmeral Data Fabric using an HPE Ezmeral Container Platform feature called a DataTap (more on that below).
What the infrastructure team built for me
If you are a data scientist or data engineer and you really don’t want to know how all these back-end system administrator tasks are done, then I highly recommend you skip to the Now we get to run our Apache Spark jobs! section. I’d definitely put this section firmly in the infrastructure person category.
First, I log into my HPE Ezmeral Container Platform WebUI. My organization has already setup Active Directory integration to use with the HPE Ezmeral Container Platform WebUI.
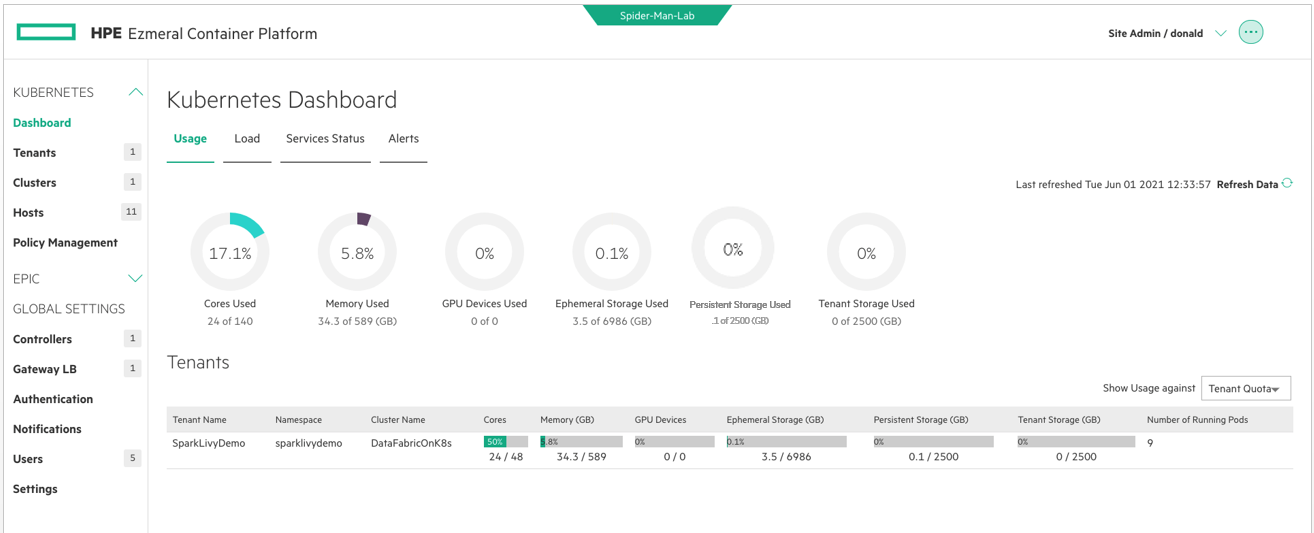
Below, on the Kubernetes Dashboard Web UI page, you can see a list of options in the left hand pane. One of those options is Clusters found under the Kubernetes section in the upper left hand portion of the panel on the left side of the screen. From my dashboard, I click on my Cluster’s option on the left under Kubernetes.
