
Editor’s Note: MapR products and solutions sold prior to the acquisition of such assets by Hewlett Packard Enterprise Company in 2019, may have older product names and model numbers that differ from current solutions. For information about current offerings, which are now part of HPE Ezmeral Data Fabric, please visit https://www.hpe.com/us/en/software/data-fabric.html
Original Post Information:
"authorDisplayName": "Carol McDonald",
"publish": "2017-02-08T06:00:00.000Z",
"tags": "nosql,microservices"In this blog we will discuss some patterns that are often used in microservices applications that need to scale:
- Event Stream
- Event Sourcing
- Polyglot Persistence
- Memory Image
- Command Query Responsibility Separation
The Motivation
Uber, Gilt and others have moved from a monolithic to a microservices architecture because they needed to scale. A monolithic application puts all of its functionality into a single process, meaning that scaling requires replicating the whole application, which has limitations.
Sharing normalized tables in a clustered RDBMS does not scale well because distributed transactions and joins can cause concurrency bottlenecks.
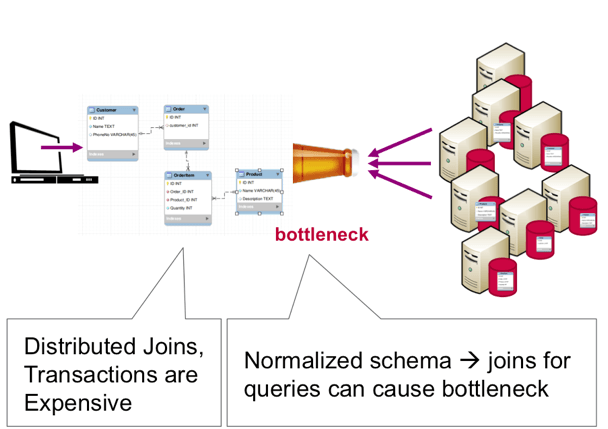
The microservice architectural style is an approach to developing an application as a suite of small independently deployable services built around specific business capabilities. A microservices approach is well aligned to a typical big data deployment. You can gain modularity, extensive parallelism and cost-effective scaling by deploying services across many commodity hardware servers. Microservices modularity facilitates independent updates/deployments, and helps to avoid single points of failure, which can help prevent large-scale outages.
Event Stream
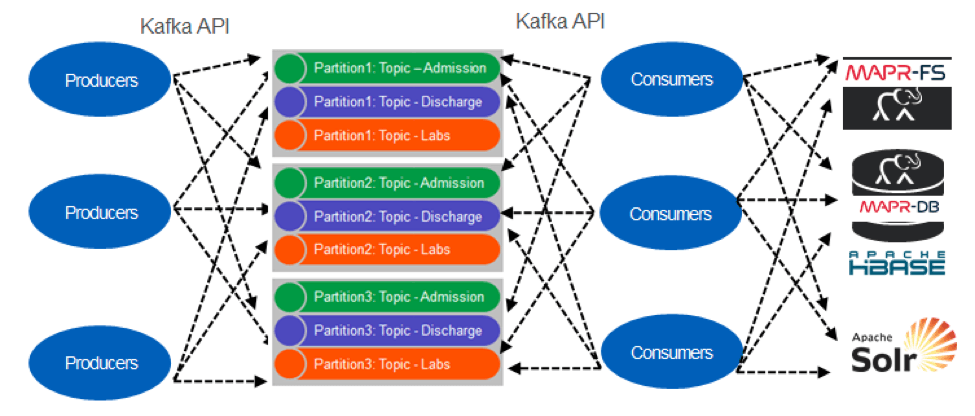
When moving from a monolithic to a microservices architecture a common architecture pattern is event sourcing using an append only event stream such as Kafka or MapR Event Store (which provides a Kafka 0.9 API). With MapR Event Store (or Kafka) events are grouped into logical collections of events called Topics. Topics are partitioned for parallel processing. You can think of a partitioned Topic like a queue, events are delivered in the order they are received.

Unlike a queue, events are persisted, even after they are delivered they remain on the partition, available to other consumers.

Older messages are automatically deleted based on the Stream’s time-to-live setting. If the setting is 0 then they will never be deleted.

Messages are not deleted from Topics when read, and topics can have multiple different consumers. This allows processing of the same messages by different consumers for different purposes. Pipelining is also possible where a consumer enriches an event and publishes it to another topic.
Event Sourcing
Event Sourcing is an architectural pattern in which the state of the application is determined by a sequence of events each of which is recorded in an append-only Event store or Stream. As an example, imagine that each “event” is an incremental update to an entry in a database. In this case, the state of a particular entry is simply the accumulation of events pertaining to that entry. In the example below the Stream persists the queue of all deposit and withdrawal events, and the database table persists the current account balances.
Which one of these, the Stream or the Database, makes a better system of record? The events in the Stream can be used to reconstruct the current account balances in the Database, but not the other way around. Database replication actually works by suppliers writing changes to a change log, and consumers applying the changes locally. Another well known example of this is a source code version control system.

With a Stream, events can be re-played to create a new view, index, cache, memory image, or materialized view of the data.

The Consumer simply reads the messages from the oldest to the latest to create a new View of the data.

There are several advantages for modeling application state with streams:
- Lineage: to ask how did BradA’s balance get so low?
- Auditing: it gives an audit trail, who deposited/withdrew from account id BradA? This is how accounting transactions work.
- Rewind: to see what the status of the accounts were last year.
- Integrity: can I trust the data hasn’t been tampered with?
- yes because Streams are immutable.
The Replication of MapR Event Store gives a powerful testing and debugging technique. A replica of a Stream can be used to replay a version of events for testing or debugging purposes.

