
LLM Agentic Tool Mesh: Empowering Gen AI with Retrieval-Augmented Generation (RAG)
January 8, 2025In our previous blog posts, we explored the Chat Service and the Agents Service of LLM Agentic Tool Mesh, highlighting how they simplify the integration of Generative AI (Gen AI) into applications.
Today, we'll dive into another pivotal feature of LLM Agentic Tool Mesh: Retrieval-Augmented Generation (RAG) Service. We'll explain what RAG is, how LLM Agentic Tool Mesh handles it, delve into the RAG services, and showcase an example of an agentic tool using RAG.
Understanding Retrieval-Augmented Generation (RAG)
RAG is a technique that enhances the capabilities of language models by providing them with access to external knowledge sources. Instead of relying solely on the information contained within the model's parameters, RAG allows models to retrieve and utilize relevant data from external documents or databases.
This approach improves the accuracy and relevance of generated responses, especially in domains requiring up-to-date or specialized information. The key benefits of RAG are:
- Enhanced accuracy: Provides more precise and factual responses by accessing more data available externally
- Domain specialization: Enables models to handle specialized topics by leveraging domain-specific documents
- Reduced hallucinations: Minimizes the generation of incorrect or nonsensical information by grounding responses in real data
RAG in LLM Agentic Tool Mesh
In the LLM Agentic Tool Mesh platform, RAG is a crucial tool that can enhance a language model's capabilities by integrating external knowledge. LLM Agentic Tool implements RAG through two main stages:
- Injection
- Retrieval
Each stage is designed to standardize and optimize data use, ensuring generated content is both relevant and accurate.
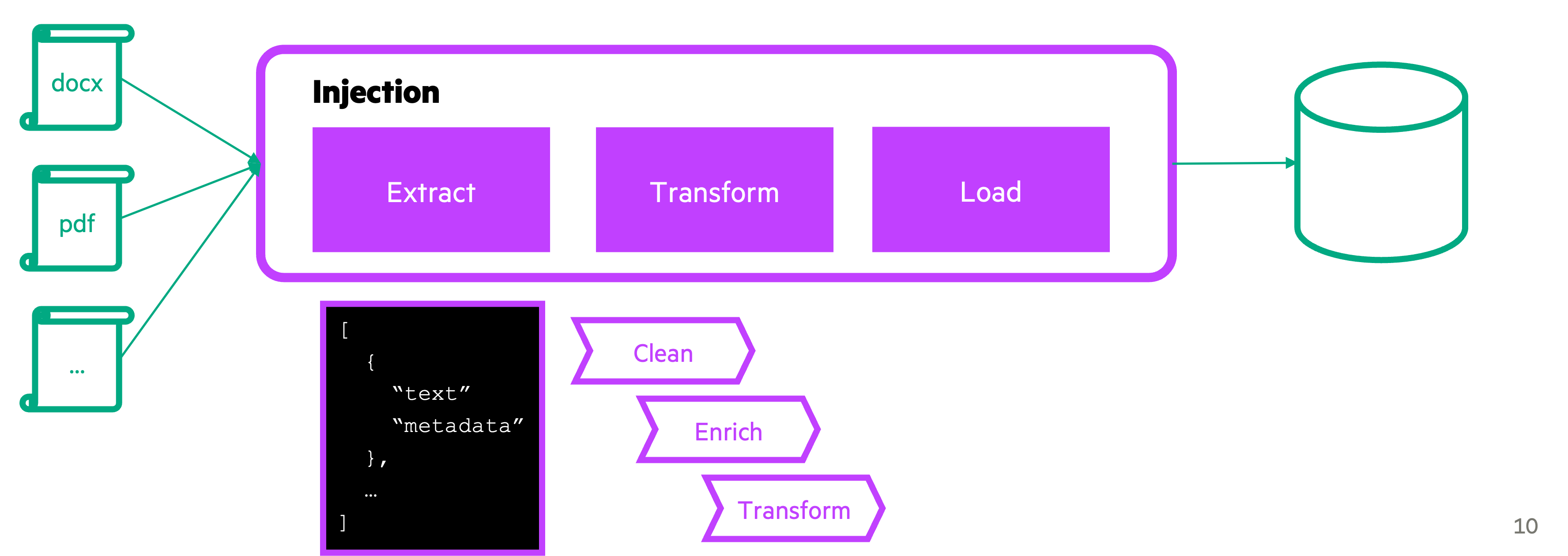
The injection process
The injection process involves preparing and integrating data into a storage system where it can be efficiently retrieved when content is being generated.