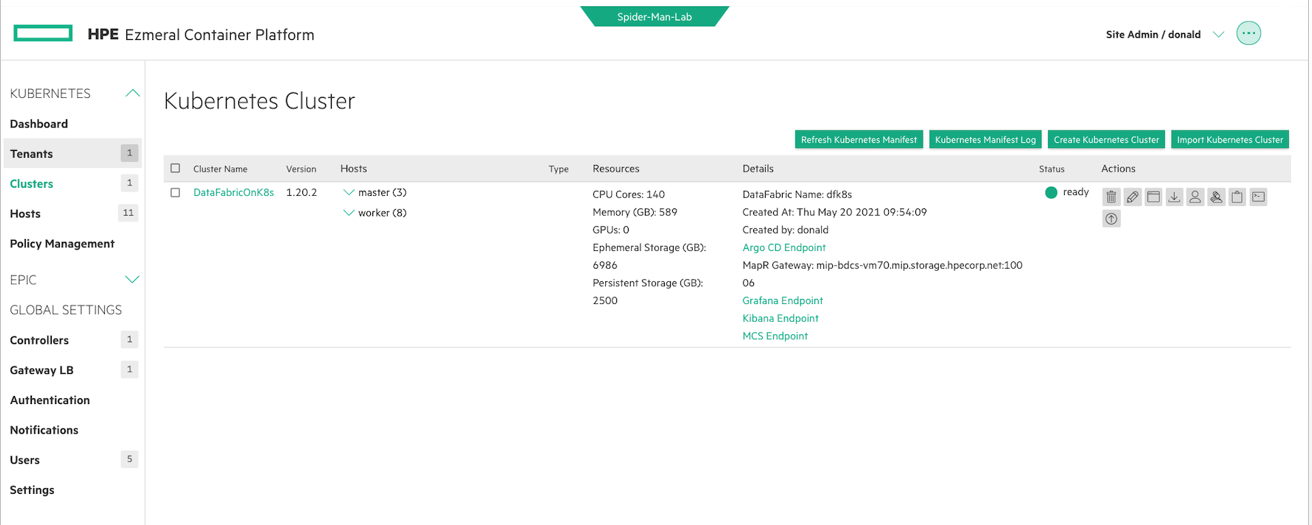
Next, in the Kubernetes Clusters window, I see I have a single cluster called DataFabricOnK8s. This cluster is running a version of HPE Ezmeral Data Fabric that runs within a Kubernetes Cluster. This is handy since now all of my Kubernetes namespaces and other clusters will get the same enterprise-grade storage features available in a Bare Metal deployment of HPE Ezmeral Data Fabric. I will create a new Kubernetes namespace from this cluster. To do that, I click on Tenants on the left. Tenants, as the name implies, are how we organize multiple Kubernetes namespaces in the HPE Ezmeral Container Platform. Or, in other words, how we help you manage multi-tenancy.
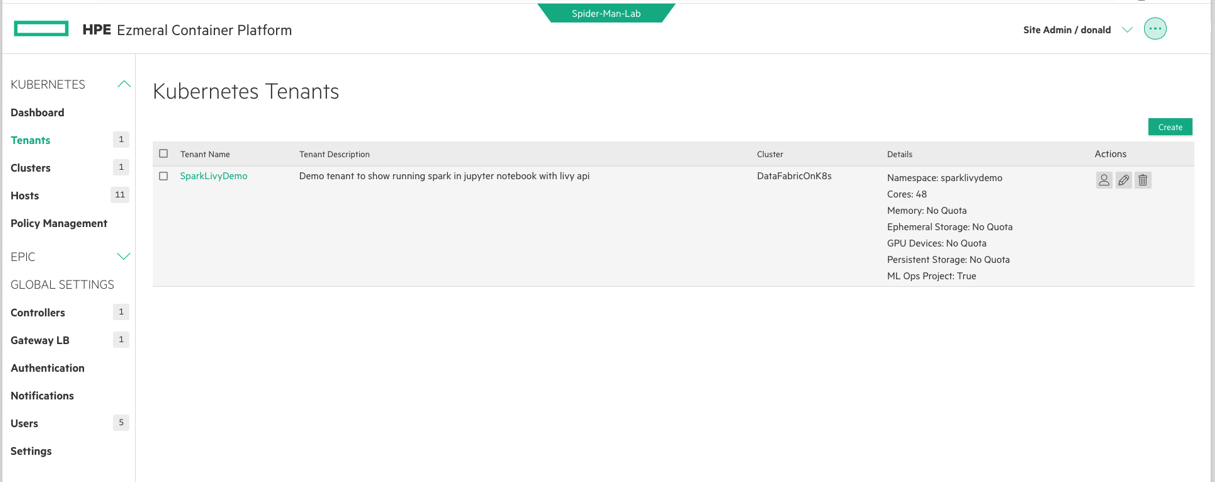
In the Tenants window below, you can see that I created a new tenant on the DataFabricOnK8s cluster. Now I have a place to work and it is called “SparkLivyDemo”. I can use the WebUI to create a Jupyter Notebook in that namespace/tenant by clicking on the hyperlinked name.