Different databases and schemas for different needs
There are lots of databases out there. Each use different technologies depending on how the data is used, optimized for a type of write or read pattern: graph query, search, document. What if you need to have the same set of data for different databases, for different types of queries coming in? The Stream can act as the distribution point for multiple databases, each one providing a different read pattern. All changes to the application state are persisted to an event store, which is the system of record. The event store provides a rebuilding state by re-running the events in the stream.

Events funnel out to databases, which are consumers of the stream. Polyglot persistence provides different specialized materialized views.
CQRS
Command and Query Responsibility Segregation (CQRS) is a pattern that separates the read model and Queries from the write model and Commands often using event sourcing. Let’s look at how an online shopping application’s item rating functionality could be separated using the CQRS pattern. The functionality, shown below in a monolithic application, consists of users rating items they have bought, and browsing item ratings while shopping.
In the CQRS design shown below we isolate and separate the Rate Item write “command” from the Get Item Ratings read “query” using event sourcing. Rate Item events are published to a Stream. A handler process reads from the stream and persists a materialized view of the ratings for an item in a NoSQL document-style database.


NoSQL and De-normalization
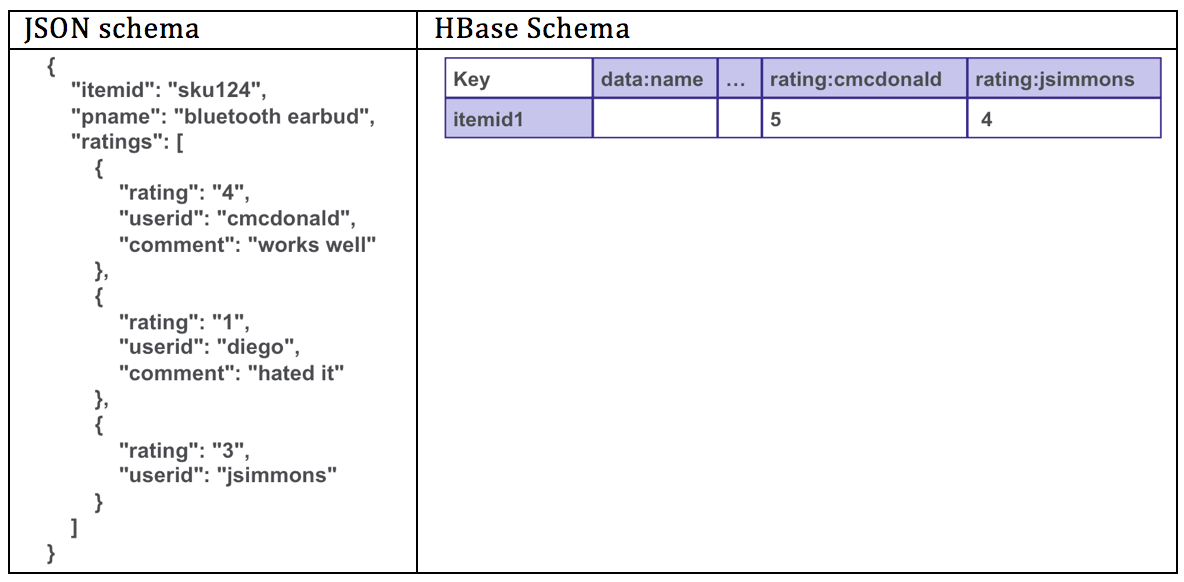
With MapR Database, a table is automatically partitioned across a cluster by key range, and each server is the source for a subset of a table. Grouping the data by key range provides for really fast read and writes by row key. With MapR Database you design your schema so that the data that is read together is stored together.

Often with MapR Database, you de-normalize or store in one table what would be multiple tables in a normalized relational database. If your entities exist in a one-to-many relationship, it’s possible to model it in MapR Database HBase as a single row or MapR Database JSON as a single document. In the example below, the item and related ratings are stored together and can be read together with a single get on the indexed row key. This makes the reads a lot faster than joining tables together.
Event Sourcing: New Uses of Data
An advantage of using an Event Stream for the rate item and other shopping related events is shown here. This design lets us use this data more broadly. Raw or enriched events can be stored in inexpensive storage such as MapR XD. Historical ratings data can be used to build a machine learning model for recommendations. Having a long retention time for data in the queue is also very useful. For example, that data could be processed to build a collection of shopping transaction histories stored in a data format such as Parquet that allows very efficient querying. Other processes might use historical data and streaming shopping related events with machine learning to predict shopping trends, to detect fraud, or to build a real-time display of where transactions are happening.

Fashion Retailer’s Event Driven Architecture
A major fashion retailer wanted to increase in-season agility and inventory discipline in order to react to demand changes and reduce markdowns. The Event driven solution architecture is shown below:

- Weather, world events, and logistical data is collected in real time via MapR Event Store, allowing for real time analysis of potential logistical impacts, and rerouting of inventory.
- Apache Spark is used for batch and streaming analytics processing, and machine learning for predicting supply chain disruptions, and product recommendations.
- Data is stored in MapR Database providing scalable, fast reads and writes. Apache Drill is used for interactive exploration and preprocessing of the data with a schema-free SQL query engine.
- ODBC with Drill provides support for existing BI tools.
- MapR’s Enterprise capabilities provide for global data center replication.
Summary
In this blog post, we discussed event driven microservice architecture using the following design patterns: Event Sourcing, Command Query Responsibility Separation, and Polyglot Persistence. All of the components of the architectures we discussed can run on the same cluster with the MapR Data Platform.

References and More Information
Related
3 ways a data fabric enables a data-first approach
Mar 15, 2022A Functional Approach to Logging in Apache Spark
Feb 5, 2021
Getting Started with DataTaps in Kubernetes Pods
Jul 6, 2021