
Editor’s Note: MapR products and solutions sold prior to the acquisition of such assets by Hewlett Packard Enterprise Company in 2019 may have older product names and model numbers that differ from current solutions. For information about current offerings, which are now part of HPE Ezmeral Data Fabric, please visit https://www.hpe.com/us/en/software/ezmeral-data-fabric.html
At MapR, we distribute and support Apache Spark as part of the MapR Converged Data Platform. This tutorial will help you get started with running Spark application on the MapR Sandbox (now known as the Development Environment for HPE Ezmeral Data Fabric).
Prerequisites
HARDWARE REQUIREMENTS
- 8GB RAM, multi-core CPU
- 20GB minimum HDD space
- Internet access
SOFTWARE REQUIREMENTS
- A hypervisor. This example uses VMware Fusion 6.0.2 on OSX; however, other VMware products could be used instead. Additionally, VirtualBox can be used
- A virtual machine image for the MapR Sandbox. Spark comes pre-loaded with version 5.0 and later of the MapR Sandbox.
Starting up and Logging into the Sandbox
Install and fire up the Sandbox using the instructions here. Once you are able to log in to the web interface for the Sandbox, you are ready to start setting up Spark.
Logging in to the Command Line
Before you get started, you'll want to have the IP address handy for your Sandbox VM. See the screenshot below for an example of where to find that.
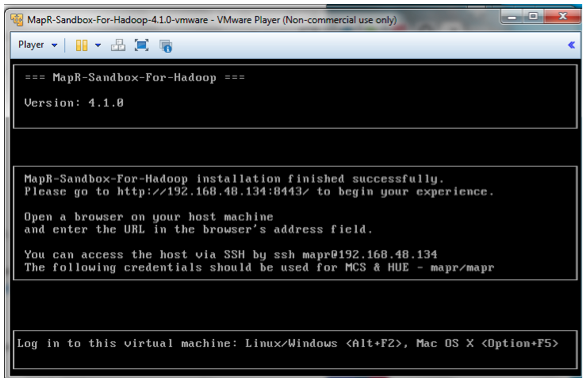
Next, use an SSH client such as Putty (Windows) or Terminal (Mac) to login. See below for an example:
use userid: user01 and password: mapr.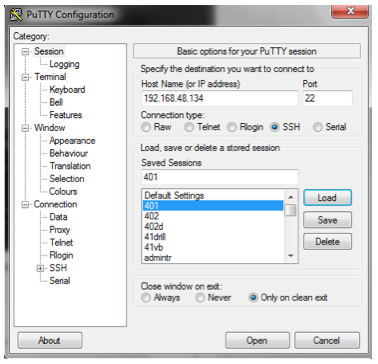
For VMWare use:
$ ssh user01@ipaddressFor Virtualbox use:
$ ssh user01@127.0.0.1 -p 2222
“How to” for a Spark Application
Next, we will look at how to write, compile, and run a Spark word count application on the MapR Sandbox. First, we will walk step by step through the following word count application in Java.
Example Word Count App in Java
You can download the complete Maven project Java and Scala code here.
Get a text-based dataset
First, let's grab a text-based dataset that will be used for counting the words. Today, we'll be using the freely available Alice In Wonderland text. Create a new folder:mkdir -p /mapr/demo.mapr.com/input
Pull down the text file:
wget -O /mapr/demo.mapr.com/input/alice.txt http://www.gutenberg.org/cache/epub/11/pg11.txt
Initializing a SparkContext
The first thing a Spark program has to do is create a SparkContext object, which represents a connection to a Spark cluster, and can be used to create RDDs, accumulators and broadcast variables on that cluster.