Here, I am in my own private “lab”, as I like to call it. This is my tenant work area. When I created my tenant, I chose to include my MLOps licensed content. This provides me with a Kubernetes namespace pre-loaded with all the goodies I need for machine learning, including a Jupyter Notebook tailored to work with my HPE Ezmeral Container Platform DataTaps. Speaking of which, I should add DataTaps to my HPE Ezmeral Data Fabric deployments in Australia and Southern California. I do that by clicking DataTaps on the left.
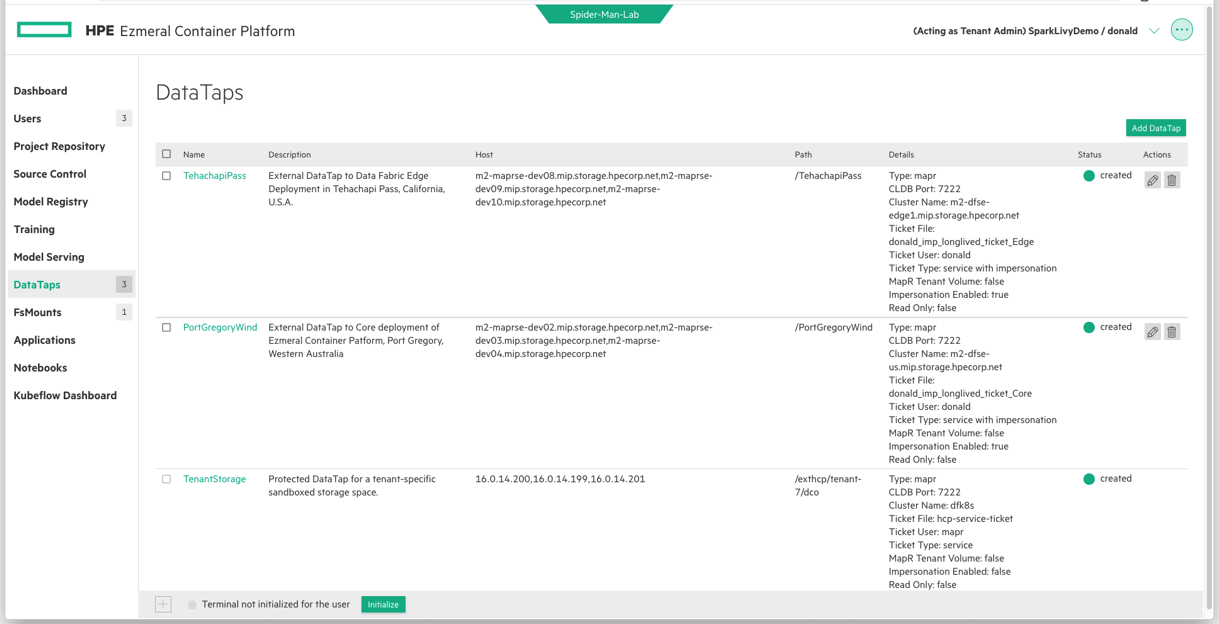
On the screen below, you can see that I’ve tapped into two HPE Ezmeral Data Fabric deployments. I simply clicked on DataTaps in the left hand column of the WebUI and provided the details you see summarized in the Details column to the right of each DataTap Name. You can see that I needed to provide FQDNs to my secure-by-default HPE Ezmeral Data Fabric Core & Edge deployments. I also provided a user authentication Ticket that was generated by the Data Fabric administrator, so access is tightly controlled and easily connected using this WebUI (or REST API if you prefer).