This process is abstracted into three key steps:
- Extraction
- Transformation
- Loading
Extraction
As part of the extraction phase, data gathering involves collecting information from various sources, such as DOCX, PDF, or other formats, and converting it into a common format, typically JSON, to ensure consistency.
Example usage
# Configuration for the Data Extractor EXTRACTOR_CONFIG = { 'type': 'UnstructuredSections', 'document_type': 'Pdf', 'cache_elements_to_file': True, 'extract_text': True, 'exclude_header': True, 'exclude_footer': True, 'extract_image': False, 'image_output_folder': './images' } # Initialize the Data Extractor data_extractor = DataExtractor.create(EXTRACTOR_CONFIG) # Parse a document file file_path = 'example_document.pdf' result = data_extractor.parse(file_path) # Handle the extraction result if result.status == "success": print(f"EXTRACTED ELEMENTS:\n{result.elements}") else: print(f"ERROR:\n{result.error_message}")
Transformation
As part of the transformation phase, the process involves cleaning the data by removing irrelevant or redundant information, enriching it with metadata to enhance searchability during retrieval, and transforming the cleaned data using LLMs to generate summaries, question-and-answer pairs, or other structured outputs.
Example usage
from athon.rag import DataTransformer # Configuration for the Data Transformer TRANSFORMER_CONFIG = { 'type': 'CteActionRunner', 'clean': { 'headers_to_remove': ['Confidential', 'Draft'], 'min_section_length': 100 }, 'transform': { 'llm_config': { 'type': 'LangChainChatOpenAI', 'api_key': 'your-api-key-here', 'model_name': 'gpt-4o' }, 'system_prompt': 'Summarize the following content.', 'transform_delimeters': ['```', '```json'] }, 'enrich': { 'metadata': { 'source': 'LLM Agentic Tool Mesh Platform', 'processed_by': 'CteActionRunner' } } } # Initialize the Data Transformer data_transformer = DataTransformer.create(TRANSFORMER_CONFIG) # List of extracted elements to be transformed extracted_elements = [ {"text": "Confidential Report on AI Development", "metadata": {"type": "Header"}}, {"text": "AI is transforming industries worldwide...", "metadata": {"type": "Paragraph"}} ] # Define the actions to be performed actions = ['RemoveSectionsByHeader', 'TransformInSummary', 'EnrichMetadata'] # Process the elements result = data_transformer.process(actions, extracted_elements) # Handle the transformation result if result.status == "success": print(f"TRANSFORMED ELEMENTS:\n{result.elements}") else: print(f"ERROR:\n{result.error_message}")
Loading
As part of the loading phase, the process includes injecting the transformed data into the chosen storage solution, such as a vector database, and further adapting the data as needed, such as chunking it into smaller pieces for efficient retrieval.
