
Kubernetes Application Containers: Managing Containers and Cluster Resources
July 10, 2020Original Post Information:
"authorDisplayName": "Suzanne Ferry",
"publish": "2018-10-12T07:00:00.000Z",
"tags": "containers, kubernetes"Application Containers – What They Are, What They Do, And Why They Matter

We’ll start with an overview of what application containers are and how they are used in enterprises to help improve deployment time, consistency, and the efficiency and availability of applications. Along the way, we will cover key characteristics of what containers can and cannot do, and how they compare to virtual machines.
We will also cover how Kubernetes is used to orchestrate containers and associated resources. We’ll discuss how Kubernetes schedules the deployment of containers, scales container resources, manages communication between applications in containers, and is used to monitor the health and availability of containers. Combining the HPE Ezmeral Data Fabric with application containers and Kubernetes makes applications fully capable of consuming and processing live, enterprise-level data.
Editor’s Note: MapR products referenced are now part of the HPE Ezmeral Data Fabric.
What’s an Application Container?
An application container is a stand-alone, all-in-one package for a software application. Containers include the application binaries, plus the software dependencies and the hardware requirements needed to run, all wrapped up into an independent, self-contained unit.
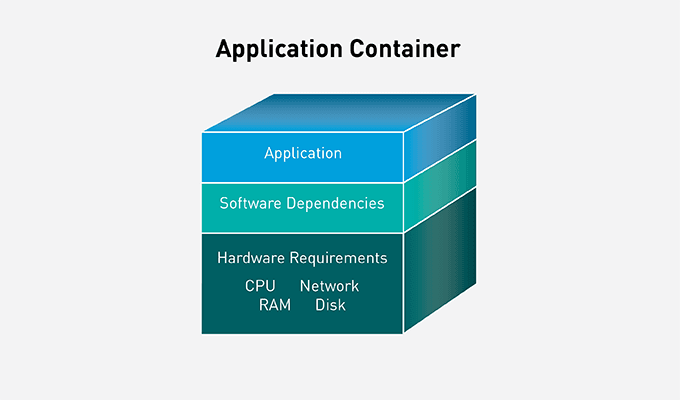
Deploy Containers
The application container is dropped into a system, then runs using the local hardware and operating system. Since it includes all of the necessary dependencies, the container functions exactly the same when deployed on a laptop, on a server, on a virtual machine, in the cloud, or on any other compatible system.
Share Containers
As a self-contained package, an application container can easily be moved to a different system, or even be uploaded and downloaded using a software hub, to be shared with others.

Containerized Applications in the Enterprise Environment
Let’s take a look at an example of how and why you might containerize an application in an enterprise environment.
This example tracks how containers are used in the development cycle of an app designed to monitor the health sensors on wearable devices. The sensor data is streamed to the customer’s health care provider network, which performs machine learning on the data, to look for warning signs of health issues.

Development of the health monitoring sensor tracking app is done by a team of developers, working on laptops. They commit their work to a software hub every day. For reasons that will become clear in a moment, let’s assume that the development laptops are all 3 - 4 years old, use spinning hard drives, have 16 GB of RAM, and each has its own, specialized version of some flavor of Linux and an IDE. The application works flawlessly in their development environment.