In this DataTaps window, you will also see a 3rd DataTap with a name of TenantStorage. That is a DataTap that is automatically created for me when I created this Tenant, and the storage is persistent and protected and managed by my Data Fabric Kubernetes Cluster.
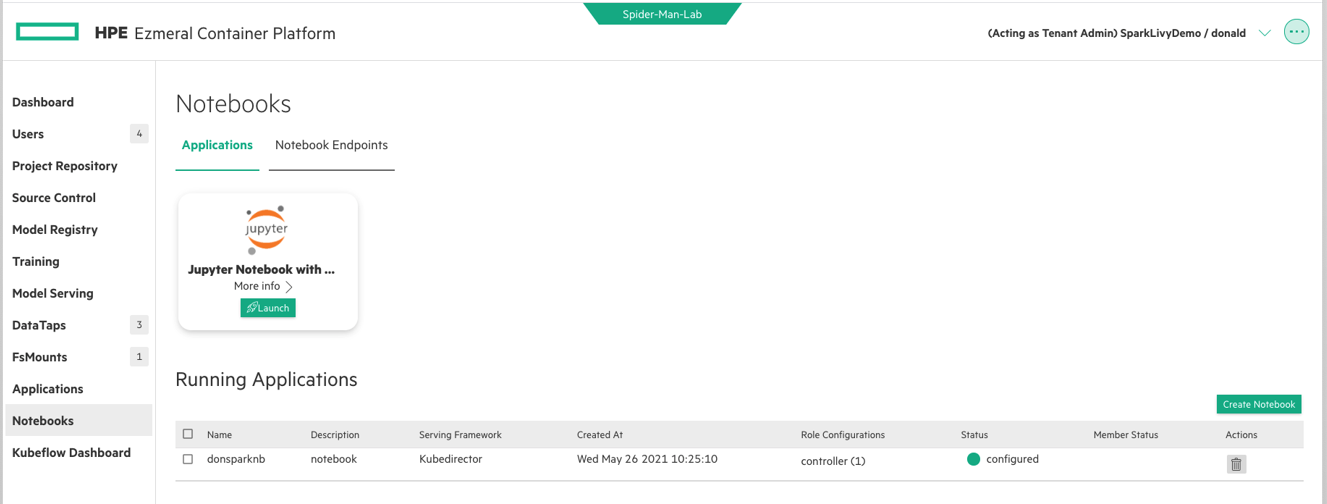
Finally, I launched a custom Jupyter Notebook using the Notebooks section of this MLOps tenant. This Notebook application comes with a full toolkit pre-integrated, so all I need to do is send the access endpoint to my Data Science team.
