Kubernetes, Kafka Event Sourcing Architecture Patterns and Use Case Examples
November 11, 2020Editor’s Note: MapR products and solutions sold prior to the acquisition of such assets by Hewlett Packard Enterprise Company in 2019, may have older product names and model numbers that differ from current solutions. For information about current offerings, which are now part of HPE Ezmeral Data Fabric, please visit https://www.hpe.com/us/en/software/data-fabric.html
Original Post Information:
"authorDisplayName": "Carol McDonald",
"publish": "2018-05-01T11:00:00.000",
"tags": "use-cases"With the rapidly changing business and technology landscape of today, developers, data scientists, and IT operations are working together to build intelligent applications with new technologies and dynamic architectures because of the flexibility, speed of delivery, and maintainability that they make possible. This post will go over the technologies that are facilitating evolutionary architectures: containers, Kubernetes, and the Kafka API. Then we will look at some Kafka event sourcing architecture patterns and use case examples.

Containers Architecture
Containers simplify going from development to deployment, without having to worry about portability or reproducibility. Developers can package an application plus all its dependencies, libraries, and configuration files needed to execute the application into a container image. A container is a runnable instance of an image. Container images can be pulled from a registry and deployed anywhere the container runtime is installed: your laptop, servers on-premises, or in the cloud.

image reference https://docs.docker.com/engine/docker-overview/#docker-architecture
Compared to virtual machines, containers have similar resources and isolation benefits, but are lighter in weight, because containers virtualize the operating system instead of the hardware. Containers are more portable and efficient, take up less space, use far fewer system resources, and can be spun up in seconds.

Kubernetes Architecture
Kubernetes provides a platform to configure, automate, and manage:
- intelligent and balanced scheduling of containers
- creation, deletion, and movement of containers
- easy scaling of containers
- monitoring and self-healing abilities
A Kubernetes cluster is comprised of at least one master node, which manages the cluster, and multiple worker nodes, where containerized applications run using Pods. A Pod is a logical grouping of one or more containers, which are scheduled together and share resources. Pods enable multiple containers to run on a host machine and share resources, such as: storage, networking, and container runtime information.

The Master node manages the cluster in this way:
- The API server parses the YAML configuration and stores the configuration in the etcd key value store.
- The etcd stores and replicates the current configuration and run state of the cluster.
- The scheduler schedules pods on worker nodes.
- The controller manager manages the state of non-terminating control loops, such as pod replicas.
The microservice architectural style is an approach to developing an application as a suite of small independently deployable services built around specific business capabilities. A microservice approach is well aligned to containers and Kubernetes. You can gain modularity, extensive parallelism, and cost-effective scaling by deploying services across many nodes. Microservices modularity facilitates independent updates/deployments and helps to avoid single points of failure, which can help prevent large-scale outages.
The MapR Data Fabric includes a natively integrated Kubernetes volume driver to provide persistent storage volumes for access to any data located on-premises, across clouds, and to the edge. Stateful applications can now be easily deployed in containers for production use cases, machine learning pipelines, and multi-tenant use cases.

Event-Driven Microservices Architecture
Most business data is produced as a sequence of events, or an event stream: for example, web or mobile app interactions, sensor data, bank transactions, and medical devices all continuously generate events. Microservices often have an event-driven architecture, using an append-only event stream, such as Kafka or MapR Event Streams (which provides a Kafka API).

With MapR Event Store (or Kafka), events are grouped into logical collections of events called "topics." Topics are partitioned for parallel processing. You can think of a partitioned topic like an event log, new events are appended to the end, and like a queue,events are delivered in the order they are received.


Unlike a queue, events are not deleted after they are delivered, they remain on the partition, available to other consumers.

Older messages are automatically deleted, based on the stream's timetolive setting; if the setting is 0, then they will never be deleted.

Messages are not deleted from topics when read, and topics can have multiple different consumers; this allows processing of the same messages by different consumers for different purposes. Pipelining is also possible, where a consumer enriches an event and publishes it to another topic.

