
Better Complex Event Processing at Scale Using a Microservices-based Streaming Architecture (Part 1)
November 3, 2020Editor’s Note: MapR products and solutions sold prior to the acquisition of such assets by Hewlett Packard Enterprise Company in 2019, may have older product names and model numbers that differ from current solutions. For information about current offerings, which are now part of HPE Ezmeral Data Fabric, please visit https://www.hpe.com/us/en/software/data-fabric.html
Original Post Information:
"authorDisplayName": "Mathieu Dumoulin",
"publish": "2017-01-09T06:00:00.000Z",
"tags": "machine-learning"A microservice-based streaming architecture combined with an open source rule engine makes real-time business rules easy
This post is intended as a detailed account of a project I have made to integrate an OSS business rules engine with a modern stream messaging system in the Kafka style. The goal of the project, better known as Complex Event Processing (CEP), is to enable real-time decisions on streaming data, such as in IoT use cases.
After much writing, I’ve decided to split the post into two parts. In the first part, I’ll focus on explaining what is CEP, why it is useful, and explain the architectural solution and why we feel this is a good idea for a lot of useful production use cases.
In the second post, I’ll show a concrete example based on a road traffic monitoring system and give as much detail as possible about how it was made.
So without further ado, on to part 1!
Overview
As of 2015, the worldwide enterprise application software market is worth around 150 billion USD, according to Gartner Inc. It’s a huge market where one of the most common types of application revolves around applying some kind of business logic to data generated from various aspects of the business.
These days, modern enterprise applications need to connect to ever more types of data sources, scale with the size of the data and the number of users, be reliable, and perform quickly. Long, custom application development cycles of one year or more are unappealing as business needs and conditions change, thus rendering the application obsolete before it is even put into production.
In very large, country-wide, regional or global organisations, or organisations with exceptional data use in industries like finance, healthcare or IT, the needs stay the same, but must be met using big data technologies. This opens up a whole new class of difficulties that have made the cost of developing enterprise applications at scale extremely expensive, and it puts up very high barriers in terms of IT infrastructure and know-how requirements.
So what is needed is a way to run business logic on data collected across a variety of sources, potentially at very large scales and ideally in real time, like an Internet of Things-type of application.
Understanding Complex Event Processing (CEP)
Complex event processing, or CEP for short, is not as complex at the name might suggest. Fundamentally, CEP is about applying business rules to streaming event data. Event data is simply data with a timestamp field. Examples of this kind of data might be log entries for a web server, receipts from purchases, or sensor data, all of which can be viewed as a constant stream of events. Applying rules on this streaming data enable useful actions to be taken in response.
Here is an example for a smart home which has sensors at the doors, a smart WiFi router, and room movement detectors. With CEP streaming all the data into a home server, a user could make some rules like the following:
- If it's daytime and the door is closed and no phones are connected to the WiFi, set the house to “nobody home”
- If nobody is home and the door is unlocked, then lock the door and turn on the alarm
- If nobody is home and it's winter, lower the house temperature to 18C
- If nobody is home and it's summer, turn off the air conditioning
- If nobody is home and the door is unlocked by a family member, then turn off the alarm and set the house to “people are home'”
Having a bunch of simple rules like these will quickly add up to a very smart home indeed. In fact, such capabilities are already available for purchase in several competing smart home "hub" devices that use common protocols to read information from compatible sensor devices around the house and then push actions back when some rules are met.
This kind of example can be easily ported to many other domains. For example, in retail, purchase histories and beacons could be used to generate personalized, location-sensitive messages or coupons. In industrial applications, many machine tools could be operated and maintained more easily using a combination of relatively simple logical rules such as, "If the red button of this machine is lit, then it must be stopped."
CEP Rule-engine vs. Hand Coding
The engineers reading this so far are probably not very impressed, as streaming events apply simple rules. A smart home use case such as the one described above could easily (well, to a point) be handled entirely by hand coding using Python and running on a old repurposed PC or even a Raspberry Pi.
What are the parts of this type of project?
- Data ingest
- Defining rules on the data
- Executing the rules
- Taking action from rules when the conditions are met.
Good software architecture calls for trying to make the parts most likely to change easy to change, at the cost of making other parts more difficult. What is the part most likely to change? Data ingest will only change when a new sensor is added, but a given sensor's data will not change suddenly. Executing rules in the abstract is always the same; what varies is the rule itself. Taking an action, once coded and working, doesn't really change, but it should be easy to add new actions over time.
When the use cases starts to scale, and the number of rules increases, the rules processing engine efficiency starts to become important. Also, when the number of rules increases, making rules easy to edit is not just a "nice to have" feature, but a core requirement.
Another often used argument is the separation of business logic from the SDLC. Business needs to move faster than software development. By using a rules engine, the two streams can move independently for the most part.
CEP is “Baked Into” IoT Applications
CEP is almost a requirement for any kind of IoT application such as smart homes, smart agriculture, Industry 4.0, or telecom data. It's a requirement in the sense that putting aside how the feature is implemented, IoT needs to apply rules to streaming event data. This is true whether it's at small scale in a single private home or at large scale across several factories scattered across the globe.
An ideal design, based on what we just described, argues against a hand- coded solution and uses what is known as a "business rules processing engine." There are several which exist in the open source world, the most well known being Drools.
Drools: Open Source Business Rules Engine
Drools is an open source project developed under the JBoss umbrella of open source projects. It is a project with a long history of active development and it’s currently at version 6.5.0.Final with version 7 in beta. It is reasonably modern as it supports Java 8's vastly improved API.
Drools has all the characteristics we are looking for in terms of a rules engine, with a well-defined DSL to define rules, and a rules engine based on the RETE algorithm that is well optimized and very fast. In addition, the documentation is thorough and there are a good number of books available to learn all about how to use this powerful framework.
Finally, Drools comes with a GUI called Workbench that allows us to create and edit rules visually without any need for coding. This is a killer feature that puts the power of rules within the reach of business analysis.