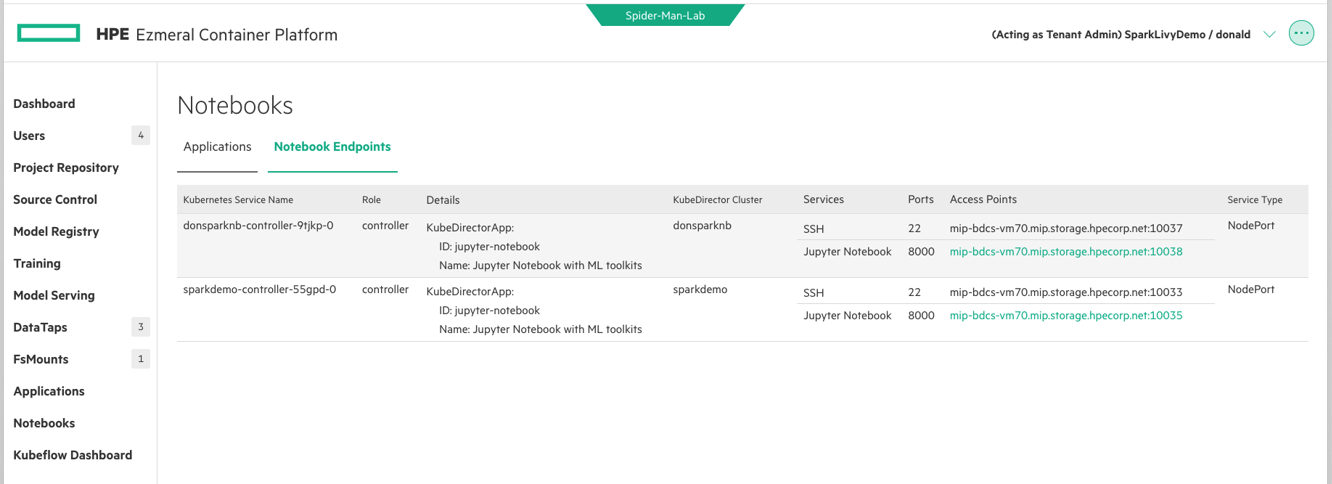
To put my Data Scientists to work, I can just click on the Notebook Endpoints text, copy the Access Point URL, and then send that securely to my Data Science team in whatever manner I wish. Active Directory is passed on to the Jupyter Hub itself, so only an authorized user can log into that Access Point. From the Data Scientist’s perspective, they just pasted a hyperlink into their browser.
You may now remove your infrastructure person hat and proceed to doing some really cool Apache Spark Analytics!
Now we get to run our Apache Spark jobs!
For those of you who put on your infrastructure hat to read the previous section, thank you for sticking with me. Now you get to put on your Data Scientist hat! Or, if you skipped to here, that’s cool, too.
What happened behind the scenes
In the previous section, an infrastructure nerd built a lab out of some servers running a Kubernetes Cluster. Then, that person created a Kubernetes namespace from that cluster and applied the HPE Ezmeral MLOps template to that namespace. The infrastructure nerd also tapped into ACME’s global HPE Ezmeral Data Fabric and connected those DataTaps to a Jupyter Notebook. Just now you, the Data Scientist, received a link or Access Point to your Jupyter Notebook, put that link into your web browser, and logged into Jupyter Hub with your Active Directory credentials.
Jupyter Notebook + Spark (PySpark) + Livy
Here, inside the Jupyter Notebook, is where all the Apache Spark analytics is done. At the top of the file, I set up my Livy URL. I was able to copy this URL directly from my HPE Ezmeral Container Platform’s webUI, within the tenant view. A helpful HPE Ezmeral feature is the addition of MLOps magic commands that get added to this Jupyter Notebook automatically. For more information regarding this, see Kubernetes Notebook Magic Functions. In the screen below, you can see that the first Jupyter Notebook cell includes the%setLivy magic command. This command allows a Jupyter Notebook developer to specify the URL of the Livy server.