Example usage
from athon.rag import DataLoader # Configuration for the Data Loader LOADER_CONFIG = { 'type': 'ChromaForSentences' } # Initialize the Data Loader data_loader = DataLoader.create(LOADER_CONFIG) # Example collection (retrieved from a DataStorage instance) collection = data_storage.get_collection().collection # List of elements to be inserted elements = [ {"text": "Generative AI is transforming industries.", "metadata": {"category": "AI", "importance": "high"}}, {"text": "This document discusses the impact of AI.", "metadata": {"category": "AI", "importance": "medium"}} ] # Insert the elements into the collection result = data_loader.insert(collection, elements) # Handle the insertion result if result.status == "success": print("Data successfully inserted into the collection.") else: print(f"ERROR:\n{result.error_message}")
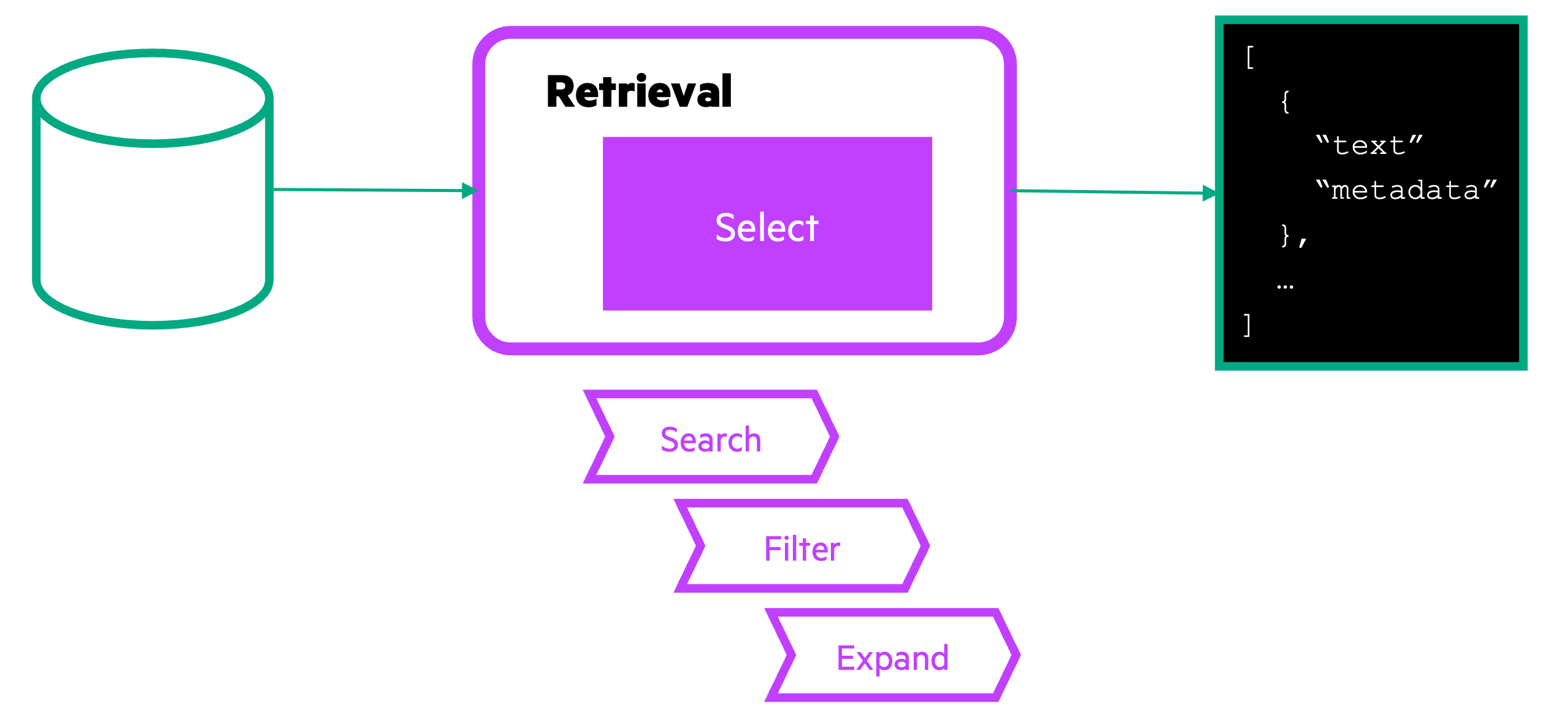
The retrieval process
Once the data has been injected and is ready for use, the retrieval process focuses on fetching the most relevant information based on a given input query. This ensures that the language model has access to the right data to generate accurate and contextually relevant outputs.
