Original post information:
"authorDisplayName": "Carol McDonald",
"publish": "2018-10-17T08:00:00.000Z",
"tags": "spark"
In this blog post, we will give an introduction to Apache Spark and its history and explore some of the areas in which its particular set of capabilities show the most promise. We will discuss the relationship to other key technologies and provide some helpful pointers.
With Spark 2.0 and later versions, big improvements were implemented to make Spark easier to program and execute faster.
What Is Apache Spark?
Spark is a general-purpose distributed data processing engine that is suitable for use in a wide range of circumstances. On top of the Spark core data processing engine, there are libraries for SQL, machine learning, graph computation, and stream processing, which can be used together in an application. Programming languages supported by Spark include: Java, Python, Scala, and R. Application developers and data scientists incorporate Spark into their applications to rapidly query, analyze, and transform data at scale. Tasks most frequently associated with Spark include ETL and SQL batch jobs across large data sets, processing of streaming data from sensors, IoT, or financial systems, and machine learning tasks.

History
In order to understand Spark, it helps to understand its history. Before Spark, there was MapReduce, a resilient distributed processing framework, which enabled Google to index the exploding volume of content on the web, across large clusters of commodity servers. 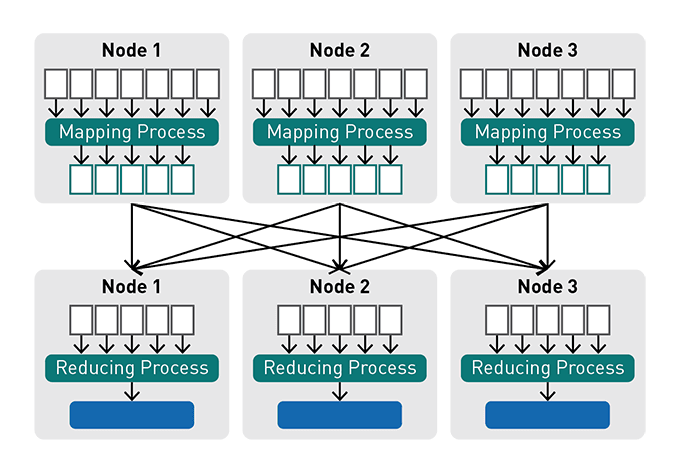
There were 3 core concepts to the Google strategy:
Distribute data: when a data file is uploaded into the cluster, it is split into chunks, called data blocks, and distributed amongst the data nodes and replicated across the cluster.
Distribute computation: users specify a map function that processes a key/value pair to generate a set of intermediate key/value pairs and a reduce function that merges all intermediate values associated with the same intermediate key. Programs written in this functional style are automatically parallelized and executed on a large cluster of commodity machines in the following way:
- The mapping process runs on each assigned data node, working only on its block of data from a distributed file.
- The results from the mapping processes are sent to the reducers in a process called "shuffle and sort": key/value pairs from the mappers are sorted by key, partitioned by the number of reducers, and then sent across the network and written to key sorted "sequence files" on the reducer nodes.
- The reducer process executes on its assigned node and works only on its subset of the data (its sequence file). The output from the reducer process is written to an output file.
Tolerate faults: both data and computation can tolerate failures by failing over to another node for data or processing.
MapReduce word count execution example:

Some iterative algorithms, like PageRank, which Google used to rank websites in their search engine results, require chaining multiple MapReduce jobs together, which causes a lot of reading and writing to disk. When multiple MapReduce jobs are chained together, for each MapReduce job, data is read from a distributed file block into a map process, written to and read from a SequenceFile in between, and then written to an output file from a reducer process.

A year after Google published a white paper describing the MapReduce framework (2004), Doug Cutting and Mike Cafarella created Apache Hadoop™.