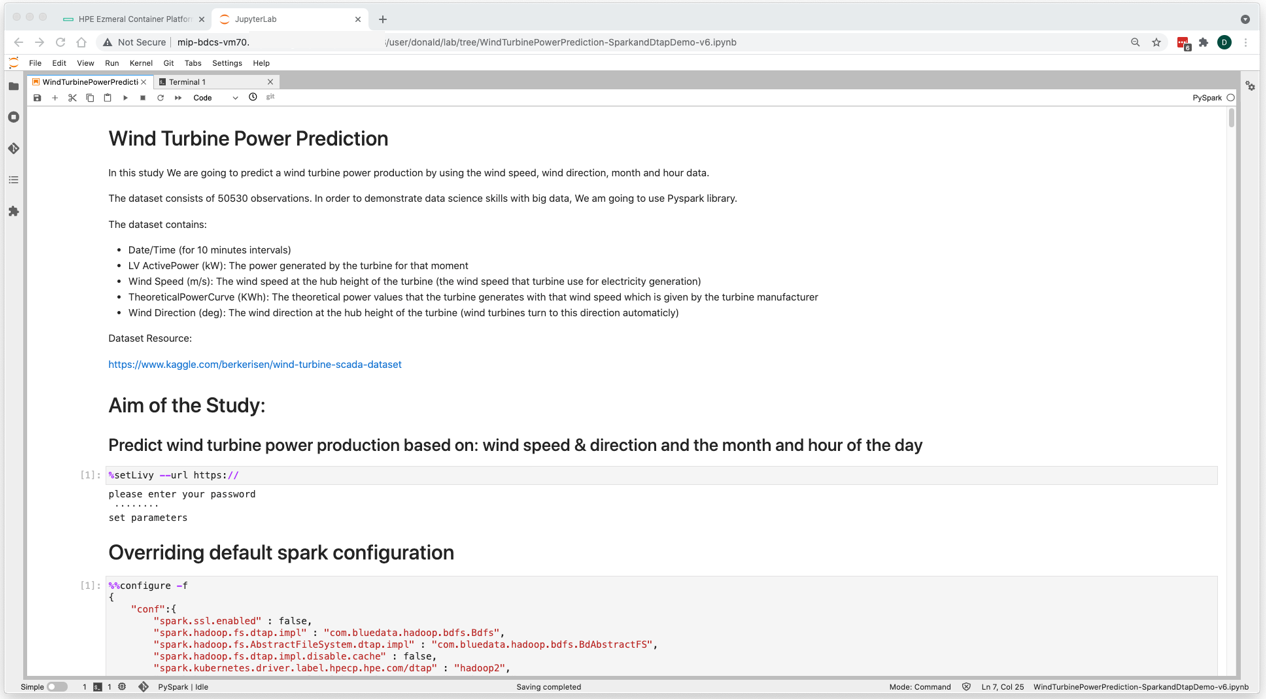
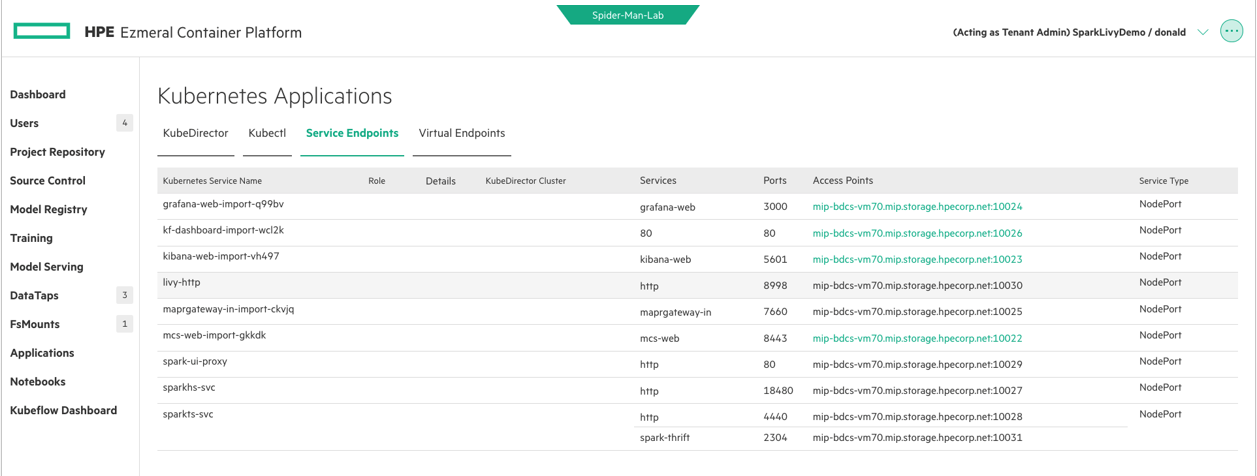
The URL that is provided to the %setLivy magic command can be obtained from the HPE Ezmeral Container Platform’s WebUI under the “Applications” menu option under the Service Endpoints link. Here, in the Service Endpoints page you will find the livy-http URL or Access Point and the corresponding port.