- Data retrieval: Uses various methods, such as dense or sparse retrieval, to fetch the most relevant data from storage
- Metadata filtering: Applies metadata filters to narrow down search results, ensuring the retrieved data matches the specific needs of the query
- Chunk Expansion: Expands the retrieved data chunks to provide comprehensive information for the language model
Example usage
from athon.rag import DataRetriever # Configuration for the Data Retriever RETRIEVER_CONFIG = { 'type': 'ChromaForSentences', 'expansion_type': 'Section', 'sentence_window': 3, 'n_results': 10, 'include': ['documents', 'metadatas'] } # Initialize the Data Retriever data_retriever = DataRetriever.create(RETRIEVER_CONFIG) # Example collection (retrieved from a DataStorage instance) collection = data_storage.get_collection().collection # Query to search within the collection query = "What is the impact of Generative AI on industries?" # Retrieve relevant data based on the query result = data_retriever.select(collection, query) # Handle the retrieval result if result.status == "success": for element in result.elements: print(f"TEXT:\n{element['text']}\nMETADATA:\n{element['metadata']}\n") else: print(f"ERROR:\n{result.error_message}")
LLM Agentic Tool Mesh in action: Agentic tool using RAG
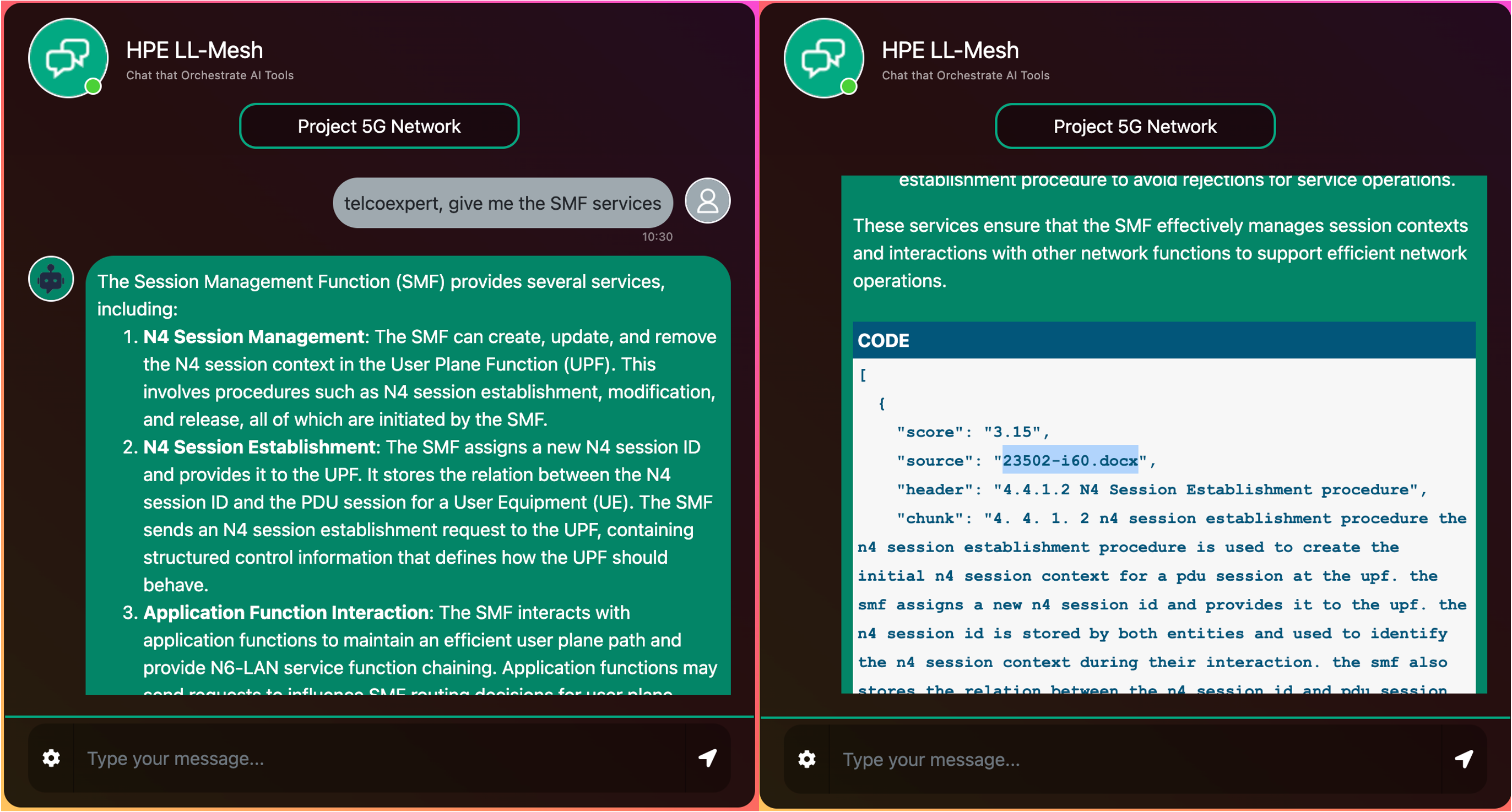
In the LLM Agentic Tool Mesh GitHub, there is an example of a RAG-based tool that provides quick and accurate access to 5G specifications: the telco expert (inside folder examples/tool_rag).
This agentic tool leverages the RAG services in LLM Agentic Tool Mesh to read telco standards, build or use a vector store from them, and then uses a query engine to find and return relevant information based on user queries.
For enhanced observability, the telco expert not only provides the answer but also displays the retrieved chunks used to formulate the response. This includes both the text of the chunks and their associated metadata, such as the document source, date, and other relevant details. This feature allows users to verify the origin of the information and gain deeper insights into the data supporting the answer.
Tool code snippet
