
Accessing HPE Ezmeral Data Fabric Object Storage from Spring Boot S3 Micro Service deployed in K3s cluster
September 13, 2021Containers and microservices are transforming Edge and IoT platform use cases that can be deployed in small footprint Kubernetes clusters on edge nodes and persisting data at a central location. This data pipeline can be easily accessed by downstream complex analytics applications for further processing.
In this article, I will discuss how to access HPE Ezmeral Data Fabric Object Store (S3) using Spring Boot S3 Micro Service application deployed in a K3s cluster and perform basic S3 operations like upload, list, delete etc. The below diagram gives an overview of the architecture.
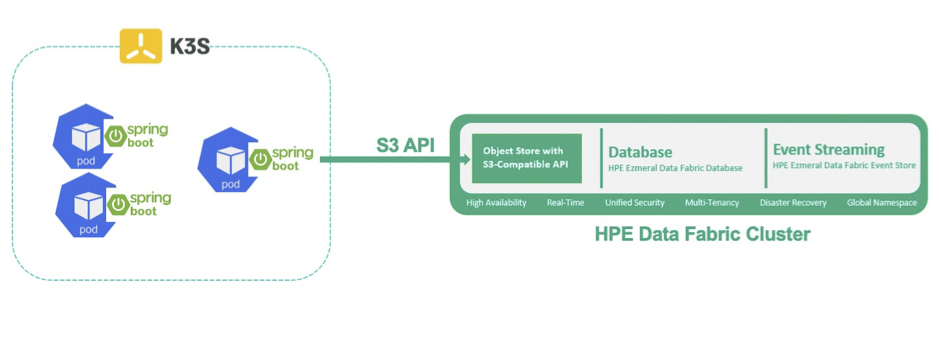
Figure 1: Architecture overview of Spring Boot S3 Micro Service on K3s with HPE Data Fabric Object Storage as the back end.
A brief description of the technology stack used is described in the sections below:
Data Fabric Object Storage
The Object Store with an S3-compatible API stores data generated through multiple data protocols, such as NFS, POSIX, S3, and HDFS. Data in the Object Store is accessible through S3 API requests. The Object Store manages all inbound S3 API requests to store data in or retrieve data from an HPE Ezmeral Data Fabric cluster. More details can be found here.
K3s
Lightweight Kubernetes, aka K3s, is easy to install and consumes half the memory, all in a binary of less than 100MB. It's great for edge and IoT use cases. More information on K3s can be found at Rancher site. Follow the steps as mentioned in QuickStart Guide for installation of the K3s cluster.
Spring Boot
Spring Boot is an open source Java-based framework used to create a micro Service. Many real world applications are written in Spring Boot for faster development and better maintainability. More information can be found at spring.io
Note: We can move the Spring Boot application to Quarkus with no change in code. Moving code to Quarkus will reduce the footprint of the Spring Boot application. More information can be found at Quarkus site
In this blog post, you'll checkout the existing Spring Boot application from GitHub, customise it and execute.
Application Prerequisites
1. The K3s cluster must be accessible. Note down the control plan node details. This information is required to deploy the Spring Boot application.
2. Access the HPE Data Fabric Object Store service UI running on port 9000. For example URL - https://FQDN:9000/. Note down the access key and secret key. It is advised to change the default values.
3. Java 11, Apache Maven 3.8+, Docker Client.
Build and Install Steps
1. Check out an existing Spring Boot application from GitHub.
2. Copy the ssl_usertruststore.p12 from the HPE Data Fabric cluster into certs folder under project directory. The ssl_usertruststore.p12 file is located at /opt/mapr/conf directory in cluster node. The password for p12 can be copied from “ssl.client.truststore.password” property value in /opt/mapr/conf/ssl-client.xml .
3. From the project directory, open resources/application.properties. Change the key values as per your environment.
4. Execute “mvn clean install” .
5. The distributable is available in target/df-s3-springboot-k3s-demo-1.0-SNAPSHOT.jar .
6. Edit the DockerFile located in project directory. The value of “-Djavax.net.ssl.trustStorePassword” must be same as the value of “ssl.client.truststore.password” obtained from Step 2.
Note: This value can be configured using config-map.yaml in K3s cluster.
7. Execute below docker commands to build docker image and push it to docker hub.
Note: Alternatively, we can use podman instead of docker to create images. More information on podman can be obtained from here.
docker build -f Dockerfile -t <Dockerhub user id>/df-s3-springboot-k3s-demo:latest . docker image ls docker login -u <Dockerhub user id> > enter password: <Dockerhub password> docker push <Dockerhub user id>/df-s3-springboot-k3s-demo:latest
8. Next, create below df-s3-springboot-k3s-demo.yaml file for deploying the executable in K3s cluster. A sample yaml file is given in the project directory. Please replace
apiVersion: v1 kind: Service metadata: name: df-s3-springboot-k3s-demo-service spec: selector: app: df-s3-springboot-k3s-demo ports: - protocol: TCP name: df-s3-springboot-k3s-demo port: 8000 targetPort: 8000 type: LoadBalancer --- apiVersion: apps/v1 kind: Deployment metadata: name: df-s3-springboot-k3s-demo spec: selector: matchLabels: app: df-s3-springboot-k3s-demo replicas: 1 template: metadata: labels: app: df-s3-springboot-k3s-demo spec: containers: - name: df-s3-springboot-k3s-demo image: <Dockerhub userid>/df-s3-springboot-k3s-demo:latest imagePullPolicy: Always ports: - containerPort: 8000