Containerized Microservices
Because the health monitoring application is large and complex, it gets broken into microservices, in order to run more efficiently. Each service is then packaged into a separate application container.
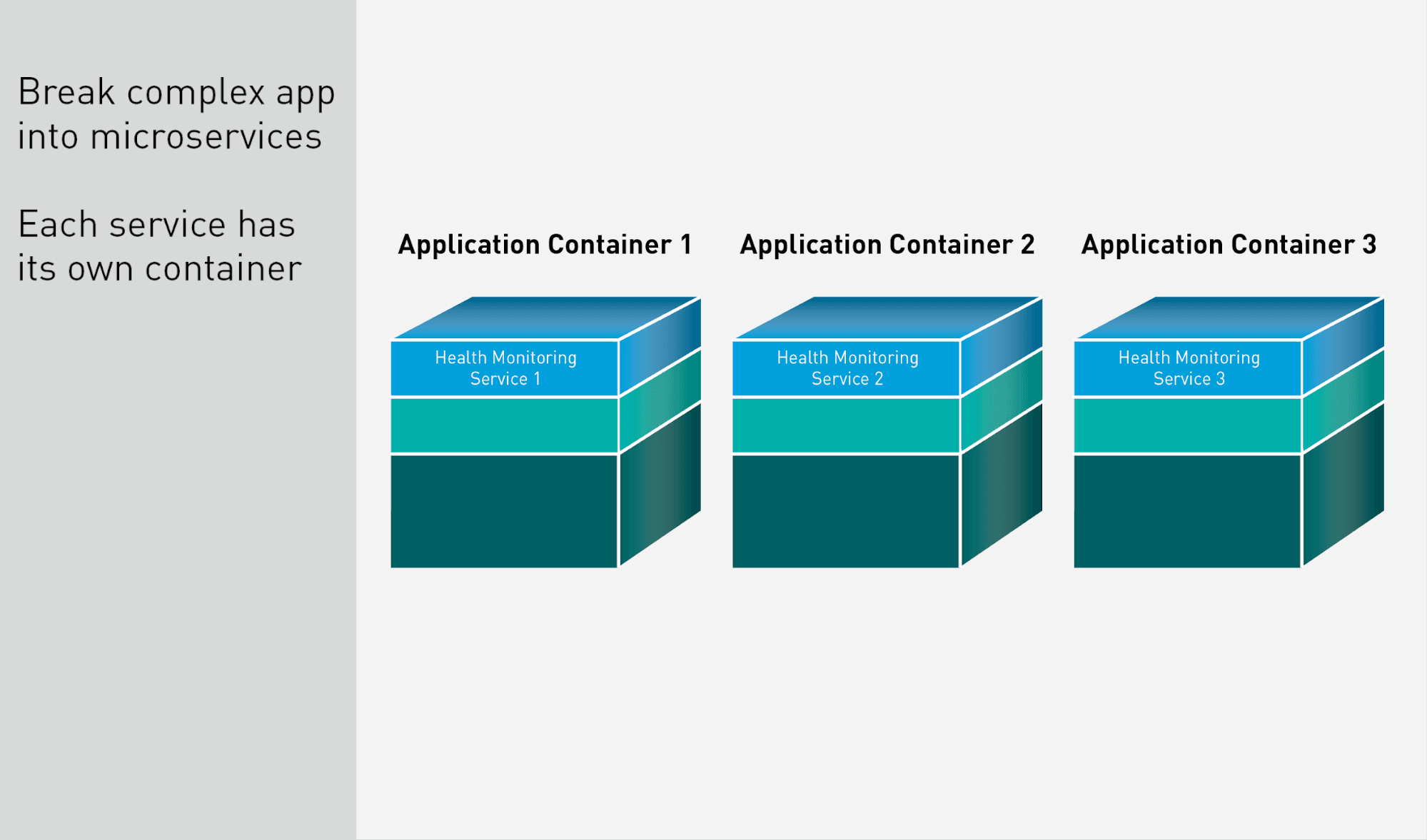
Complete Containers
Each container includes the final code binaries for the individual services.
Included are the dependencies for each service, such as the libraries and APIs needed to communicate with the sensors on any device the app supports, geolocation to know where the data is coming from, data streaming, web protocols, authentication with the health care system, and anything else needed for the app to run.
Also included is a YAML (YAML Ain't Markup Language) file, which defines the CPU, RAM, network, and storage needs for each service.
Each container includes only the dependencies it needs for the single service in it. The microservices approach allows each container to specialize for its service. Two services can even use different versions of the same library if needed, because the container environment allows them to function independently of each other.

Application Testing Environment
Once application development is complete, the containers are tested by the QA team.
The QA environment uses a dozen nodes with CentOS, running a stripped-down version of the live environment. The servers are a few years old; they vary greatly with CPU speed and cores and the amount of RAM and network cards on each server. Some have spinning disks while others use SSDs.

Because containers include all the software dependencies each service needs, the application runs exactly the same on the QA servers as it did on the development laptops cited earlier.
Containers define what hardware resources are required for each service to run. The server carves these resources out when the service is needed and provides them for the container. The service runs inside the containerized environment, which is spared from having its resources cannibalized by other applications on the server. When the service is no longer needed, the container is shut down and the resources are released back to the system.