Apache Spark™ began life in 2009 as a project within the AMPLab at the University of California, Berkeley. Spark became an incubated project of the Apache Software Foundation in 2013, and it was promoted early in 2014 to become one of the Foundation’s top-level projects. Spark is currently one of the most active projects managed by the Foundation, and the community that has grown up around the project includes both prolific individual contributors and well-funded corporate backers, such as Databricks, IBM, and China’s Huawei.
The goal of the Spark project was to keep the benefits of MapReduce’s scalable, distributed, fault-tolerant processing framework, while making it more efficient and easier to use. The advantages of Spark over MapReduce are:
- Spark executes much faster by caching data in memory across multiple parallel operations, whereas MapReduce involves more reading and writing from disk.
- Spark runs multi-threaded tasks inside of JVM processes, whereas MapReduce runs as heavier weight JVM processes. This gives Spark faster startup, better parallelism, and better CPU utilization.
- Spark provides a richer functional programming model than MapReduce.
- Spark is especially useful for parallel processing of distributed data with iterative algorithms.
How a Spark Application Runs on a Cluster
The diagram below shows a Spark application running on a cluster.
- A Spark application runs as independent processes, coordinated by the SparkSession object in the driver program.
- The resource or cluster manager assigns tasks to workers, one task per partition.
- A task applies its unit of work to the dataset in its partition and outputs a new partition dataset. Because iterative algorithms apply operations repeatedly to data, they benefit from caching datasets across iterations.
- Results are sent back to the driver application or can be saved to disk.

Spark supports the following resource/cluster managers:
- Spark Standalone – a simple cluster manager included with Spark
- Apache Mesos – a general cluster manager that can also run Hadoop applications
- Apache Hadoop YARN – the resource manager in Hadoop 2
- Kubernetes – an open source system for automating deployment, scaling, and management of containerized applications
Spark also has a local mode, where the driver and executors run as threads on your computer instead of a cluster, which is useful for developing your applications from a personal computer.
What Does Spark Do?
Spark is capable of handling several petabytes of data at a time, distributed across a cluster of thousands of cooperating physical or virtual servers. It has an extensive set of developer libraries and APIs and supports languages such as Java, Python, R, and Scala; its flexibility makes it well-suited for a range of use cases. Spark is often used with distributed data stores such as HPE Ezmeral Data Fabric, Hadoop’s HDFS, and Amazon’s S3, with popular NoSQL databases such as HPE Ezmeral Data Fabric, Apache HBase, Apache Cassandra, and MongoDB, and with distributed messaging stores such as HPE Ezmeral Data Fabric and Apache Kafka.
Typical use cases include:
Stream processing: From log files to sensor data, application developers are increasingly having to cope with "streams" of data. This data arrives in a steady stream, often from multiple sources simultaneously. While it is certainly feasible to store these data streams on disk and analyze them retrospectively, it can sometimes be sensible or important to process and act upon the data as it arrives. Streams of data related to financial transactions, for example, can be processed in real time to identify– and refuse– potentially fraudulent transactions.
Machine learning: As data volumes grow, machine learning approaches become more feasible and increasingly accurate. Software can be trained to identify and act upon triggers within well-understood data sets before applying the same solutions to new and unknown data. Spark’s ability to store data in memory and rapidly run repeated queries makes it a good choice for training machine learning algorithms. Running broadly similar queries again and again, at scale, significantly reduces the time required to go through a set of possible solutions in order to find the most efficient algorithms.
Interactive analytics: Rather than running pre-defined queries to create static dashboards of sales or production line productivity or stock prices, business analysts and data scientists want to explore their data by asking a question, viewing the result, and then either altering the initial question slightly or drilling deeper into results. This interactive query process requires systems such as Spark that are able to respond and adapt quickly.
Data integration: Data produced by different systems across a business is rarely clean or consistent enough to simply and easily be combined for reporting or analysis. Extract, transform, and load (ETL) processes are often used to pull data from different systems, clean and standardize it, and then load it into a separate system for analysis. Spark (and Hadoop) are increasingly being used to reduce the cost and time required for this ETL process.