MapR Event Store provides scalable high performance messaging, easily delivering millions of messages per second on modest hardware. The publish/subscribe Kafka API provides decoupled communications, making it easy to add new listeners or new publishers without disrupting existing processes.
When you combine these messaging capabilities with the simple concept of microservices, you can greatly enhance the agility with which you build, deploy, and maintain complex data pipelines. Pipelines are constructed by simply chaining together multiple microservices, each of which listens for the arrival of some data, performs its designated task, and optionally publishes its own messages to a topic.
The Stream Is the System of Record
Event Sourcing is an architectural pattern in which the state of the application is determined by a sequence of events, each of which is recorded in an append-only event store or stream. As an example, imagine that each "event" is an incremental update to an entry in a database. In this case, the state of a particular entry is simply the accumulation of events pertaining to that entry. In the example below, the stream persists the queue of all deposit and withdrawal events, and the database table persists the current account balances.

Which one of these, the stream or the database, makes a better system of record? The events in the stream can be used to reconstruct the current account balances in the database, but not the other way around. Database replication actually works by suppliers writing changes to a change log, and consumers applying the changes locally.
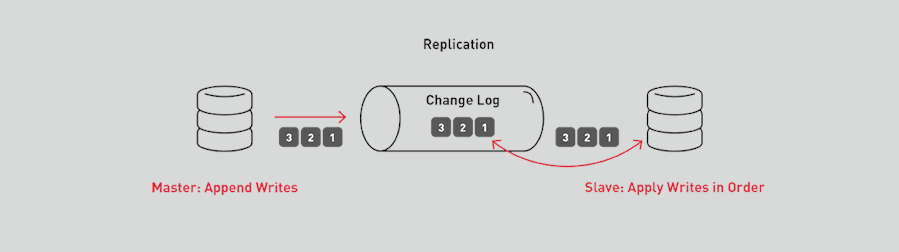
Adding Microservices to a Bank Monolithic Application with Change Data Capture
Banks often have mainframe applications, which are expensive to run, difficult to update, and also difficult to completely replace. Let's look at how we could incrementally add event-driven microservices to a monolithic bank application, which consists of payment transactions and batch jobs for fraud detection, statements, and promotion emails.
In the design shown below, payment transactions from the monolithic database commit log are published to a stream, which is set to never throw data away. The immutable event store (stream) becomes the system of record, with events processed by different data pipelines, based on the use case. Event data pipelines funnel out to polyglot persistence, different data storage technologies, each one providing different materialized views: MapR Database HBase and MapR Database JSON document, graph, and search databases, so that microservices always have the most up-to-date view of their data in the most appropriate format. Using a different model for reading than for writing is the Command Query Responsibility Separation pattern.

The event store provides for rebuilding state by re-running the events in the stream — this is the Event Sourcing pattern. Events can be reprocessed to create a new index, cache, or view of the data.

The consumer simply reads from the oldest message to the latest to create a new view of the data.

With the payment transactions now coming in as an event stream, real time fraud detection, using Spark Machine Learning and Streaming, could be added more easily than before, as shown in the data flow below:

Having a long retention time for events in the stream allows for more analysis and functionality to be added. For example, a materialized view of card location histories could be stored in a data format such as Parquet, which provides very efficient querying.
Evolving the Architecture by Adding Events and Microservices
With more event sources, stream processing and machine learning can be added to provide new functionality. Machine learning techniques across a wide range of interactions — including click stream, click through rates, call center reports, customer preferences, and purchase data — can be used to provide insights, such as: financial recommendations, predictions, alerts, and relevant offers. For example, web click stream analysis combined with purchase history can be used to segment customers who share behavioral affinities into groups, in order to better target advertisements. Lead events can be added to a stream when a customer clicks on targeted offers, triggering updates to the customer profile in MapR Database and automated campaigns to prospects.