Application Live Environment
When the application clears QA, it is ready to be released on the live environment, which, in this example, is made up of 100 nodes in a distributed cluster. These nodes use CentOS on the very latest hardware with 12 cores, 256 GB of RAM, SSDs, and gigabit network cards.
Again, because the services are containerized with all of the dependencies they need, they run just as they did on the development laptops and QA servers, albeit quite a bit faster. The application services run happily in their containers, safe from disturbance by any other applications on the system, pulling resources when needed and releasing them when not.
High Availability with Containers
To create high availability for the application, each service is scaled by spinning up multiple instances of the container image and distributing them across the cluster. Each container only includes a single service and its dependencies, which makes them very lightweight. Cloning and launching new copies of a container takes just seconds. Quickly, several copies of the services are spread out across the cluster, each performing the work sent to it and returning results, independent of the other copies in the environment.
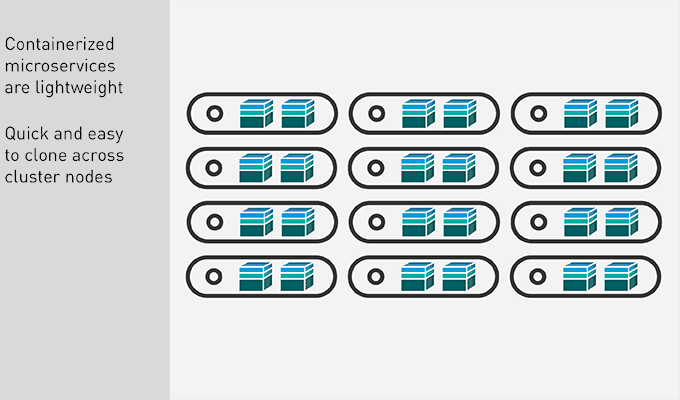
Share Containers
To share containers, you could, for example, just upload the containers to the cloud where they can be downloaded. Since the containers include everything the app needs to run, it will run functions the same as it does on your own clusters.
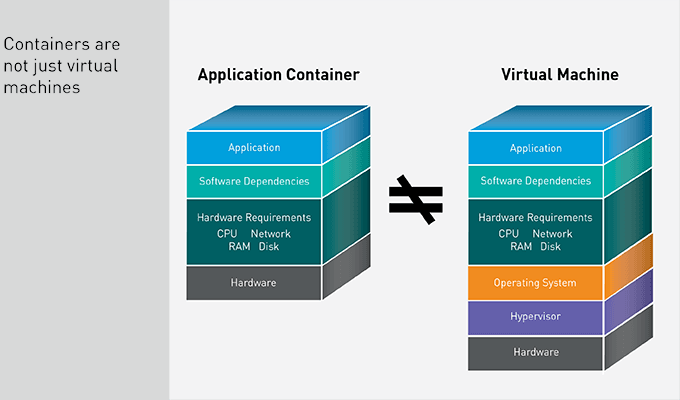
How Containers and Virtual Machines Differ
You might be wondering how using containers to develop an application differs from running the application in a virtual machine.
An application container is similar to, but not the same as, a virtual machine. A container is a package of the application and its dependencies. It will run on any compatible OS and hardware. Containers are designed to be streamlined application packages and nothing else. In the case of the example, the containers were streamlined down to microservices, so that each container is as lean and efficient as possible.
A virtual machine, on the other hand, includes a complete copy of an operating system, along with any applications and software dependencies running on it. In addition, a virtual machine requires a hypervisor layer to talk to the host server. A VM can be capable of performing more complex tasks, but requires a much larger package, plus more overhead in time and resources from a server.
An application container is a clean and effective package for running a single application as efficiently as possible.
Application Container Characteristics - Lightweight
Application containers consist of just an application, its software dependencies, and a small YAML file with its hardware requirements. They use the OS and infrastructure native to the system they are deployed onto. Therefore, a container is very lightweight when compared to other virtualization techniques, like VMs. They can be ported quickly to other environments and take just seconds to deploy, clone, or even relaunch in the case of a problem.
While a container can include more than one application, that is not generally considered a best practice. An application container is a streamlined environment, designed to run an application efficiently. Adding more applications adds complexity and potential conflict to the package. In some cases, tightly coupled applications may share a container. In the vast majority of cases, however, an application will have its own specialized container.

Containers Are Scalable
Since a container only includes an application and its dependencies, it has a very small footprint on the server. Because of this small size, several copies of a container can be launched on each server.
A higher application density leads to more efficient processing, as there are more copies of the application to distribute the workload.
Availability of the app is also greatly improved. The loss of a single container will not affect the overall function of the service, when there are several others to pick up the lost production.

Containers Are Portable
The small size of an application container makes it quick to move between servers, up to a cloud, or to mirror to another cluster. In addition, a container is completely self-sufficient and has all of the resources that the application needs to run.
When moving a container, it can just be dropped onto its new home and launched in a plug-and-play fashion. You do not need to test for compatibility or load additional software.
The containerized app can even run directly off of an instance in the cloud, giving you absolute flexibility over availability and the run-time environment.