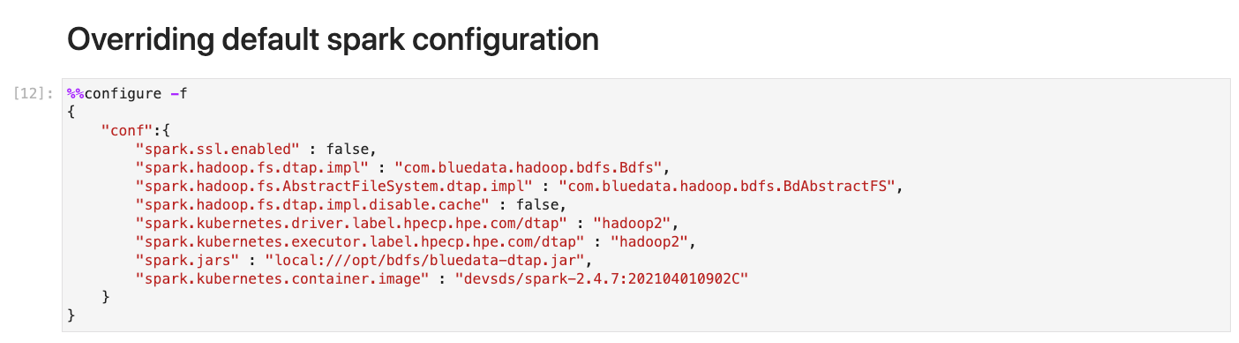
Next, within this Jupyter Notebook I use the %%configure command to override the default Apache Spark configuration and customize this Spark environment. This allows me to specify exactly what I need for this particular Apache Spark job.
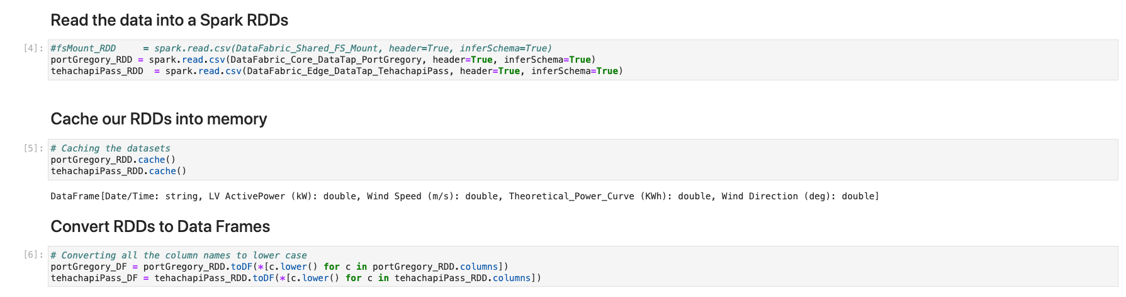
Moving down in my Jupyter Notebook, I next import some libraries needed to analyze and transform my data.

Here, I define a few simple variables and connect the Apache Spark code to the global HPE Ezmeral Data Fabric – all thanks to the infrastructure person who set up those DataTaps for me. I could also have taken advantage of some of the other pre-configured local sandbox storage options automatically generated for me when my MLOps tenant was created. Like, for example, an NFS shared repository called an FS Mount and the Tenant Storage sandbox managed by our HPE Ezmeral Data Fabric on Kubernetes Cluster.

From this point on, it is pure Apache Spark running in this standard Jupyter Notebook framework, using the PySpark kernel of the Jupyter Notebook.
