Building Custom Docker Images for EMR Serverless
March 9, 2023EMR serverless is the latest addition from the AWS to offer out of box support for Elastic MapReduce paradigm with auto scaling and pay as you go model.
One often needs to build custom images in EMR serverless since the application uses specialized libraries that don't come with an EMR serverless base image. An explicit use case would be the requirements found with Delta Lake over S3 or specific Python modules, such as boto modules, database access libraries (i.e. pgcopy), etc. While there exists the option to have them installed at run time (i.e. when the image is running in a container and a custom script is used to install it), in production settings, it is encouraged to prebundle all the required libraries, modules, and jars. Dynamic installations are typically discouraged due to access permissions and internet connectivity issues.
Further, getting prebundled assembly jars with all the dependencies is feasible in certain programming such as a scala/java, but with widely used Python the concept of creating assembly modules is missing. To address this, one option for all Python based modules/libraries that are required by the application code is to be prebundle them into custom images. We are going to show you a fairly quick and easy way to do this for AWS.
In this article we take two scenarios, one where the application expects the data jars to be in specific location for its execution as in case of Delta Lake and another where we install specific Python modules using pip install both of which are bundled into a custom docker image that the EMR Serverless uses.
Delta Lake (https://delta.io) is an open-source storage framework that enables building a lake house architecture. One of the important features supported by Delta Lake is the checkpoint management for batch/streaming jobs that uses AWS S3 as a data lake. The most common approach in using Delta Lake is via the command line running the spark-submit command - something like "sparkSubmitParameters": "--packages io.delta:delta-core_2.12:1.2.1". This dynamically pulls the Delta Lake (via maven project) when the spark jobs run (ref. https://docs.delta.io/latest/quick-start.html#pyspark-shell ). The other approach is to use pip install delta-spark==2.2.0 when Python is used. However, both these approaches in production might not be possible, as they require an active internet connection and necessary permissions on the production machine to download/install a library at run time in the EMR Serverless application.
Another use case is the installation of all custom libraries (in the form of jars etc.) used by the code. In this article, we will provide you with step-by-step instructions on how to build custom images, addressing both of the above scenarios using the ECR to register our Docker image. We will also show you how to use the Docker image in the EMR Serverless.
Step 1: Pre-requisites to build a custom Docker image
Step 2: Identify the base EMR Serverless Docker image, packages/jars that need to be installed/downloaded, and prepare the custom Docker image.
Step 3: Push the Docker image to the ECR
Step 4: Create the EMR Serverless applications by using one of the following approaches:
(a) Via the AWS command line (AWS CLI)
(b) Via EMR Serverless settings in the EMR management console
Step 1: Prerequisites to build a custom Docker image:
The latest version of the Docker client
The latest version of AWS CLI
Verify the access to any dependent repository from where resources (modules, code etc) might be downloaded.
Step 2: Sample Docker file used to create custom EMR Serverless image:
# Refer AWS EMR documentation for the release version tag
FROM public.ecr.aws/emr-serverless/spark/emr-6.9.0:20221108
USER root
# Dependent JAR files
RUN curl -Ohttps://repo1.maven.org/maven2/io/delta/delta-core_2.12/2.2.0/delta-core_2.12-2.2.0.jar``
RUN curl -O https://repo1.maven.org/maven2/io/delta/delta-storage/2.2.0/delta-storage-2.2.0.jar
# The base emr-image sets WORKDIR to /home/hadoop, hence the JAR files will be downloaded under /home/hadoop.
# Then these jars will be copied to /usr/lib/spark/jars which was set as SPARK_HOME by EMR base image.
RUN cp /home/hadoop/delta-core_2.12–2.2.0.jar /usr/lib/spark/jars/\
RUN cp /home/hadoop/delta-storage-2.2.0.jar /usr/lib/spark/jars/
# EMRS will run the image as hadoop
USER hadoop:hadoop
Step 3: Pushing the Docker image to the Amazon Elastic Container Registry (AWS ECR):
Command to authenticate Docker to an AWS ECR public registry assuming region as us-east-1. As the EMR Serverless base Docker image is present in the ECR public registry, run the command shown below before building your customized Docker file.
aws ecr-public get-login-password — region us-east-1 — profile <profile_name_in_your_aws_credentials_file> | docker login — username AWS — password-stdin public.ecr.aws
Command to build Docker image:
docker build -t local_docker_image_name:tag -f <docker_file_name> .
Command to tag locally built Docker image in order to push to the AWS ECR private registry:
docker tag local_docker_image_name:tag aws_account_id.dkr.ecr.region.amazonaws.com*/docker_image_name:tag*
Command to authenticate Docker to an AWS ECR private registry assuming region as us-east-1. Run the command shown below before pushing the Docker image to AWS ECR private registry.
aws ecr get-login-password — region us-east-1 — profile <profile_name_in_your_aws_credentials_file> | docker login — username AWS — password-stdinaws_account_id.dkr.ecr.region.amazonaws.com``
Note:
1. When the --profile option is not provided, credentials will be picked from the profile name
2. Example content of ~/.aws/credentials file:
[default]\ aws_access_key_id =\ aws_secret_access_key =
[testprofile]\ aws_access_key_id=\ aws_secret_access_key=
Command to push Docker image to the AWS ECR private registry:
docker push aws_account_id.dkr.ecr.region.amazonaws.com*/docker_image_name:tag*
Step 4: EMR Serverless using the custom Docker image created:
There are two approaches for EMR Serverless to use the custom image created:
(a) via the AWS CLI
(b) Via EMR Serverless settings in the EMR management console
4a) Via the AWS CLI command to create simple EMR Serverless application using custom Docker image:
AWS CLI reference for EMR Serverless application management: https://docs.aws.amazon.com/cli/latest/reference/emr-serverless/index.html
aws — region
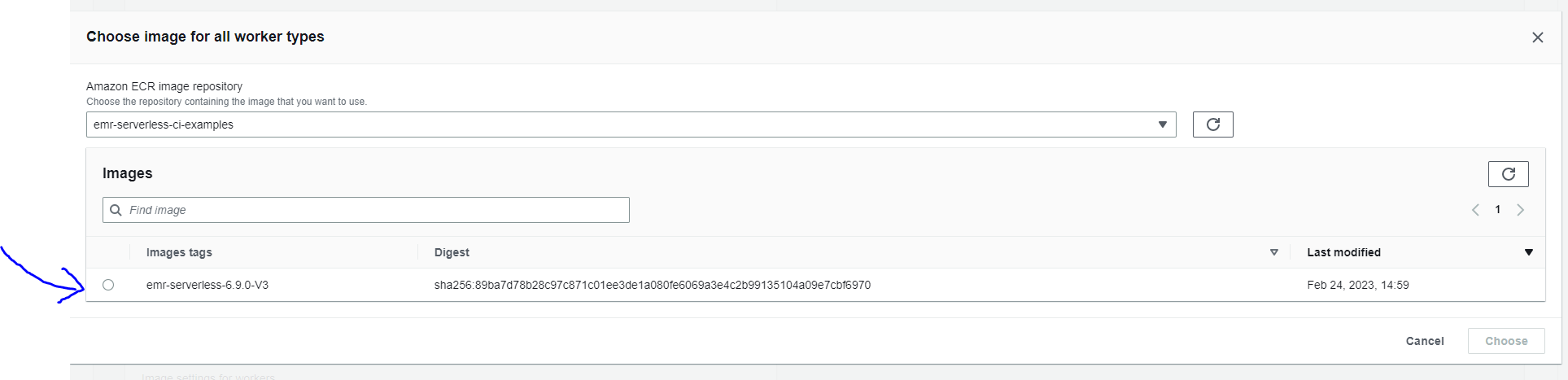
Note: Image URI can be copied from the AWS ECR registry.
4b) Via EMR Serverless settings in the EMR management console
EMR Serverless custom image settings section in the AWS EMR Serverless management console:
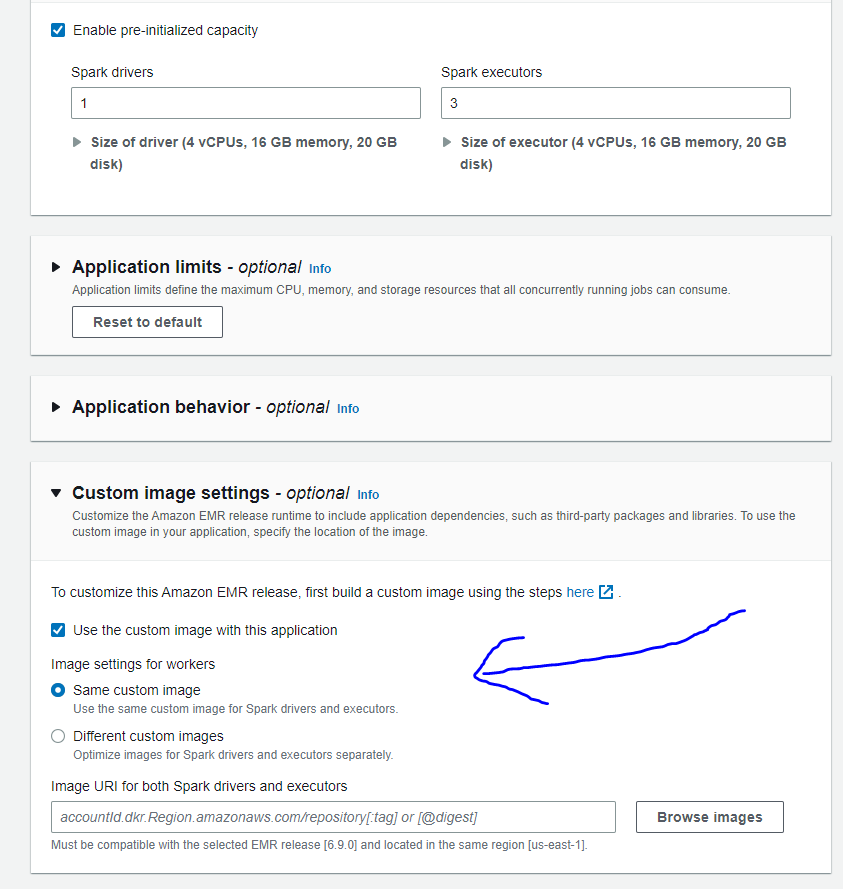
Browse and select custom EMR Serverless image from the AWS ECR private registry in the same region:
Summary:
This article provides the reader with mechanisms to build custom Docker image where custom libraries especially Python modules need to be bundled and used in EMR Serverless. We use two use cases with Python modules and Delta Lake libraries on how one can build this Docker image. This should help all developers using Python as their software language for EMR Serverless to pre-bundle the Python libraries for the production environment. If you found this blog post helpful, we recommend you read more on the topic by referencing the documentation below:
About the Authors:

D R Niranjan is a Senior software/Cloud application developer at HPE, experienced in developing software and cloud applications for HPE Servers and Storage systems. He is technically skilled in Python, Java, Scala, Spark programming, AWS, Dockers and Kubernetes, PgSQL/RDBMS. You can have a look at his LinkedIn profile here: https://www.linkedin.com/in/niranjan-d-r/

Sagar Nyamagouda holds a B.E(Information Science and Engineering) from BMS College of Engineering (BMSCE), Bengaluru and M.Tech in Software Systems from BITS Pilani. He is an experienced R&D Engineer working on Big Data Technologies and building AI/ML pipelines to give real time insights to customers. An AI/ML enthusiast, he is currently working with HPE enabling advanced insights for Data Services in HPE GreenLake Cloud Platform. LinkedIn Profile: www.linkedin.com/in/sagarny

A graduate from BITS Pilani, Pilani, Chirag is currently working as a cloud developer in HPE. He has over 6 years of experience in designing, developing, and implementing complex data processing pipelines. He is experienced in microservice architecture, big data tech stack like Apache Spark , Spark Streaming , SQL/NoSQL databases, Kafka, Core Java, Scala, and Python and has a good understanding of the AWS platform. His LinkedIn profile is https://www.linkedin.com/in/chiragtalreja29/

Chinmay currently works at HPE as a cloud engineer. He has expertise in various Big Data Processing technologies, including the building of ML/AI platforms, data engineering and processing (most recently related to Spark, AWS, SQL, etc.). Please view his LinkedIn profile here: https://www.linkedin.com/in/chinmay-chaturvedi-707886138

Kalapriya Kannan currently works with HPE on cloud enablement of storage analytics. She holds a Ph.D from IISc. She has authored around 60 peer reviewed international conference papers and over a 100 disclosure submissions for patent filing for which she has been granted 65 patents. Her interests are in the area of distributed and parallel systems and currently she is working in processing of big data for analytical insights. Her linkedIn profile: https://www.linkedin.com/in/kalapriya-kannan-0862b55b

Roopali has 19 years of work experience in systems software development in the areas of operating system, file system and cloud technologies. She has played a number of various roles, starting from developer to lead expert and product owner. In her current role, she is responsible for functional delivery and people management of Data Observability Analytics Project.