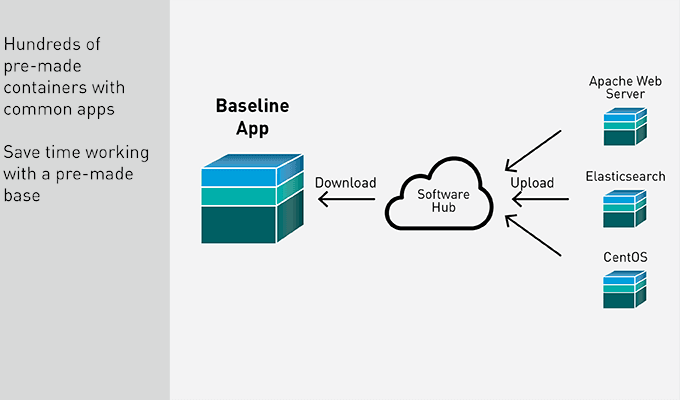
Containers Have an Ecosystem
The application container ecosystem is very large and diverse. Thousands of containerized applications are available on hubs to use as templates or foundations for proprietary apps. A simple container with Apache Web Server can be downloaded, pre-built, saving the development time and resources needed to create common services over and over.
Containers Help with Secure Multi-Tenancy
Because each application container creates an isolated environment for its application, the resources allocated to it are the entire machine. Other copies of the same container are "unaware" of each other.
As a result, it’s easy to have multiple different applications on the same server, all running simultaneously. Each application uses the resources assigned to it. There are no concerns about an application taking resources from another application and causing it to crash. When an application completes its work, resources are released back to the system.

Containers Offer Flexible Deployment
You know, now, that application containers are completely self-contained. Any application in a container runs in the same exact manner on any hardware. Because the container contains all dependencies, it doesn’t require the OS to supply any code. As long as the hardware can match the needs of the application, it will happily chug along no matter where you put it.

Container Are Easy to Maintain and Specialized for Microservices
When an application is containerized, it is saved as an image. As the application grows, and as changes are made, these changes are saved as a new image on top of the original one. Therefore, any time you need to push or pull an upgrade of a containerized application, all you need to move and install is the new image. You do not need the entire container each time.
Containers are a highly specialized runtime environment, designed to run a single application as efficiently as possible. Because of this specialization, they are perfectly designed to break up large applications into microservices.
Each microservice can run in its container when called upon, then release the resources back to the system when it is done. You can also define a different number of clones for each container, based on the use of each service, allowing for more copies of services that are used more frequently in your app.

What Containers Are NOT – Persistent or Stateful
When a container is shut down, either intentionally or due to some failure, everything in the container goes down with it. You can save out results as part of your application, but other progress and data, like logs, are lost. Each time you need to use the application, or spin up a new copy, it starts from a new beginning state. The state of the application cannot be saved and built upon with a new iteration.

What Containers Are NOT – Data-Aware
A container does not know where its data comes from, nor where it is going. The container is completely enclosed in its environment, and cannot see data sources for work or storage. External data can be accessed, and results from work can be saved out of the container environment, but the container has no idea what or where that data is.
Therefore, the app in the container cannot take advantage of data locality to make sure the work and data are on the same node. This may result in extra movement of data and reduce the efficiency of the service in the container.

What Containers Are NOT – Environment-Aware
Containers are not aware that the hardware that is provisioned to it is the entire server. This is helpful in that the containerized application is protected, but this also means that the application is not aware of, nor can it take advantage of, common services for enterprise applications, like networking with other apps, scheduling, distribution, and load balancing.

Container Summary
You have seen how application containers speed up the pipeline from production to delivery. They solve the problem of having an app working reliably in different environments, making development processes much more efficient and flexible.
Breaking up large applications into microservices and putting them into containers provides fast and flexible services that can quickly be deployed and moved between systems.
Containers are not a stand-alone solution, however, and have a few inherent limitations.

Using Kubernetes to Manage Containers and Cluster Resources
This section discusses how Kubernetes manages containers and resources.
Kubernetes is an environment that automates the orchestration of application containers. What does "Kubernetes automated orchestration" cover? It covers deployment, scaling, management, monitoring, and upgrades of individual, containerized microservices. Kubernetes takes care of all of the maintenance and tools around running application containers, so you can focus on application functionality.

Application Deployment
Deploying an application with Kubernetes requires just a single command. In the background, Kubernetes creates the runtime environment, requests the needed resources, handles the launch of the services, and provides each with an IP address. It also scales the containers across the cluster until each service is deployed to the level requested and maintains these levels 24/7.
Application Scaling
You decide how many clones of each service are needed. Because the services are containerized, you can set different levels for different parts of the app. When you first deploy, you calculate some starting numbers for each service. Kubernetes makes sure each service is running the correct number of copies. If there are too few, it will launch more. If there are too many, it will kill a few until the correct number are running.
Application Scale
Suppose you determine that there are too many copies of a service running and they are sitting dormant, or that application usage has increased and you need more copies to handle the load. You can change the settings on the deployment file, redeploy, and Kubernetes will update the number of each running service to meet the new requirements.

