
On December 8th, 2023, Mistral AI released Mixtral 8x7B, a high-quality sparse mixture of experts model (SMoE) with open weights (ref: Mistral AI). What is this Mixtral 8x7B? Very simply, it takes 8 x Mixtral 7B models and combines them to make one model. For those who are unfamiliar with the term Mixture of Experts (MOE), it is a machine learning technique that uses multiple expert networks to divide a problem space into homogeneous regions. As noted in this paper, MOE models build upon the observation that language models can be decomposed into smaller, specialized sub-models, or "experts". These models or experts focus on distinct aspects of the input data, thereby enabling more efficient computation and resource allocation. It has become quite popular because AI models with sparsely activated MOE significantly reduce the computational involved with large language models (LLMs).
So, how does it work? If you are into LLM modeling, you probably know that the most simple representation of an LLM would be an input going into a single model and producing an output. In an MOE model, your input goes through a gateway that decides, based on the input context, which of the eight models are to be used to process the input. It could be just one model or possibly two or more that will process the input and coordinate to product the output. Below is a simplified pictorial representation of the process:
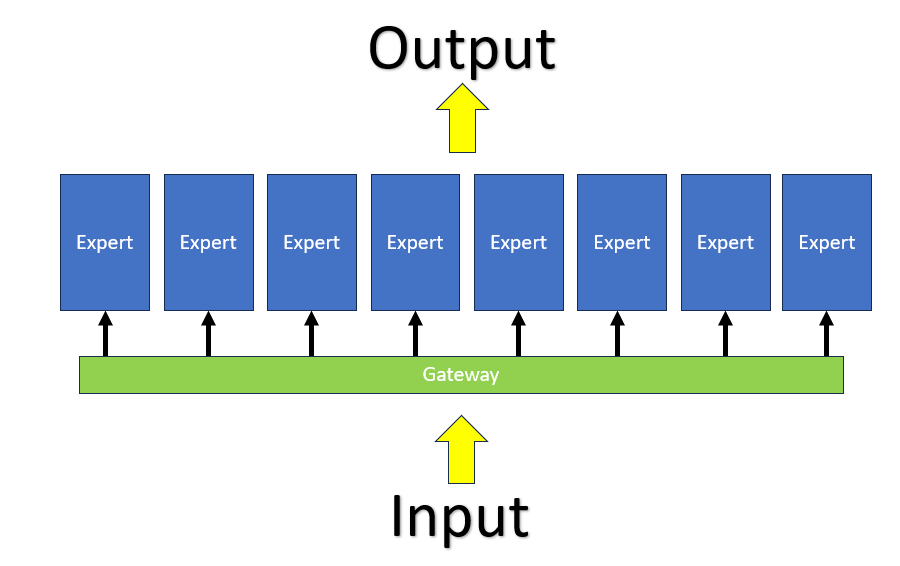
To best understand this, you could compare it to your supervisor looking at the nature of a job and finding the best expert within his team (i.e. MOE model) to complete the task rather than giving all the tasks to a single person (i.e. the traditional LLM model). In this way, it is much more efficient, except that you now need to maintain eight models instead of one.
Generally, models often reuse the same parameters for all inputs. But MOE models uses different parameters based on the input given. Routing multiple models is not as easy as you think. There is an overhead in communication between the models as well as the routing between them. This paper explains it well. The gating network (typically a neural network), produces a sparse distribution over the available experts. It might only choose the top-k highest-scoring experts, or softmax gating, which encourages the network to select only a few experts. Getting the right balance is not easy, meaning that you may end up choosing the same expert every single time versus evenly distributing it across the experts.
How good is Mixtral 8x7B? According to mistral AI, Mixtral 8x7B outperforms Llama 2 70B on most benchmarks with 6x faster inference. It is the strongest open-weight model with a permissive license and the best model overall regarding cost/performance trade-offs. In particular, it matches or outperforms GPT3.5 on most standard benchmarks (see diagram below). As you may have guessed, there isn't a performance comparison against GPT 4. Hopefully, we will see one put together in the near future.

From the benchmarks, you can see that even the scrore for the LLaMA 2 70B parameters outperform Mixtral 8x7B parameters by only a few percentage points. Mixtral also shows improvements in reducing hallucinations and biases in the TruthfulQA/BBQ/BOLD benchmark.
If you look at the post on "X" (below), the filename says it all.

Mixtral 8x7B stands out for its high-quality performance. The model boasts a range of capabilities, including the ability to handle a context of 32k tokens and support for multiple languages, including English, French, Italian, German, and Spanish. Mixtral is a decoder-only sparse mixture-of-experts network. Its architecture enables an increase in parameters while managing cost and latency. Take note that all the expert models are loaded into VRAM, which means it requires lots of super-fast VRAM. Also, the model only uses a fraction of the total set of parameters per token. According to Mistral AI, Mixtral has 46.7B total parameters, but it only uses 12.9B parameters per token. What this mean is that it processes both input and generate output at same cost as a 12.9B parameters. Hence, it lowers LLM computational cost.
You might be wondering if you can deploy one and try it out? This would be unlikely for most general users, unless they happen to have some spare 2 x 80GB 100A or 4 x 40 GB 100A GPs lying around or have access to them through a cloud provider. However, there are some demo platforms you can go to and try it out. Here are a few you can look into: Perplexity, Poe, Vercel, and Replicate. Below is a screenshot of what I found on Perplexity:
Is this something new? Nope. This paper called "Adaptive Mixtures of Local Experts" written by the GodFather of AI, Geoffrey Hinton back in 1991, already talk about this concept. Like most AI, the advancement in computing technology, the affordability of computational cost and the availability of mass amount of data make those technology conceptualized in the early days, possible now.
So, why the sudden interest in Mixture of Experts? Although OpenAI hasn't publicly commented on the details of the GPT-4 technical specifications, it has been shared within the OpenAI developer community that GPT-4 uses a Mixture of Experts model. With the release of a Mixtral 8x7B model to the open source world, it could very well set a trend for future model developers to embark on a similar path. Who really knows? Only time will tell.
Related

Announcing GenAI studio: Your generative AI playground built on Determined
Mar 13, 2024
From generative to agentic AI: Tracing the leap from words to actions
Jul 3, 2025
Getting started with Retrieval Augmented Generation (RAG)
Nov 14, 2024
How to Pick a Large Language Model for Private AI
Nov 13, 2024Using structured outputs in vLLM
Mar 16, 2025