Streaming Architecture Enables CEP for Big Data
A streaming architecture is a critical component to CEP. The entire point of CEP is to make decisions in (near) real-time over streaming data, as opposed to taking actions from analysis of historical data done as a batch process.
CEP is all about agility and getting potentially complex behavior arising from the interaction of lots of simple rules all getting applied over the data, in memory in real time. A streaming, microservices-based architecture is becoming a standard for modern, large-scale architecture.
I also presented a talk on this topic at Strata Singapore 2016.Please go take a look on Slideshare.
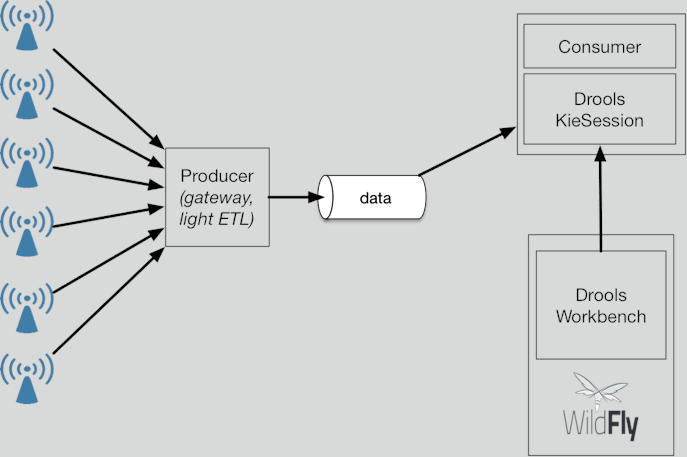
In general terms, the solution will look like the graph above. Data sources, such as sensors, cash registers, or logs, are collected and with light ETL, are added to a stream. The data is then consumed by a program which simply passes the data as facts into the Drools KieSession. This is the in-memory workspace where the rule engine uses pattern matching to see what rules can fire based on the facts present in memory.
In our proposed architecture, the rules reside in the Drools Workbench, a GUI rule editor which also serves as version control and as a repository for the rules to be deployed to production.
The main benefit of this approach is to separate the process of maintaining the application itself completely independent from the process of editing rules that create value for the business. Engineers can be left with the clear task of making sure the system is performing well and is stable, while the business side can focus on the rules.

In the diagram above, we can see how this may look more concretely with an implementation using a MapR cluster. It would be equally valid to use a Kafka cluster in its place for this particular application, although that would result in less potential for new use cases and an increased burden of system administration. The reason for this is that a Kafka cluster is strictly limited to supporting streaming, whereas using a cluster that is converged allows for additional use cases, both operational or analytical, right there on the same cluster.
A key point here is the second arrow going back from the CEP Engine to the stream. It illustrates the important concept of using streams for input and output that is at the core of streaming architectures. That is also why Enterprise IT Systems is shown to get its data from the stream as well.
The flow of data looks like so:

Data flows from the data source to an Event Producer, which is just a stream producer or calls to a REST endpoint using the new Kafka REST Proxy. The REST proxy is also supported by MapR Event Store from MapR Ecosystem Pack 2.0.
The CEP Engine can read data off the stream, and gets its rules from the Drools Workbench. From a streaming architecture point of view, the Drools Workbench and the CEP Engine are a unit, a single microservice, so to speak, as they are entirely self-contained and don’t have any external dependencies.
As rules fire in the rules processing algorithm, some external actions will need to be taken. Those actions may be an insert or update of a table in a corporate DB, indexing to Elasticsearch to serve data to a Kibana dashboard, sending a notification. But instead of tightly coupling the systems together by making the call directly from the CEP Engine to the external system, we output the data from the CEP Engine back into another topic into the stream. Another microservice or application (like Cask.co or Streamsets) will handle that flow.
In Conclusion
Complex Event Processing has been around for quite a while, but is now finally coming into its own. On the hardware side, services with a lot of memory are much more commonplace. On the software side, it’s possible to create a useful, production-grade CEP system entirely out of OSS, without needing to resort to expensive, custom-coded streaming applications.
Combining a Kafka-style stream messaging system with Drools provides an organization with much needed agility in separating the very different tasks for creating and maintaining an enterprise streaming application and defining and editing business logic for real-time decisions.
In the next blog post, we will cover a concrete use case that puts all this into practice and will show how such a system can be implemented using nothing more than Java, a MapR cluster, and the Drools Workbench running on a Wildfly application server.
Related
3 ways a data fabric enables a data-first approach
Mar 15, 2022A Functional Approach to Logging in Apache Spark
Feb 5, 2021
Getting Started with DataTaps in Kubernetes Pods
Jul 6, 2021