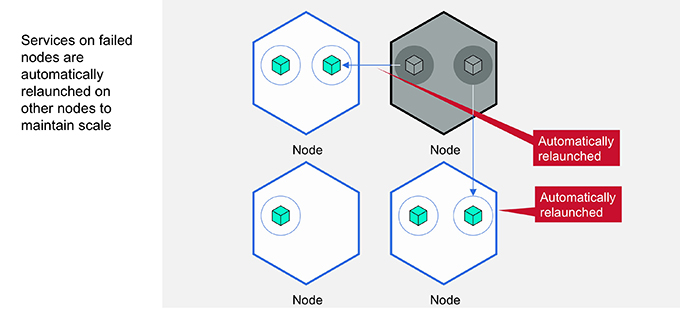
High Availability
Kubernetes watches how many copies of each service are up. If a container has a failure and goes down, Kubernetes launches a new copy. Kubernetes continually verifies that the number of each service on the system matches what was requested.

If an entire server goes down, Kubernetes redeploys the missing containers on other nodes, again until the number of services running matches the defined limits. You can rest assured that your app will achieve the required six nines of availability, as long as your data center is active.
Load Balancing
Kubernetes continuously monitors the usage of containers across nodes, verifying that the work is evenly distributed. If it finds an underused container or resource, it moves work to that resource, and may even move copies of a container to underused hardware.

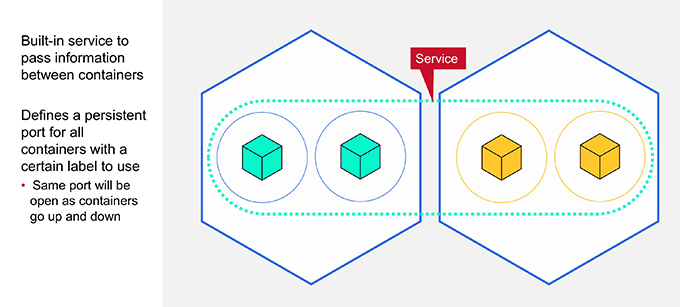
Communication
When applications are broken into microservices, the individual services need to talk to each other, in order to pass along client information. Kubernetes creates a service within itself to enable the different microservices to communicate. This communication service determines which containers can use it, based on labels on the container, and then defines a port that can be used by any container with that label.
As a service reads data from a wearable device on a customer, it will pass that data to the other services in the app that will stream the data, authenticate it with the health-care provider, and so on. Each instance of any service can use the same port to communicate with the other microservices in the app or any other services on the cluster that it needs.
The communication service in Kubernetes is persistent, independent of the services that use it. If a container goes down or a new container is spun up, the service will continue to be available at its port to any application with the correct label.
Multi-Tenancy
Let's consider the example of a health-monitoring application, serving thousands of users, sending data to a variety of health-care providers. With Kubernetes, the services could be divided up by health-care provider. Each provider could offer a differing number of services, based on usage, or could even provide variations on a service to a client, based on that client's particular needs.
For example, say that this application spins up three copies of the app for users of Mega-Health, but provides four copies to Health R Us because they have a larger customer base. In addition, Health R Us uses a communication protocol different from Mega-Health – so, a separate microservice is used to connect to their system.

Rolling Upgrades
When an application update is ready to roll out, the Kubernetes deployment file needs to be updated with the new information.
Kubernetes will gradually kill existing containers with the current version of the app and spin up new containers with the updated version, until all containers for that service are running the new version.

Rolling Downgrades
If there is a problem along the way, you can roll back the upgrade with a single command. Kubernetes will gradually kill containers with the new 2.0 version of the app and replace them with new instances of the older 1.0 version.
This third section provides an overview of Kubernetes architecture.
Kubernetes Architecture
Here you can see the standard architecture for running application containers with Kubernetes.

Kubernetes Object
An object in Kubernetes is anything that persists in the system, such as Pods, deployment records like ReplicationControllers, ReplicaSets, and Deployment controllers. Objects are used to define the desired state of the Kubernetes system.
Pods define what is to be on the system; deployments define parameters of the Pods, such as how many copies; and services define their connections. When objects are created, Kubernetes will ensure that the objects persist, and the system matches what is defined by the objects.