9. Before deploying it in the Kubernetes cluster, validate the docker or podman image by running the image.
docker run -p 8000:8000 <Dockerhub userid>/df-s3-springboot-k3s-demo
http://localhost:8000/swagger-ui.hmtl
Deploying in K3s cluster
1. Log into the control plane node of the K3s cluster. Create/Copy the df-s3-springboot-k3s-demo.yaml to the node.
2. Execute “kubectl apply -f df-s3-springboot-k3s-demo.yaml”. If required, you can specify the namespace option.
3. Check the pod creation status by using the command “kubectl get pods -l app=df-s3-springboot-k3s-demo -o wide”.
4. Verify if the services are properly deployed by using the command “kubectl get service df-s3-springboot-k3s-demo-service”.
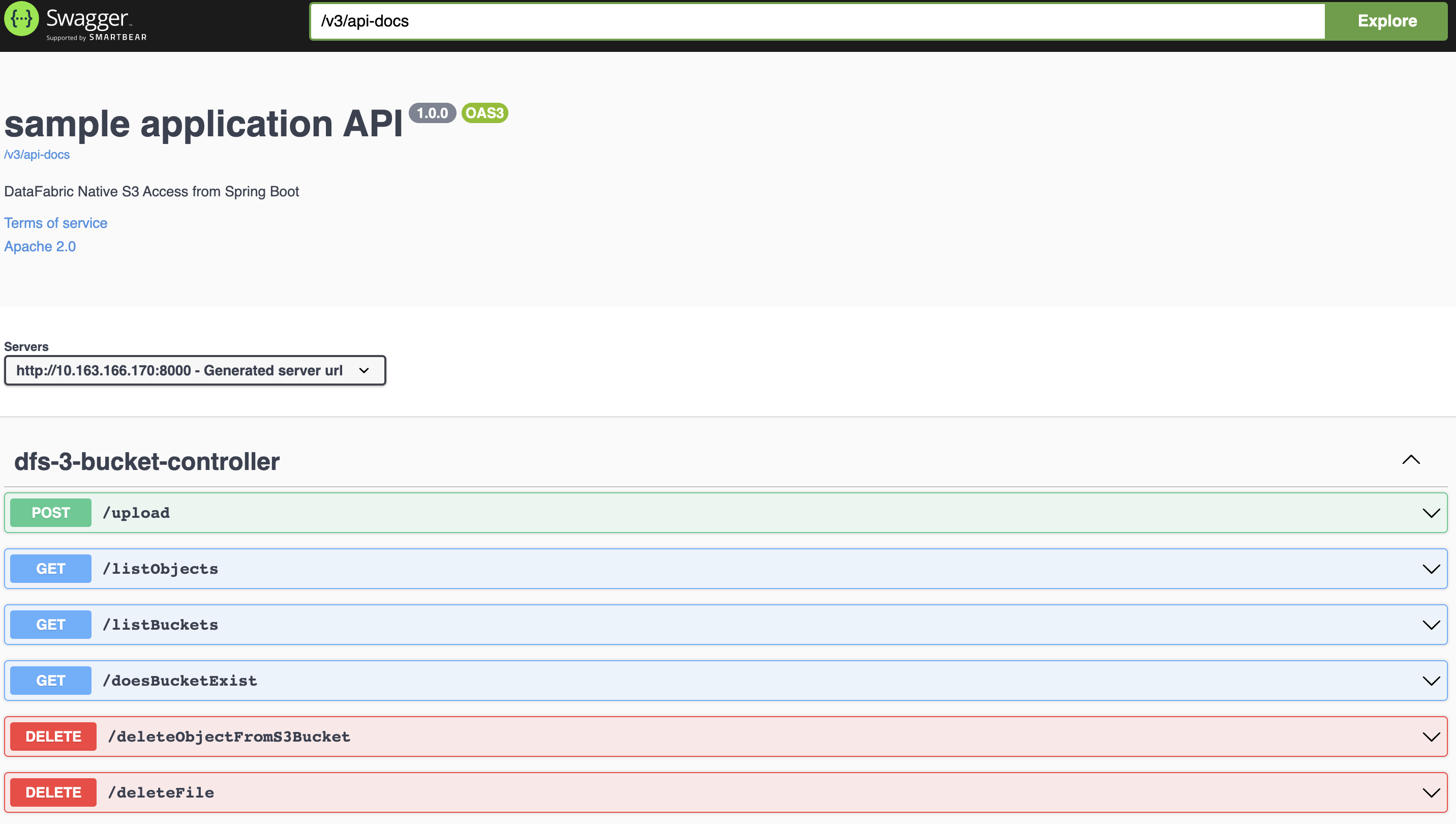
Accessing the Swagger UI from the pod
1. Connect to the pod http://pod-ip:8000/swagger-ui.html.
2. Verify the services exposed in the Swagger-UI.
In this blog post, you learned how data can be processed from edge to a persistence store by creating a data pipeline using a different technology stack. The aforementioned data pipeline is not limited to this current use case but can be used in many diversified microservice use cases.
Tags
Related
3 ways a data fabric enables a data-first approach
Mar 15, 2022A Functional Approach to Logging in Apache Spark
Feb 5, 2021