Who Uses Spark?
A wide range of technology vendors have been quick to support Spark, recognizing the opportunity to extend their existing big data products into areas where Spark delivers real value, such as interactive querying and machine learning. Well-known companies such as IBM and Huawei have invested significant sums in the technology, and a growing number of startups are building businesses that depend in whole or in part upon Spark. For example, in 2013 the Berkeley team responsible for creating Spark founded Databricks, which provides a hosted end-to-end data platform powered by Spark. The company is well-funded, having received $247 million across four rounds of investment in 2013, 2014, 2016 and 2017, and Databricks employees continue to play a prominent role in improving and extending the open source code of the Apache Spark project.
The major Hadoop vendors, including MapR, Cloudera, and Hortonworks, have all moved to support YARN-based Spark alongside their existing products, and each vendor is working to add value for its customers. Elsewhere, IBM, Huawei, and others have all made significant investments in Apache Spark, integrating it into their own products and contributing enhancements and extensions back to the Apache project. Web-based companies, like Chinese search engine Baidu, e-commerce operation Taobao, and social networking company Tencent, all run Spark-based operations at scale, with Tencent’s 800 million active users reportedly generating over 700 TB of data per day for processing on a cluster of more than 8,000 compute nodes.
In addition to those web-based giants, pharmaceutical company Novartis depends upon Spark to reduce the time required to get modeling data into the hands of researchers, while ensuring that ethical and contractual safeguards are maintained.
What Sets Spark Apart?
There are many reasons to choose Spark, but the following three are key:
Simplicity: Spark’s capabilities are accessible via a set of rich APIs, all designed specifically for interacting quickly and easily with data at scale. These APIs are well-documented and structured in a way that makes it straightforward for data scientists and application developers to quickly put Spark to work.
Speed: Spark is designed for speed, operating both in memory and on disk. Using Spark, a team from Databricks tied for first place with a team from the University of California, San Diego, in the 2014 Daytona GraySort benchmarking challenge (https://spark.apache.org/news/spark-wins-daytona-gray-sort-100tb-benchmark.html). The challenge involves processing a static data set; the Databricks team was able to process 100 terabytes of data stored on solid-state drives in just 23 minutes, and the previous winner took 72 minutes by using Hadoop and a different cluster configuration. Spark can perform even better when supporting interactive queries of data stored in memory. In those situations, there are claims that Spark can be 100 times faster than Hadoop’s MapReduce.
Support: Spark supports a range of programming languages, including Java, Python, R, and Scala. Spark includes support for tight integration with a number of leading storage solutions in the Hadoop ecosystem and beyond, including HPE Ezmeral Data Fabric (file system, database, and event store), Apache Hadoop (HDFS), Apache HBase, and Apache Cassandra. Furthermore, the Apache Spark community is large, active, and international. A growing set of commercial providers, including Databricks, IBM, and all of the main Hadoop vendors, deliver comprehensive support for Spark-based solutions.
The Power of Data Pipelines
Much of Spark's power lies in its ability to combine very different techniques and processes together into a single, coherent whole. Outside Spark, the discrete tasks of selecting data, transforming that data in various ways, and analyzing the transformed results might easily require a series of separate processing frameworks, such as Apache Oozie. Spark, on the other hand, offers the ability to combine these together, crossing boundaries between batch, streaming, and interactive workflows in ways that make the user more productive.
Spark jobs perform multiple operations consecutively, in memory, and only spilling to disk when required by memory limitations. Spark simplifies the management of these disparate processes, offering an integrated whole – a data pipeline that is easier to configure, easier to run, and easier to maintain. In use cases such as ETL, these pipelines can become extremely rich and complex, combining large numbers of inputs and a wide range of processing steps into a unified whole that consistently delivers the desired result.
Related
A Functional Approach to Logging in Apache Spark
Feb 5, 2021