Kubernetes Pod
A Pod is the basic unit of organization in Kubernetes. A Pod will contain one or more containers, all of which share storage, network, and deployment specifications. Everything in a Pod will be deployed together, at the same time, in the same location, and will share a schedule along with the deployment parameters.
A Pod can contain more than one container, but in most practical applications, each Pod contains just a single container. Similar to the container itself, a Pod is a specialized environment. Each Pod has its own unique specifications, and those are usually optimized for the container in the Pod. Tightly coupled service containers that all perform a similar function, such as file locators or controllers, may share a Pod, but in most cases a single container keeps its environment optimized for the service it runs.
If you do have multiple containers within a single Pod, they share an IP address that they can use to communicate outside of the Pod, and they can see each other through localhost.

Kubernetes Name
Each object in Kubernetes is given a Name. The name of each object is provided to Kubernetes in the deployment record. Object names need to be unique within a namespace, but can be reused across separate namespaces in the system. If an object is removed from the system, the name can freely be used by another object.

Kubernetes Name Example
For example, let’s say you have a Pod that contains AwesomeApp. You want 3 instances of the Pod, so you name the Pod objects AwesomeApp1, AwesomeApp2, and AwesomeApp3. You decide that you want another copy, so you spin up a new instance of the Pod. Since it is in the same namespace as the other instances, you name it AwesomeApp4. Something happens along the line, and service AwesomeApp2 fails. Kubernetes kills the Pod that contains AwesomeApp2 and spins up a new copy. The name AwesomeApp2 is free to use now, since there is no object in the namespace with that name.

If you create another namespace in the system, you are free to use the names AwesomeApp1, AwesomeApp2, and AwesomeApp3 again in this space.

Kubernetes UID
The UID is a unique, internal identifier for each object in the system. The UID is defined by Kubernetes when the object is created and is used by the system to differentiate between clones of the same object.
For example, say you have a Pod that contains AwesomeApp. You want 3 instances of the Pod, so let’s say Kubernetes assigns them the UIDs 001, 002, and 003. If you make a new namespace and deploy 3 new Pods into that space, each new Pod will be given its own unique UID. The UID of each object must be unique on the system, even across namespaces.

Kubernetes Label
Labels are key-value pairs used to identify and describe objects, such as "version:1.1" or "cluster:sf". An object can have as many labels as you want, but cannot have more than one of the same key.
Labels are not used by the Kubernetes system, but provide a way for users to organize and map the objects in the system. For example, you can use them to perform an action on all Pods with the label "version:1.1" or a different action on all Pods with the label "cluster:tokyo".

Kubernetes ReplicaSet (ReplicationController)
ReplicaSets and ReplicationControllers are used to ensure that the correct number of Pods are running. The ReplicaSet defines what Pods are in it and how many copies of the Pods are to exist across the system. The desired number of Pods in the system can easily be scaled up or down by updating the ReplicaSet. Kubernetes then updates the number of Pods on the system to match the new specifications.
ReplicaSets define the Pods in it by the container image and one or more labels. Therefore, a different ReplicaSet can be made for different uses of the same container. For example, you can decide to have 3 copies of a container on your cluster in San Francisco, but only two copies of the same container on the Tokyo cluster. Alternately, you could have a ReplicaSet for our San Francisco cluster running version 1.1 of a service, while the Tokyo copies run version 1.2 of the same service.
ReplicaSets allow you to customize the number and types of services for your app, running across the environment.
ReplicaSet recently replaced the ReplicationController. Both perform the same function in a Kubernetes system.

Kubernetes Deployment Controller
The Deployment Controller defines the state of Deployment Objects, like Pods and ReplicaSets. In the example of deploying the health care app in a Kubernetes environment, we commonly referred to the state of the system being updated to match a defined state. Deployments are the object used to define and maintain the state of the system. Deployments are used to create and deploy, scale, monitor, roll back, and otherwise manage the state of Pods and ReplicaSets on the system.

Kubernetes Namespace
Namespaces are useful in multi-tenant systems, to divide resources among different users of the system. Similar Pods can be deployed in different namespaces with access restrictions to different user groups of the system, each providing unique specifications for that group.

Kubernetes Service
When you launch a container, it is given an IP address to communicate in and out. This is fine for the life of the container, but each container has its own IP address, and the life cycle of any given container is not consistent.
Kubernetes opens a port for application containers to see all other apps in the system. This port will remain open and consistent, even as instances of the containers are started and stopped. Therefore, communication between your application and other services on the system remains as long as your system is running.

Kubernetes Volume
Kubernetes Volumes solve the problem containers have with persistent data storage, at least to a point. A volume in Kubernetes is associated with the Pod, not the container within the Pod. Therefore, a container can fail and be relaunched, and the Volume will persist. The relaunched container can pick up where the failed one left off. If the Pod is killed, however, the Volume will be removed with it.