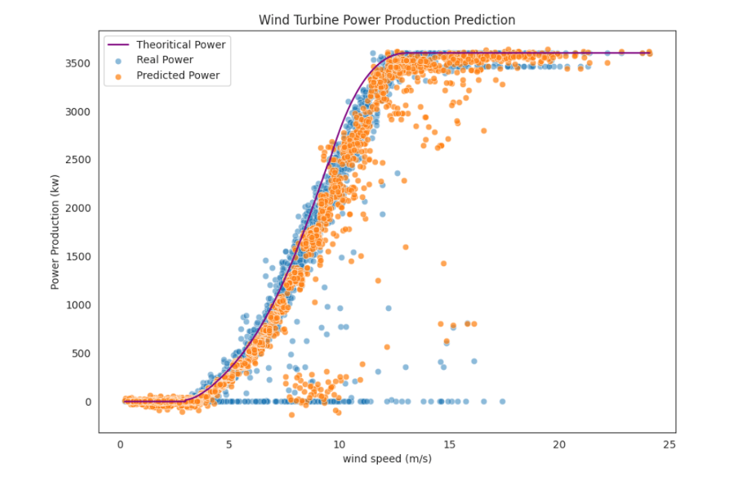
The final result from all this hard work is a Wind Turbine Power Production Prediction graphic plot – created within this same Jupyter Notebook. You can see from the graphic that my predictive model is lining up with actual, real power data. I can now ship this model off to be used by other members of the team.
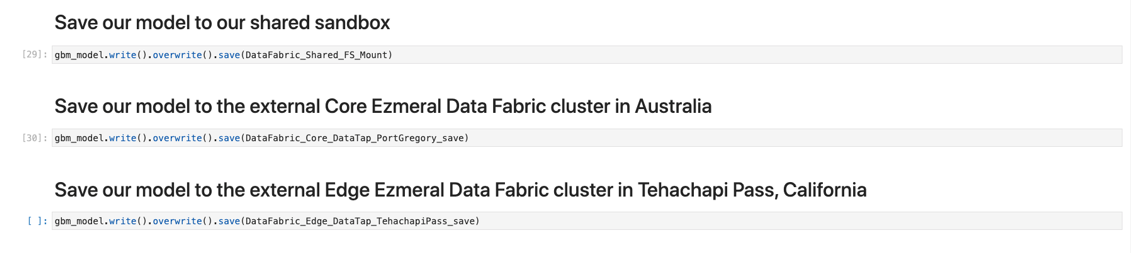
In the final lines of my Jupyter Notebook, I again use the DataTaps and standard PySpark commands (and also the NFS FS Mount feature) to save this model back out to the Australia and Southern California Ezmeral Data Fabric deployments and to the local sandbox storage.
Well, that was fun!
As you can see, going through this whole process I wore a couple of hats: Infrastructure or DevOps and Data Scientist or Data Engineer. With my Infrastucture hat on, I used the HPE Ezmeral Container Platform to create a workspace for the Data Science teams. That workspace is, in fact, a Kubernetes Cluster and one or more namespaces managed in a multi-tenant, secure environment.
Everything discussed here was illustrated using the HPE Ezmeral Container Platform WebUI, but that is for illustration purposes only. HPE Ezmeral software is totally REST API enabled. This one example of building a single MLOps model is relatively simple. In reality, you would run a full MLOps pipeline and use other tools such as KubeFlow or AirFlow to build a pipeline of much more complex and iterative models – and that is built into the HPE Ezmeral Container Platform, as well. In addition, you can integrate directly with ML Flow in the same tenant workspace that I demonstrated here for much more powerful model management. Further, you can use the MLOps training, model management, and deployment features to fully control your machine learning pipelines.
I hope you found this information interesting and look forward to helping you to extract the value from your data more efficiently and securely than ever before in subsequent HPE DEV blog posts.
Related
3 ways a data fabric enables a data-first approach
Mar 15, 2022A Functional Approach to Logging in Apache Spark
Feb 5, 2021
Getting Started with DataTaps in Kubernetes Pods
Jul 6, 2021