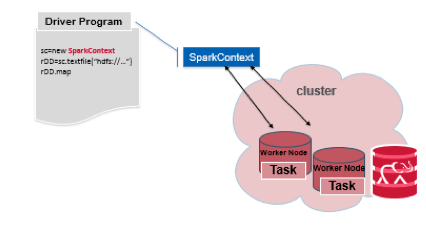
To create a SparkContext, you first need to create a SparkConf object to configure your application, as shown below:
// Create a Java Spark Context. SparkConf conf = new SparkConf().setAppName("JavaWordCount"); JavaSparkContext sc = new JavaSparkContext(conf);
Create an RDD from a file
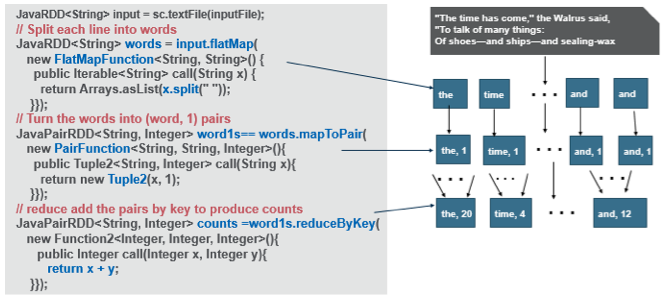
Spark’s primary abstraction is a distributed collection of items called a Resilient Distributed Dataset (RDD). RDDs can be created from Hadoop InputFormats (such as HDFS files) or by transforming other RDDs. The following code uses the SparkContext to define a base RDD from the file inputFile:
String inputFile = args[0]; JavaRDD <string>input = sc.textFile(inputFile);</string>
Transform input RDD with flatMap
To split the input text into separate words, we use the flatMap(func) RDD transformation, which returns a new RDD formed by passing each element of the source through a function. The String split function is applied to each line of text, returning an RDD of the words in the input RDD:
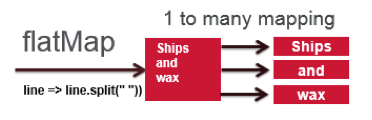
// map/split each line to multiple words **JavaRDD<String> words = input.flatMap(** new FlatMapFunction<String, String>() { public Iterable<String> call(String x) { return Arrays.asList(x.split(" ")); } } );
Transform words RDD with map
We use the map(func) to transform the words RDD into an RDD of (word, 1) key-value pairs:

JavaPairRDD<String, Integer> wordOnePairs = words.mapToPair( new PairFunction<String, String, Integer>() { public Tuple2<String, Integer> call(String x) { return new Tuple2(x, 1); } } );
Transform wordOnePairs RDD with reduceByKey
To count the number of times each word occurs, we combine the values (1) in the wordOnePairs with the same key (word) using reduceByKey(func), This transformation will return an RDD of (word, count) pairs where the values for each word are aggregated using the given reduce function func x+y:
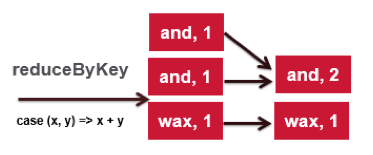
// reduce add the pairs by key to produce counts JavaPairRDD<String, Integer> counts = wordOnePairs.reduceByKey( new Function2<Integer, Integer, Integer>() { public Integer call(Integer x, Integer y) { return x + y; } } );
Output with RDD action saveAsTextFile
Finally, the RDD action saveAsTextFile(path) writes the elements of the dataset as a text file (or set of text files) in the outputFile directory.
String outputFile = args[1]; // Save the word count back out to a text file, causing evaluation. counts.saveAsTextFile(outputFile);
Example Word Count App in Scala
Here is the same example in Scala:

Building a Simple Application
Spark can be linked into applications in either Java, Scala, or Python. Maven is a popular package management tool for Java-based languages that lets you link to libraries in public repositories. In Java and Scala, you give your application a Maven dependency on the spark-core artifact. The current Spark version is 1.6.1 and the Maven coordinates are:
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.10</artifactId> <version>1.6.1</version> <scope>provided</scope> </dependency>
You can build with Maven using IDEs like Eclipse or NetBeans, and then copy the JAR file to your MapR Sandbox, or you can install Maven on your sandbox and build from the Linux command line.
You can use scp to copy your JAR file to the MapR Sandbox:
See below for an example of using scp from the command line:
use userid: user01 and password: mapr.
For VMWare use: $ scp nameoffile.jar user01@ipaddress:/user/user01/.
For Virtualbox use: $ scp -P 2222 nameoffile.jar user01@127.0.0.1:/user/user01/.
Running Your Application
First, find the version of Spark on the sandbox with ls /opt/mapr/spark/. Then you can use the spark commands in the /opt/mapr/spark/spark-version/bin directory.
You use the bin/spark-submit script to launch your application. This script takes care of setting up the classpath with Spark and its dependencies. Here is the spark-submit format:
./bin/spark-submit \ --class <main-class> --master <master-url> \ <application-jar> \ [application-arguments]
Here is the spark-submit command for our example, passing the input file and output directory as arguments to the main method of the JavaWordCount class:
/opt/mapr/spark/spark-1.6.1/bin/spark-submit --class example.wordcount.JavaWordCount --master yarn \ sparkwordcount-1.0.jar /user/user01/input/alice.txt /user/user01/output
Here is the spark-submit command to run the scala SparkWordCount:
/opt/mapr/spark/spark-1.6.1/bin/spark-submit --class SparkWordCount --master yarn \ sparkwordcount-1.0.jar /user/user01/input/alice.txt /user/user01/output
This concludes the Getting Started with Spark on the MapR Sandbox tutorial. You can download the example Maven project code here.
For more information:
Related
3 ways a data fabric enables a data-first approach
Mar 15, 2022A Functional Approach to Logging in Apache Spark
Feb 5, 2021
Getting Started with DataTaps in Kubernetes Pods
Jul 6, 2021