Kubernetes Architecture Summary
We’ve seen how application containers make the development pipeline faster and provide a specialized environment for apps to run more efficiently and consistently across systems.
We’ve also seen how Kubernetes orchestrates the use of containers at the enterprise level. With just a simple deployment file, and an occasional command, Kubernetes manages the deployment, scale, partitioning, distribution, and availability of containerized applications.

This section discusses how Kubernetes and Containers work on MapR.
You’re almost done with your introduction to using application containers and Kubernetes. The last part of your journey is to see how to put this all together in a real-world, enterprise environment.
Application Container Example
Throughout this Kubernetes blog series, we’ve used a fictional health care app to demonstrate how application containers and Kubernetes can be used in an enterprise environment. Let’s now take a look at a couple of different ways you can use the tools in the MapR Data Platform to deploy and manage such an app on a single platform and take advantage of unique features available with MapR.

MapR Solution: On-Premises
The scenario in this blog series involves streaming data to a health provider cluster for processing. In this example, the solution means processing the IoT data in an on-premises cluster.
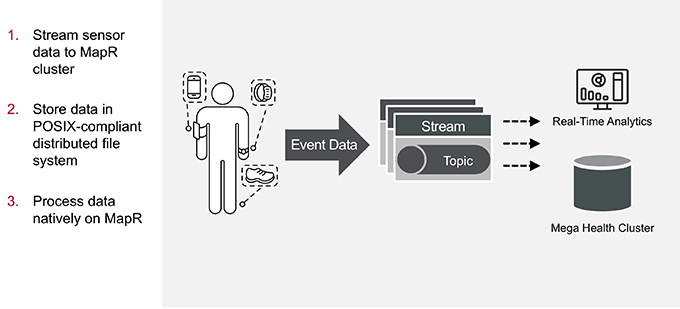
Stream Sensor Data to MapR Cluster
The data is created by a wearable device. An app on that device uses the MapR Event Store service to stream the data to on-premises storage at the customer’s health care system.

Store Data in POSIX-Compliant Distributed File System
The IoT data is streamed directly into the MapR XD POSIX-compliant distributed file and object store and saved in their native JSON, CSV, or Parquet format.

Process Data Natively on MapR
Using both files saved in MapR XD and new live streaming, we can process the data with Spark to compare live information to legacy data saved in the system.
In addition, MapR XD allows for the different sources of data to be tiered, based on level of access, giving faster access to data that is used more frequently.
Kubernetes can spin up containerized machine learning apps on MapR to analyze the data natively as it streams in, all on the same cluster, saving the time of transforming the data before it is processed. In addition, MapR can scale the compute and storage independently. If more data is coming in, you can add more application containers on MapR to support the increased demand.

MapR Solution: Cloud
Alternatively, MapR provides an all cloud-based solution to the wearable health care app. In this solution, we containerize the MapR Data Platform and move it to the data, rather than bringing the data to the MapR cluster. This is vastly more efficient, as data can be processed where it is created, saving time and resources needed to move the data to the cluster.
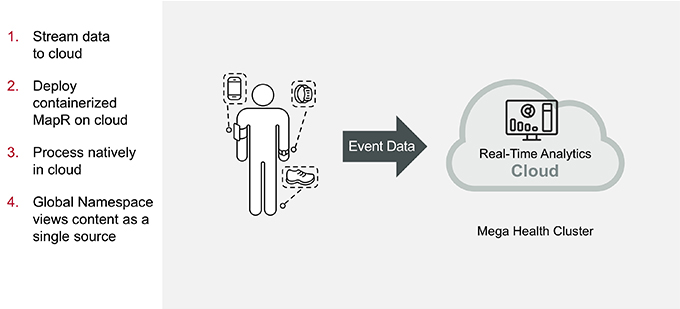
Stream Data to the Cloud
Wearable IoT devices create data and send it to the cloud, using the MapR Event Store for Apache Kafka services. A cloud provider close to the device reduces data transfer time.