Healthcare Event Sourcing Examples
Now let's look at how a stream-first architecture has been implemented in healthcare. Data from hospitals, providers, and labs flow into the ALLOY Health Platform. MapR Event Store solves the data lineage problem of HIPAA compliance because the stream becomes a system of record by being an infinite, immutable log of each data change. Polyglot persistence solves the problem of storing multiple data formats. By streaming data changes in real time to the MapR Database HBase API/MapR Database JSON API, graph, and search databases, materialized views can be provided, explored, and analyzed for different use cases, such as population health queries and patient matching.

Other healthcare stream processing and machine learning data pipeline examples include:
- Using predictive analytics on claims events to reduce fraud waste and abuse for healthcare payments.
- Using predictive analytics across multiple sources from over 30 million patients to:
- provide doctors with timely, actionable intelligence to aid in the accuracy of diagnosing patient conditions
- aid in the matching of treatments with outcomes
- predict patients at risk for disease or readmission
Retail Event Sourcing Example
A major retailer wanted to increase in-season agility and inventory discipline in order to react to demand changes and reduce markdowns.
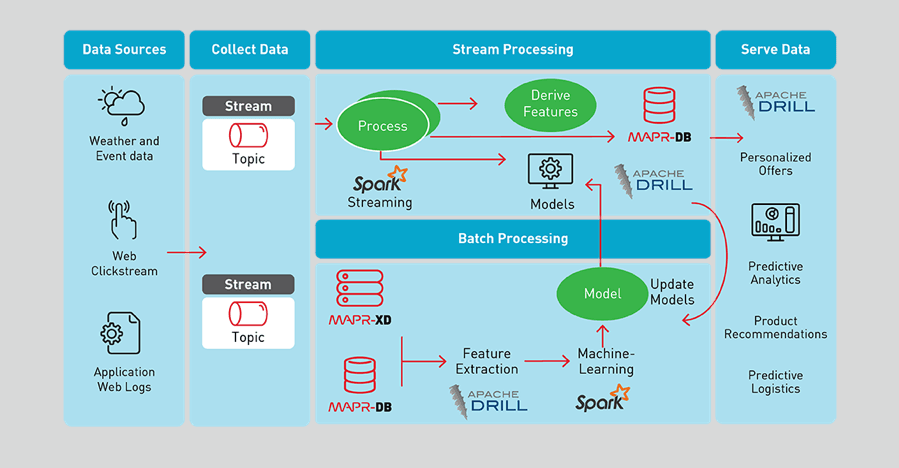
Data is collected from point of sale transactions, inventory status and pricing, competitive intelligence, social media, weather, and customers (scrubbed of personal identification), allowing for a centralized analysis of correlations and patterns that are relevant to improving business. Big data algorithms analyze in-store and online purchases, Twitter trends, local sports events, and weather buying patterns to build innovative applications that personalize customer experience while increasing the efficiency of logistics. Point of sale transactions are analyzed to provide product recommendations or discounts based on which products were bought together or before another product. Predictive analytics is used to know what products sell more on particular days in certain kinds of stores, in order to reduce overstock and stay properly stocked on the most in-demand products, thereby helping to optimize the supply chain.
Conclusion
A confluence of several different technology shifts have dramatically changed the way that applications are being built. The combination of event-driven microservices, containers, Kubernetes, and machine learning data pipelines is accelerating the development of next-generation intelligent applications, which are taking advantage of modern computational paradigms, powered by modern computational infrastructure. The MapR Data Platform integrates global event streaming, real-time database capabilities, and scalable enterprise storage with a collection of data processing and analytical engines to power this new generation of data processing pipelines and intelligent applications.

Related
3 ways a data fabric enables a data-first approach
Mar 15, 2022A Functional Approach to Logging in Apache Spark
Feb 5, 2021
Getting Started with DataTaps in Kubernetes Pods
Jul 6, 2021