@AthonTool(config, logger) def telco_expert(query: str) -> str: """ This function reads the telco standards, builds or uses a vector store from them, and then uses a query engine to find and return relevant information to the input question. """ collection = _get_collection() if LOAD: _load_files_into_db(collection) augment_query = _augment_query_generated(query) rag_results = _retrieve_from_collection(collection, augment_query) ordered_rag_results = _rerank_answers(augment_query, rag_results) summary_answer = _summary_answer(augment_query, ordered_rag_results) chunk_answer = _create_chunk_string(ordered_rag_results) return summary_answer + "\n\n" + chunk_answer
The functionalities shown are:
- Data injection: Loads telco standards into a vector store
- Query augmentation: Enhances the user's query for better retrieval
- Data retrieval: Retrieves relevant chunks from the vector store
- Answer generation: Summarizes and formats the retrieved information to provide a comprehensive answer
Conclusion
The RAG Service in LLM Agentic Tool Mesh exemplifies how advanced design principles and innovative engineering simplify and enhance the adoption of Gen AI. By abstracting complexities and providing versatile examples, LLM Agentic Tool Mesh enables developers and users alike to unlock the transformative potential of Gen AI in various domains.
Stay tuned for our next post, where we'll explore the System Service of LLM Agentic Tool Mesh, essential for creating and managing a mesh of tools, as we continue our journey to democratize Gen AI!
Related
HPE Athonet LLM Platform: Divide et impera, designing the LLM Agentic Tool Mesh
Apr 9, 2024HPE Athonet LLM Platform: Driving Users towards peak 'Flow' efficiency
Mar 20, 2024HPE Athonet LLM Platform: From personal assistant to collaborative corporate tool
Mar 13, 2024LLM Agentic Tool Mesh: Democratizing Gen AI through open source innovation
Nov 11, 2024LLM Agentic Tool Mesh: Orchestrating agentic tools for the AI revolution
Jan 20, 2025LLM Agentic Tool Mesh: Exploring chat service and factory design pattern
Nov 21, 2024LLM Agentic Tool Mesh: Harnessing agent services and multi-agent AI for next-level Gen AI
Dec 12, 2024