Deploy Containerized MapR on Cloud
The MapR Data Platform is spun up in a container in the same cloud environment. The MapR Data Platform is broken into microservices, and the cluster can be spun up in just seconds. The MapR Event Store ingests the data into MapR XD on the cloud.
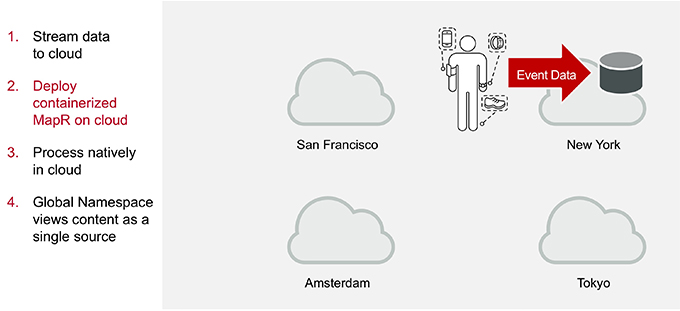
As clients in other areas create data on their wearable devices, MapR Event Store sends that data to cloud platforms hosted nearby. Containerized MapR clusters are spun up in those cloud environments as well, ingesting the data into MapR XD.
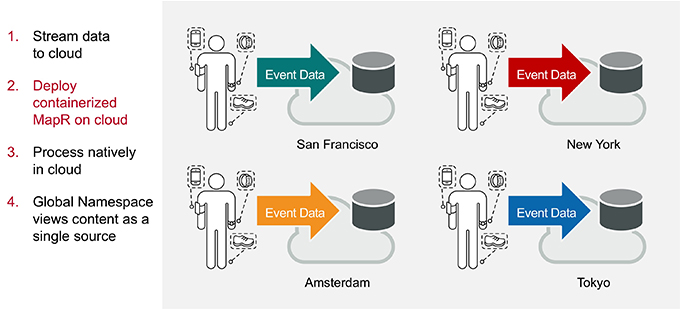
Process Natively in the Cloud
Spark processes the data close to where it was created, greatly reducing time and resources needed to move the data.

Global Namespace Views Content as a Single Source
The MapR Global Namespace allows all of this data to be processed at its local center, but viewed together as though they are coming from a single cluster, without the need to move any data between clouds or to on-premises storage.

MapR Data Platform Components
The following components of the MapR Data Platform can be used to make our health care app example functional, using application containers and Kubernetes.
- MapR Data Platform
- MapR Event Store for Apache Kafka
- MapR Distributed File and Object Store (MapR XD)
- Cloud Integration
- Global Namespace
- Live Data Processing
MapR Data Platform
The MapR Data Platform is a single, complete platform that supports enterprise-level data storage and processing needs.
Just as containers provide a self-contained environment for an app to run as efficiently as possible, the MapR Data Platform provides a single environment for streaming, ingesting, processing, and storing data from the edge, IoT devices, the cloud, on-premises, or any combination of data sources and types.
Just as Kubernetes handles all of the orchestration and maintenance of application containers, the MapR Data Platform handles all of the orchestration, distribution, scale, connectivity, replication, security, and high availability of your data and processing. MapR will take care of the maintenance, and your team can focus on the results.

MapR Event Store for Apache Kafka
MapR Event Store for Apache Kafka provides a platform for streaming data live from IoT devices. With MapR, you can stream data at an enterprise level, easily handling data from all of your customer's wearable devices.

MapR XD
MapR XD is a POSIX-compliant distributed file and object store. This allows you to directly ingest data from IoT devices in their native JSON, CSV, or Parquet formats, then directly query this data with Apache Drill, without spending any time or resources processing the data. You can also include large binary files like images, audio, or video for something like a security app that monitors a streaming CCTV feed. All of your data can be processed as it is streaming and gains the high availability, security, and replication advantages of a MapR cluster.

MapR Data Storage Solutions: Cloud Integration
MapR natively supports data storage and application containers in all major cloud providers.
The IoT data from your customer devices can be streamed to a cloud storage environment. From there, it can be accessed for processing from an on-premises cluster or even processed directly, using containers that are deployed in the same, or a different, cloud.

MapR Data Storage Solutions: Global Namespace
MapR provides a global namespace for all these different data sources used on the platform. This global namespace allows all data sources that are used by the application containers on your cluster to be seen as coming from a single source. Therefore, data does not have to be moved or copied, saving valuable time and resources. In addition, live streaming data and data saved in the cloud or on-premises can all be processed together, without the need for any preprocessing or consolidation.

Live Data Processing
In our fictional application, we stream the data to on-premises storage at the customer’s health care system. MapR can spin up machine learning applications to analyze the data as it streams in, all on the same cluster, saving the time of copying or transferring the data. In addition, MapR can scale the compute and storage independently. If more data is coming in, just add more application containers to support the increased demand.

MapR Data Platform
All of these tools in the MapR Data Platform share the same high availability, security, and replication technology that is consistent across MapR, and with the global namespace available with MapR, containerized apps finally have a persistent data source that will remain throughout the lifetime of the cluster.

Editor’s Note: MapR products referenced are now part of the HPE Ezmeral Data Fabric.
Related
3 ways a data fabric enables a data-first approach
Mar 15, 2022A Functional Approach to Logging in Apache Spark
Feb 5, 2021
Getting Started with DataTaps in Kubernetes Pods
Jul 6, 2021